Claude Opus 4.7全面上线:编程能力飞跃,但“升级”代价几何?
4月17日,Anthropic正式宣布其最新旗舰模型Claude Opus 4.7全面开放使用。与上一代的Opus 4.6相比,这次更新在高级软件工程领域带来了显著进步,同时多模态视觉能力也大幅增强,能够产出更高质量的界面设计、演示文稿等内容。
价格方面,Opus 4.7维持了与4.6相同的定价策略:每百万输入token收费5美元,每百万输出token收费25美元。然而,事情并非表面看起来那么简单。
Anthropic在官方公告中明确指出了一个关键变化:新的分词器会导致相同文本内容的token数量变为原来的1.0到1.35倍。在API单价不变的前提下,这意味着实际使用成本隐性地上涨了10%至35%。这无疑给开发者们的预算规划提了个醒。
消息一出,不少用户连夜进行了测试。从社交平台上的反馈来看,社区对Opus 4.7的评价呈现出明显的两极分化。
大部分用户认可其在编程能力上的提升,但在文案撰写、日常对话沟通等方面,吐槽的声音则相当集中。
Claude Opus 4.7主要能力提升
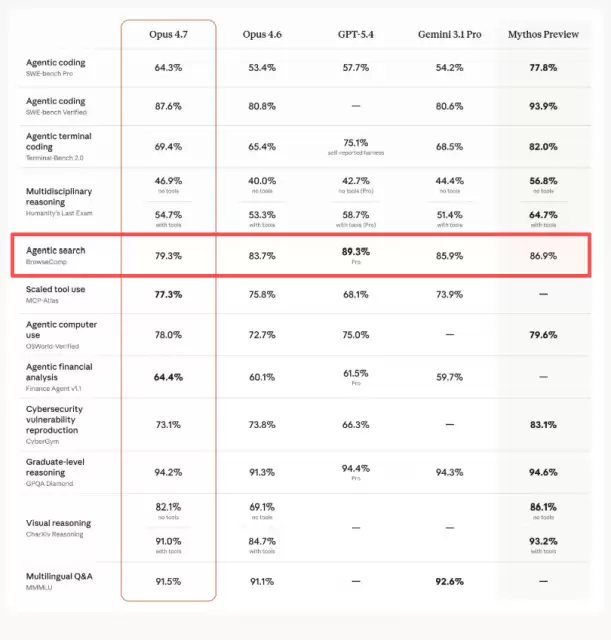
根据官方发布的数据,在编码与复杂推理方面,Opus 4.7的表现更为严谨和一致。它能够自行验证输出结果,这让处理那些长期运行、多步骤的复杂任务变得更为可靠。有用户反馈称,过去需要密切监督的复杂编码工作,现在可以更放心地交给Opus 4.7去执行。模型能够精确遵循指令,并在最终汇报前主动进行自我检查。
视觉能力是另一大亮点。Opus 4.7支持更高分辨率的图像输入,其长边最大可达2,576像素(约375万像素),这是前代模型的3倍以上。这一提升使得模型能够处理依赖精细视觉细节的任务,例如读取密集的屏幕截图、从复杂图表中提取数据,或者进行像素级的参考比对。
需要特别注意的一点是,Opus 4.7开始严格按字面意思理解并执行指令。这意味着,为旧模型编写的提示词可能会产生意想不到的结果——因为旧模型往往会进行宽松解释或自动跳过部分内容。用户需要据此重新审视和调整自己的提示词与工具链。
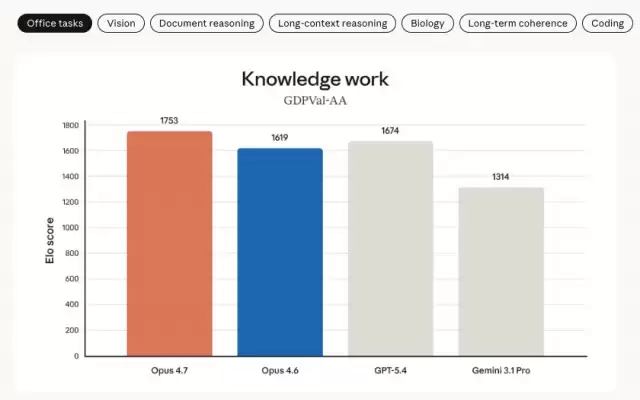
内部测试表明,Opus 4.7在专业领域表现更出色。它像是一位更高效的金融分析师,能够生成严谨的分析模型和更专业的演示文稿,并实现更紧密的任务整合。在第三方评估基准GDPval-AA(涵盖金融、法律等领域的经济价值知识工作)上,Opus 4.7也达到了业界最先进的水平。
此外,模型在利用基于文件系统的记忆方面变得更聪明了。它能够在多轮、长时间的工作中记住重要笔记,并在后续的新任务中直接调用这些记忆,从而减少了前期需要输入的上下文信息量。
