不堆参数,原地「循环思考」16次:揭秘Claude Mythos核心架构
这听起来像是一个技术传奇。Anthropic严防死守的Claude Mythos模型架构,竟被一位22岁的年轻创业者成功“逆向工程”。

这并非内部资料泄露,也非员工跳槽所致。
而是初创公司CEO Kye Gomez,运用第一性原理思维,从零开始,一步步推导出了Claude Mythos的核心架构设计。
更令人瞩目的是,他将这个复现项目——命名为OpenMythos——进行了完全开源。


他的复现解析帖迅速吸引了近百万网友的关注,在整个AI社区引发了巨大震动。人们惊叹于Mythos架构背后设计的精妙与高效。


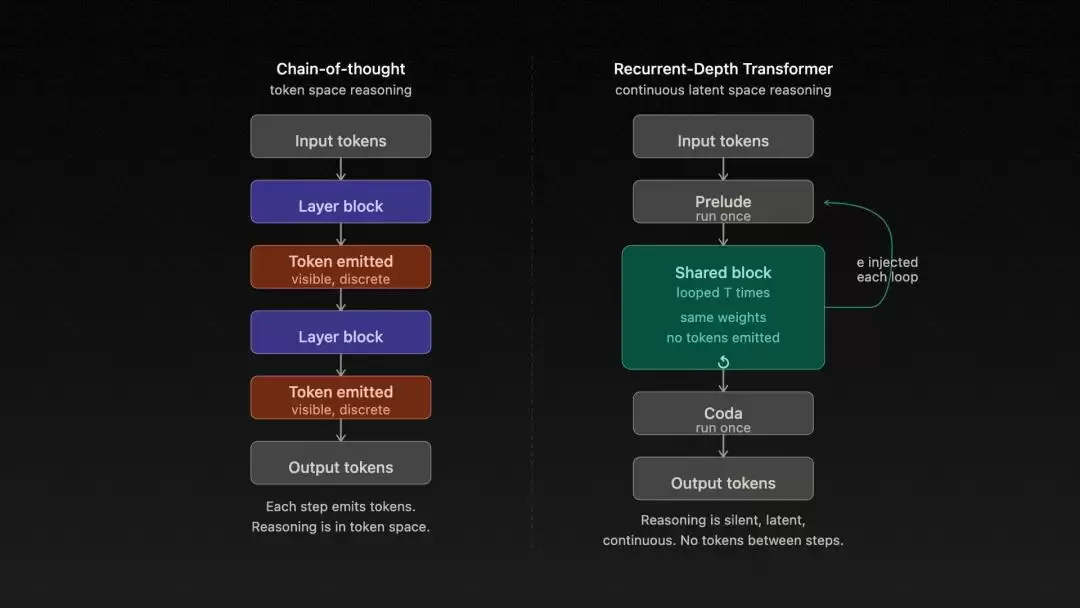
那么,核心发现是什么?Kye Gomez的研究揭示了一个关键结论:Claude Mythos的核心并非一个参数更庞大的Transformer,而是一种创新性的「循环深度Transformer」(Recurrent-Depth Transformer, RDT)架构。
简单来说,这种架构让同一套模型参数,在单次前向传播过程中,可以循环执行最多16次。
传统大语言模型的扩展思路类似于建造摩天大楼,通过不断堆叠参数层数来提升模型能力。100层不够就200层,200层不够就500层。参数越多,模型体积越庞大,对GPU显存的需求呈几何级数增长,训练成本也极其高昂。
