代码、Agent,还有呢?
在AI模型的竞技场上,代码能力向来是兵家必争之地,原因无他——这是最容易标准化评估的硬核指标之一。
从K2到K2.5,再到如今的K2.6,Kimi保持着平均一个季度左右的迭代节奏。值得注意的是,这次版本号只是“点六”的小幅升级,这或许暗示着,团队手中还握有更重要的底牌。
那么,K2.6到底带来了什么?官方传播材料给出了明确答案:其长程编码能力获得了显著提升。在测试中,它能不间断编码13小时,编写或修改超过4000行代码。更关键的是,在Kimi内部那个涵盖了多种复杂端到端任务的严格评测基准——Kimi Code Bench上,K2.6的成绩比前代提升了约20%。
要知道,K2.5本身已经是个“能打”的选手,今年2月曾在OpenRouter榜单上霸榜。一位接近Kimi的知情人士曾贴出联合创始人张宇韬当时的朋友圈截图,字里行间透着对这个版本的满意。

通用Agent、编程和视觉Agent基准测试上,K2.6的表现
除了代码,Agent能力是另一个焦点。对于OpenClaw、Hermes这类主流Agent框架,K2.6的核心优化集中在两点:一是提升API调用的精准性,二是增强长时间运行的稳定性。前者关乎任务执行的成本,后者则直接影响任务执行的效率。
其实,Agent能力的进化在K2.5就已埋下伏笔。当时Kimi提出了“Agent集群”的概念,其思路是将一项复杂任务拆解成多个子项,自动分配给不同专长的Agent并行处理。这样做的好处显而易见:既能缩短整体处理时间,又能避免传统串行流程中,一个环节出错导致全盘崩溃的风险。
Kimi K2.6的Agent集群能力演示
到了K2.6,这个能力被进一步放大。新版本将广度搜索与深度调研、大规模文档分析与长篇撰写,以及多格式内容生成等功能进行了集成与并行化处理。其系统最多可支持300个子Agent协同工作,完成高达4000个协作步骤。
如果要用一句话概括K2.6的亮点,大致可以总结为:代码与长程任务能力进化、Agent集群能力增强,以及对主流Agent框架的适配优化。
若要在这些特性中挑出一个最具潜力的,Agent集群无疑值得重点关注。它直接将并行计算的爆炸性能力具象化了。毕竟,代码能力和任务稳定性的提升,是模型迭代的“必修课”。而在此基础之上,推动Agent工作方式、效率乃至交互范式的创新,才是真正改变生产力的关键。对用户而言,重要的不是模型“能做什么”的承诺,而是它能否驱动Agent实实在在地解决问题。
