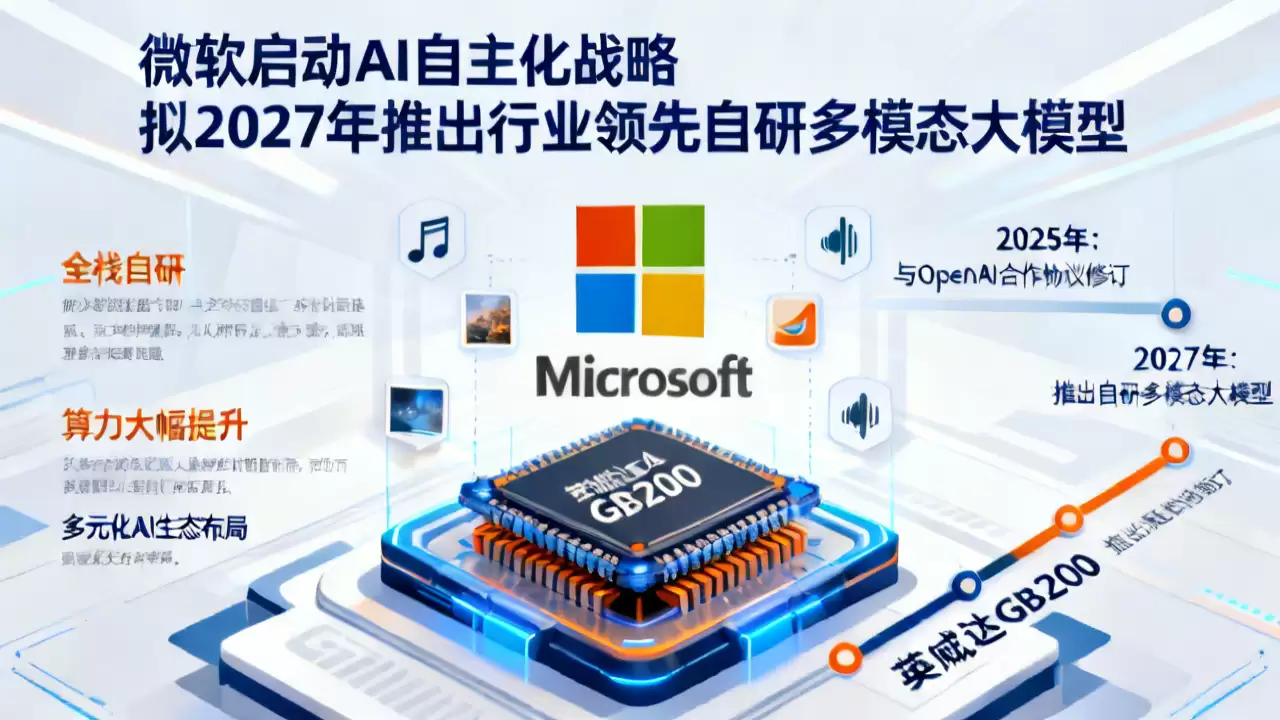
微软AI战略转向:告别“外包”,启动自研大模型军备竞赛
最近曝光的2026年4月规划文件,透露了一个明确的信号:微软正在全力推进一场深度的AI自主化战略转型。其核心目标直指2027年,届时,一款由微软完全自研的尖端多模态大模型将正式亮相,目标是在文本、图像、音频的综合处理能力上达到行业顶尖水平,直接与OpenAI、Anthropic这些当前的头部玩家展开正面竞争。为确保这一野心勃勃的计划不沦为空中楼阁,微软已经启动了基于英伟达GB200芯片的庞大集群部署。可以预见,未来12到18个月内,其整体算力将迎来跨越式增长。当然,全面转向自主并不意味着闭门造车,微软方面已明确表态,将继续维持其AI生态的多元化格局。
这一战略急转弯的关键催化剂,是2025年微软与OpenAI那份合作协议的重新修订。要知道,在此之前,微软长期扮演着OpenAI最大投资方的角色,其策略本质是“以资本换取技术授权”,并以此为基础构建了从Office到Bing的整个AI产品矩阵。而新版协议,则像一把钥匙,为微软解开了技术开发上的诸多束缚,为其铺平了启动全栈自研模型的道路。
从这份自研计划不难看出,微软的AI战略路径已经发生了根本性转变——从过去的“依赖外部技术供给”,坚定地迈向“自主掌握核心能力”。按照内部设定的时间表,微软要在3到5年内实现AI技术栈的全面自主可控。而那个关键的2027年,就是检验成果的里程碑。届时推出的自研大模型,被寄望于在文本生成、多模态理解乃至复杂的逻辑推理性能等多个维度上,全面超越当时的行业标杆,真正具备与最顶尖模型一较高下的实力。
话说回来,启动自研是否意味着微软将对外部技术关上大门?答案是否定的。相关负责人已经澄清,未来的Azure云平台,依然会是一个开放的技术集市,继续支持各类开源模型和第三方商用模型。其目的很明确:为用户提供丰富、多层次的选择,而不是单一答案。
算力军备:一场没有硝烟的战争
大模型的竞争,归根结底是算力的竞争。为了给自研模型的训练提供充足的“弹药”,微软已经悄然打响了一场算力军备竞赛。目前,批量部署英伟达GB200超级芯片集群的工作已经展开。根据规划,在接下来的12至18个月里,微软全球数据中心的AI总算力将实现数倍的增长。这个规模,足以从容支撑起万亿参数级别的多模态大模型,完成从训练到迭代的全生命周期需求。
行业内部做过测算,单就AI训练性能而言,一块GB200芯片相比前代的H100,提升幅度超过了3倍。而微软此次部署的集群规模,达到了惊人的十万片级别。这意味着,其构筑的整体算力底座,将稳稳位居全球最前列的阵营。
打破依赖与重塑格局
回顾过去几年,微软的AI产品线,从Office Copilot到Bing搜索的智能功能,其核心引擎几乎都来自OpenAI的GPT系列。这种深度依赖,在带来快速产品化的同时,也隐藏着潜在的风险与成本。一旦自研模型成功落地,微软将彻底摆脱这条“外部供给线”。不仅能根据自家产品(如Windows、Office套件)的特性进行深度定制与优化,更能大幅削减高昂的技术授权成本,从而显著提升整体业务的盈利空间。
更重要的是,微软的亲自下场,无疑将重塑全球大模型赛道的竞争格局。背靠其在云计算、生产力软件乃至智能硬件领域建立的完整生态,其自研模型的落地速度和场景渗透广度,绝非一般的AI创业公司可以比拟。可以预见,未来的全球多模态大模型市场,很可能形成微软、OpenAI、谷歌、Anthropic四强并立的稳态结构。这种高强度的竞争,对于加速技术迭代和推动AI能力普惠化,无疑是一剂强心针。