但RDT架构彻底转变了思路:它不追求模型的物理“高度”,而是专注于“原地深度思考”。模型仅有一个核心计算模块,但这个模块会被反复调用和执行。每循环一次,模型的内部隐藏状态就更新和精炼一次,相当于模型“深入推理了一步”。其精妙之处在于,所有这些思考都在连续的潜在表示空间中进行,无需像传统的思维链(CoT)那样,每一步都必须生成可见的文本标记。
这绝非简单的重复计算,而是一种高效的、迭代式的深度推理过程。
架构全拆解:三段式设计解析
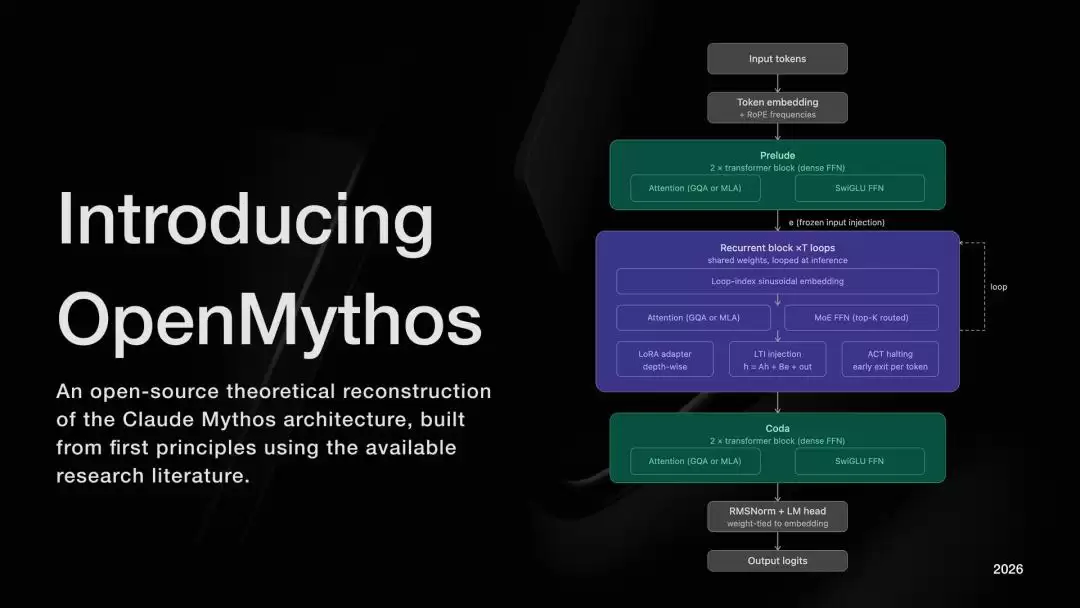
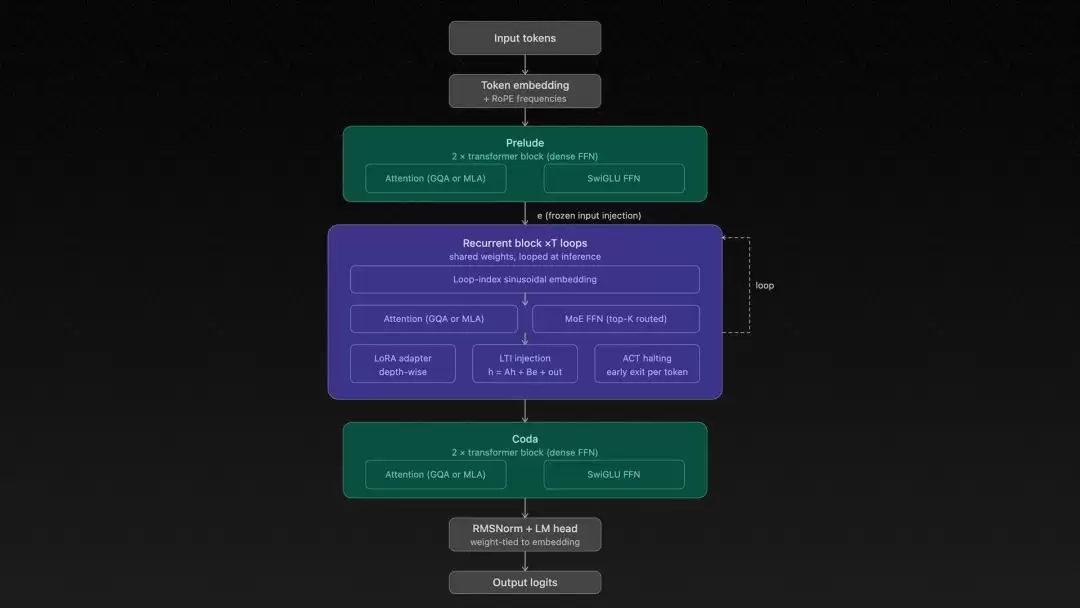
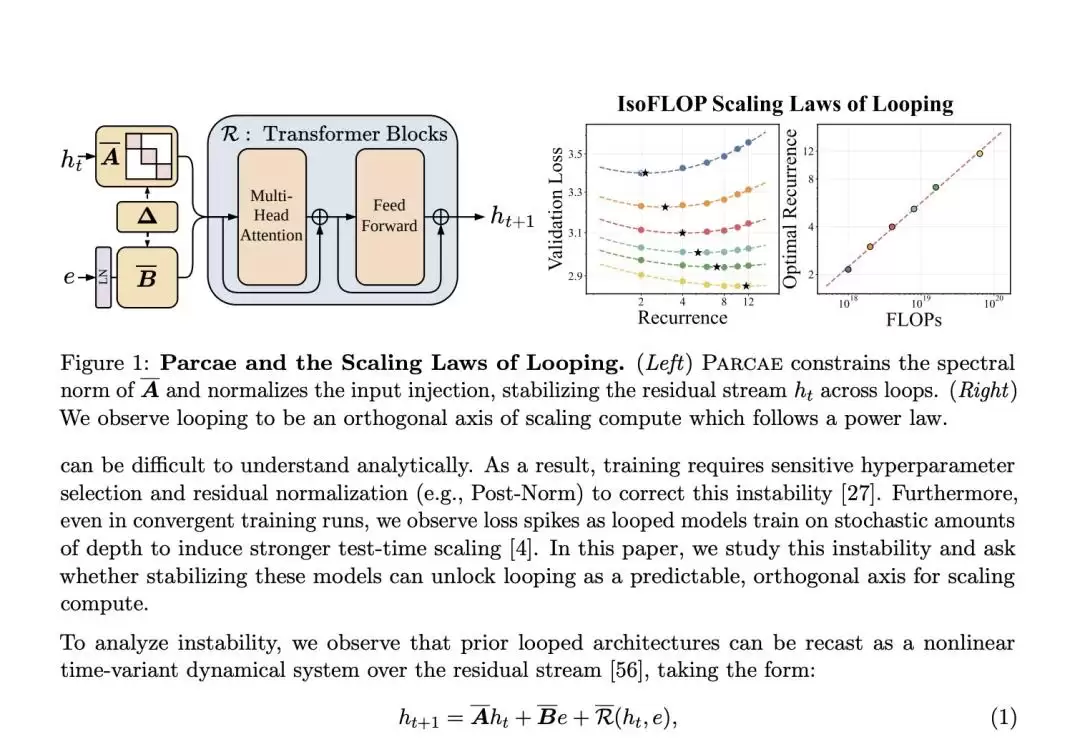
整个OpenMythos的架构可以被清晰地划分为三个阶段:Prelude(序曲)→ Recurrent Block(循环核心块)→ Coda(终章)。
其中,Prelude和Coda是标准的Transformer层,各执行一次。真正的计算核心是中间的「循环块」,它最多可循环16次。每次循环的状态更新规则可以表述为:
h_{t+1} = A·h_t + B·e + Transformer(h_t, e)
这里的e是经过Prelude层编码后的原始输入嵌入。在每一步循环中,原始输入信息都会被重新注入,这个设计至关重要,它能有效防止模型在漫长的循环迭代中“思维发散”或遗忘初始上下文。
MoE赋予广度,循环赋予深度