回顾K2.5上线时,就已有学界研究员将其用作科研助手,评价是“没有短板”。更有用户反馈称:“最新提供的多Agent确实有效,去年国产的Agent很多还只是玩具。”既然前代口碑已然不俗,那么在此基础上更进一步的K2.6,实际表现自然更令人期待。
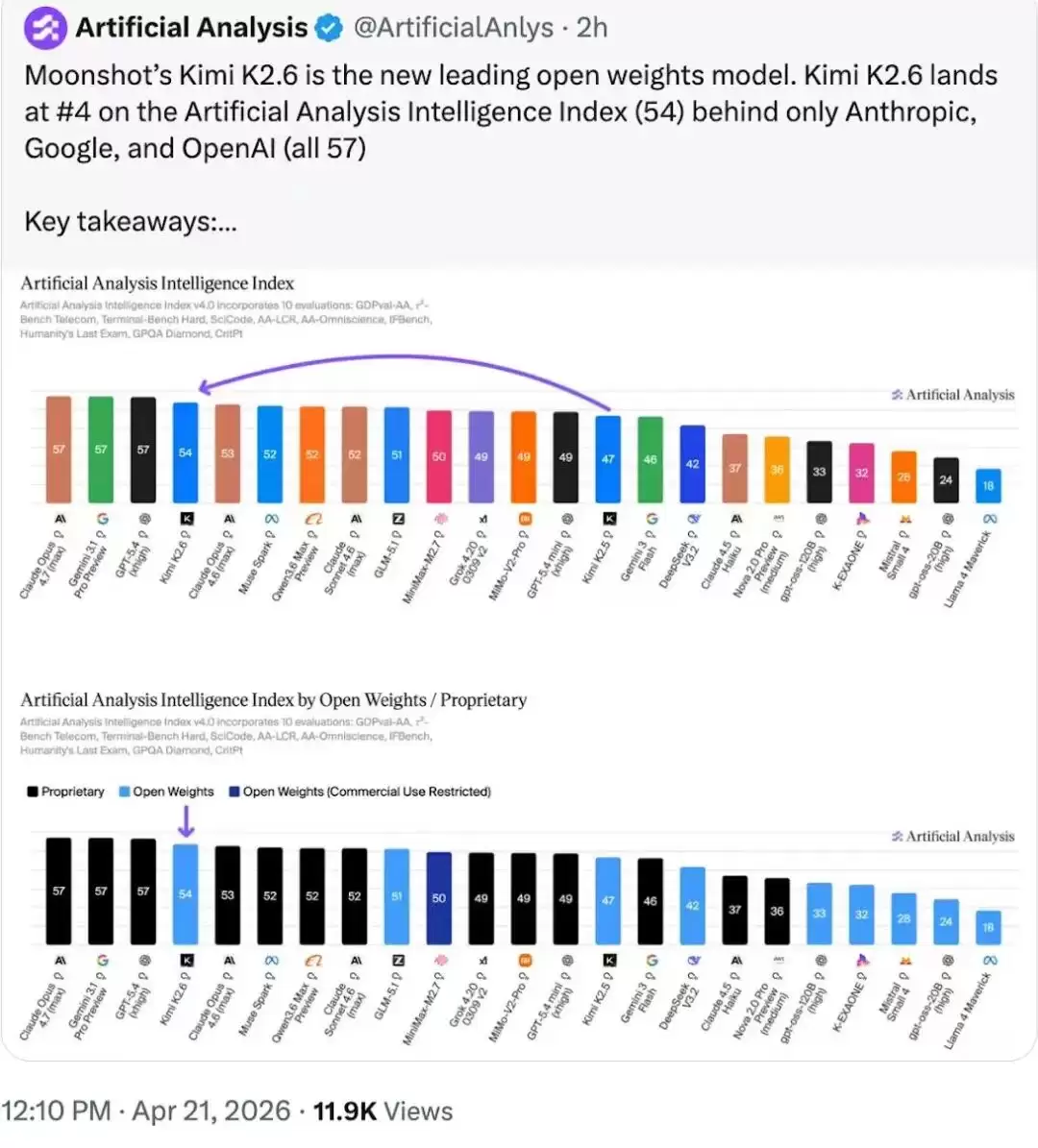
Artifacial Analysis智能榜单,Kimi K2.6仅次于三家闭源模型,并领跑开源模型权重榜单
路线图里的“新故事”
Kimi这家公司,总习惯给行业带来一些新思路。早在今年3月的GTC演讲中,杨植麟就勾勒了其技术路线图,其中提到的MuonClip二阶优化器、Kimi Linear架构以及Attention Residuals等技术,都旨在突破现有Scaling的瓶颈。这些探索甚至得到了行业顶流的认可——当Kimi发布关于Attention Residuals的论文时,马斯克直接在社交媒体上称赞这是“令人印象深刻的突破”。

上周末,Kimi再次发布一篇新论文《Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter》(预填充即服务,简称PrfaaS),将架构探索推向了一个新高度。论文核心讨论的,依然是PD分离(Prefill和Decode)这个经典命题。
PD分离并非新概念。模型推理的预填充阶段属于计算密集型任务,而解码阶段则更依赖显存带宽。将两者解耦,旨在提高算力利用率和系统吞吐量,最终实现降本增效。然而,这个架构有个关键卡点:它通常依赖于同机房内的RDMA高速网络。
Kimi这篇论文的创新之处在于,它基于其混合模型架构大幅缩减了KV缓存的体积,从而使得Prefill和Decode能够被彻底解耦到不同的、甚至异构的硬件集群中去。论文中展示的实验示例颇具说服力:专用预填充集群使用32张算力强劲的H200,而本地解码集群则使用64张通过RDMA互联的H20 GPU,两组集群通过VPC专线连接。实测结果显示,这种跨数据中心的方案,相比传统的同集群方案,吞吐量提升了54%,关键的用户响应延迟指标则大幅降低了64%。
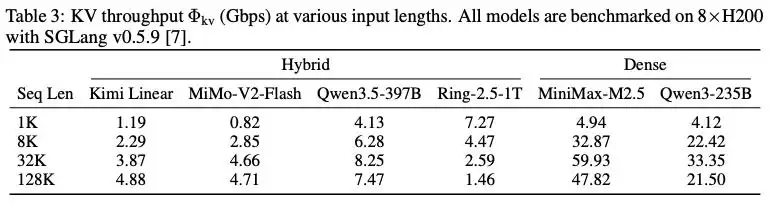
不同上下文长度下,混合架构模型与稠密模型KV吞吐量对比
为了证明混合模型架构的带宽优势,论文还提供了一组对比数据:在32K上下文长度下,采用混合注意力的模型,其KV缓存传输需求被压缩到仅需4.66Gbps,而同等规模的稠密注意力模型则高达59.93Gbps。这直接证明,混合架构能将传输需求压降到普通以太网即可承载的范围。