单一的循环机制可以解释Mythos强大的推理“深度”,但还不足以支撑其广博的知识面。OpenMythos在循环核心块的每个前馈网络(FFN)层,都创新性地替换成了混合专家(MoE)层,其设计参考了DeepSeek-MoE等先进思路:
使用大量细粒度的路由专家;每个输入标记仅激活其中一小部分最相关的专家;同时设置少量“共享专家”始终处于激活状态,负责处理跨领域的通用知识与能力。
最精妙的设计在于,随着隐藏状态h_t在循环中不断演化,路由机制在每一层、每一次循环深度上,都可能动态选择不同的专家子集。这意味着,虽然模型的基础权重是共享的,但每一次循环的计算路径和激活的专家可以完全不同。简而言之:MoE机制提供了海量知识的广度与可扩展性,而循环机制则赋予了模型迭代式、深度思考的能力。
项目开源地址:https://github.com/kyegomez/OpenMythos
在注意力机制方面,默认采用了来自DeepSeek-V2的「多潜变量注意力」(Multi-Latent Attention)。该技术通过将键值(KV)缓存压缩为低秩的潜在变量,在大规模生产推理中,据称能实现高达10-20倍的KV缓存显存节省,极大提升了效率。
此外,架构中还集成了三个关键机制来确保循环过程的稳定性与可控性:LTI约束注入(强制系统谱半径小于1以保证稳定性)、自适应计算时间(ACT)实现逐位置“动态停机”、以及深度级LoRA适配器让每次循环迭代都具备独立的微调与行为调整能力。整套设计精密而优雅。
770M参数媲美1.3B,参数效率直接翻倍
这种循环深度架构的优势并非停留在理论层面。此前,来自Parcae研究团队的实验数据已经证实:一个仅770M参数的循环模型,在同等训练数据规模下,其下游任务性能能够媲美1.3B参数的标准Transformer模型。
换句话说——仅用大约一半的参数量,就实现了同等级别的模型性能表现。
这对整个AI行业意味着什么?对于消费级硬件和广大开发者而言,这无疑是一个重大利好。过去,想要运行一个性能尚可的大模型,往往需要A100/H100级别的专业显卡,门槛极高。而现在,推理的“深度”可以通过计算时间(循环次数)来换取对显存“空间”(参数量)的依赖——你不再需要巨大的显存,只需要让模型“多思考几轮”。
更深远的影响在于,它可能正在悄然改写AI领域的扩展定律(Scaling Laws)。过去的竞争逻辑是比拼谁的参数更多、谁的GPU集群更庞大、谁的算力投入更惊人。而新的规则范式似乎正在浮现:未来最强大的AI模型,可能不是参数最多的,而是“思考”次数最多、推理最深、效率最高的那一个。
当然,需要客观指出的是,这目前更多是一种理论推演和早期实验的积极指向,其在大规模语言模型预训练和复杂任务上的实际成效,仍需进一步的实践与观察。
高中毕业即创业,22岁CEO的逆袭之路
这位成功揭秘Claude Mythos架构的22岁年轻人Kye Gomez,是AI初创公司Swarms的创始人,此前还曾领导过Agora Labs。他的研究兴趣重点聚焦于大规模多智能体系统、替代性模型架构创新以及多模态大模型。

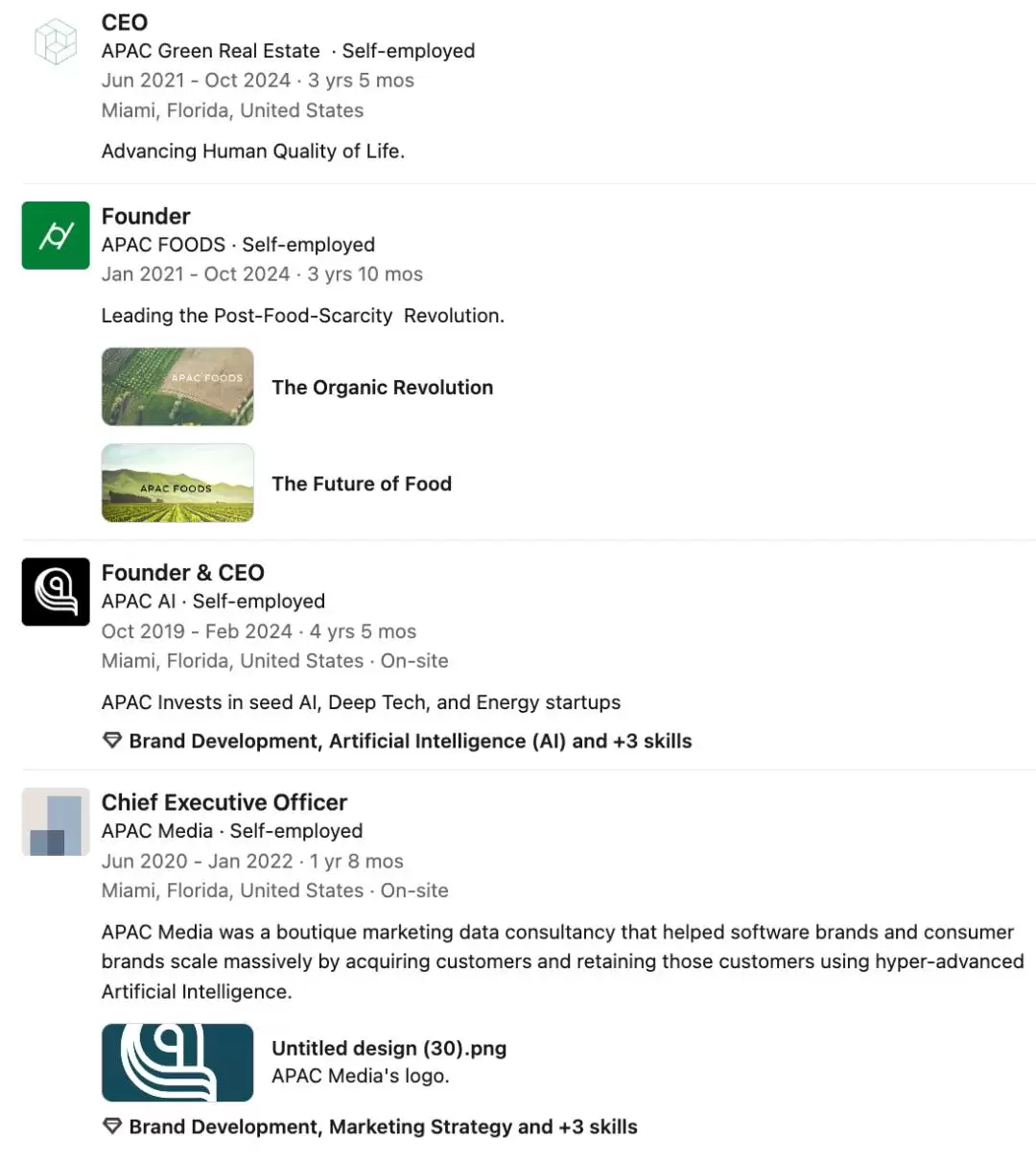