“跨数据中心+异构硬件,解锁显著降低单token成本的潜力。”Kimi官方账号如是总结。关于Token降本,这已是行业共识的攻坚方向。正如上海财经大学胡延平教授曾指出的,降本不能只依赖单一模型或单一路径,它取决于算力供给的成本效率、模型素质的跨代提升、智能范式的持续进阶等多重因素的共同作用。从这个角度看,Kimi的PrfaaS无疑为行业讲述了一个关于降本增效的新故事。
中国模型召唤中国芯片
在PrfaaS这篇论文中,多数人的目光被“跨数据中心”这个宏大叙事所吸引,却容易忽略其中同样关键的“异构硬件”这一点。
需要特别注意,论文中使用的H200和H20虽然性能侧重不同,但同属英伟达Hopper架构。这里提到的“异构”,主要指算力与带宽特性的差异。但其揭示的路径具有更广泛的启示意义:完全可以用一部分算力强的国产芯片来做Prefill,再用带宽优势明显的国产芯片来做Decode,当然,也可以与海外芯片混合使用,以实现最优的成本效益。
可以说,这是Kimi为中国芯片打开的一扇通往大模型推理场景的大门。
然而,机会背后总有挑战。在一位国产算力领域的业内人士看来,要接住预填充即服务模式带来的这波流量,依然绕不开“生态”这个老生常谈的难题。过去几年,中国大模型确实因生态问题,在国产算力适配上面临较高门槛。
但市场环境正在发生微妙而深刻的变化。一个不容忽视的细节是:像H20这样的产品,断供已近一年。这意味着,在推理芯片的选项上,短期内的选择其实非常有限。随着推理需求的持续暴涨,供给问题将变得比生态挑战更为紧迫和首要。中国大模型对国产算力的态度,正从过去的“可用可不用”,悄然转变为“不得不用”。也正是基于这种判断,业内已有诸多预测认为,即将发布的DeepSeek V4正在积极适配国产算力。
适配国产算力这条路,对任何一家国产模型厂商而言都异常艰难,但从长远战略来看,这又是一项不得不做的工程。一件不得不做的事情,总需要有一个起点。或许,DeepSeek V4会成为那个起点。
而现在,在DeepSeek V4尚未露面之际,Kimi已经通过自己的工程实践,为“中国模型+中国芯片”的产业合体,探索出了一条具体可行的技术路径。模型厂商已经率先伸出了橄榄枝,现在,问题交给了国产芯片创业公司。
还记得在《the Dwarkesh Podcast》的最新访谈中,当被问及对华芯片禁售的影响时,黄仁勋的反应吗?他说,芯片又不是铀浓缩,禁售阻挡不了中国芯片的进步,他们完全可以通过国产芯片的暴力堆叠来开发模型。
他为什么敢这么说?DeepSeek和Kimi的下一步行动,就是最标准的答案。