从其个人履历来看,Kye Gomez在高中毕业后便直接投身于科技创业的浪潮之中。

在2021年至2024年间,他同时担任了三家不同领域公司的联合创始人或CEO,并构建了一个以「APAC」为品牌的创新生态体系,业务触角延伸至人工智能深科技、数字媒体、食品科技等多个前沿赛道。
22岁天才开源Anthropic神级模型架构
整起事件最令人震撼的,或许并非架构本身有多么复杂难解。
而在于,一位22岁的创业者,仅凭借公开的学术论文和第一性原理的严谨推导,就将Anthropic雪藏近一年的核心技术黑箱成功复现,并且毅然选择了全面开源,使得任何开发者都能用几行代码尝试运行这一前沿架构。
这释放了一个强烈的行业信号:闭源AI实验室在核心模型架构上的技术优势窗口期,正在以肉眼可见的速度收窄。
英国《金融时报》的最新报道中,Anthropic的联合创始人Dario Amodei做出了一个重磅预测:中国AI团队将在12个月内,完全复刻出具备Claude Mythos级别能力的大语言模型。

针对外界关于大语言模型性能是否已触及天花板的质疑,Amodei用一句充满哲学意味的话作出了回应:“彩虹没有尽头,只有彩虹本身。”他强调,目前完全看不到AI技术发展放缓的迹象。
当一位独立研究者仅凭公开信息就能重建最核心的技术架构时,真正的行业护城河就不再仅仅是论文或蓝图了。未来的AI竞争,或许将更多转向高质量数据、工程化实现能力、产品生态与具体应用场景的落地。开源与开放的协作浪潮,正在深刻重塑全球人工智能领域的创新格局与发展节奏。