安全性方面,Opus 4.7配备了自动检测和拦截功能,旨在阻止涉及禁止或高风险网络安全用途的请求。Anthropic同时表示,安全专业人士若需将模型用于合法的网络安全目的,如漏洞研究、渗透测试等,可以申请加入新推出的“网络验证计划”。
总体而言,Opus 4.7在安全性上与4.6版本相似:在欺骗、谄媚、协助滥用等令人担忧的行为上发生率较低。在诚实性和抵御恶意“提示注入”攻击方面,新模型优于旧版;但在某些特定方面,例如对受管制物质给出过于详细的减害建议,则表现略有退步。
新增xhigh级别选择,更费token了
根据Anthropic的官方博客,Opus 4.7还同步更新了一系列新功能:
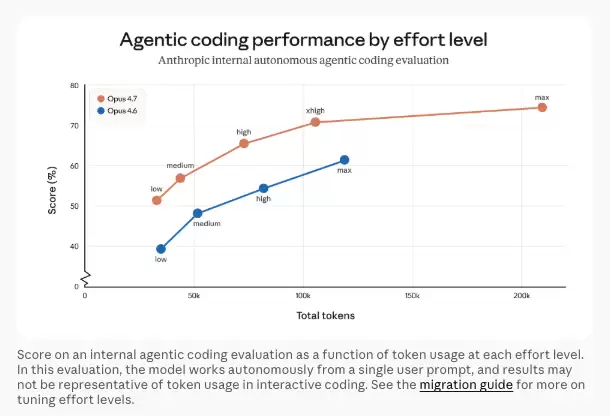
首先,在原有的“high”(高)和“max”(最大)努力级别之间,新增了一个“xhigh”(极高)级别。这为用户在处理困难问题时,提供了更精细的权衡选项,以在推理质量和响应延迟之间做出选择。
在Claude Code中,所有计划的默认努力级别已提升为“xhigh”。对于编码和智能体用例,官方建议从“high”或“xhigh”级别开始测试。
除了支持更高分辨率图像外,Anthropic还公开测试了“任务预算”功能。开发者可以通过设定预算,来引导Claude在较长的运行过程中合理分配token开销。
Claude Code新增了/ultrareview命令,该命令会启动一个专门的代码审查会话,通读代码变更并标记出那些需要细心审查才能发现的bug和设计问题。Pro和Max用户目前可以免费试用3次。
此外,“自动模式”已向Max用户开放。在该模式下,Claude可以代为做出一些权限决定,从而以更少的中断运行更长的任务,同时控制相关风险。
值得注意的是,Opus 4.7虽然是4.6的直接升级版,但有两点变化会显著影响token使用量,必须提前规划:
第一,新的分词器改进了文本处理方式,但同样的输入内容可能会被映射为更多的token,比例大约在1.0到1.35倍之间,具体取决于内容类型。
第二,在更高的努力级别下,模型的思考量会增加,尤其是在智能体场景的后续交互轮次中,Opus 4.7会产生更多的输出token。
用户可以通过调整努力级别参数、设置任务预算,或者在提示词中要求模型回答更简洁来控制token消耗。Anthropic的内部测试显示,在其内部的编码评估中,所有努力级别的token使用效率均有所提升。
用户评价两极
对于Opus 4.7的编程能力,多数实际体验过的用户都给出了肯定评价,承认其能力确实更为强大。
然而,让不少用户感到措手不及的,是token消耗的激增。有用户直言,官方通篇强调视觉提升,却只字不提这玩意儿消耗token的速度堪比喝水。用同一张设计稿进行测试,Opus 4.7的输入token数量直接飙升至Opus 4.6的3倍多。
更令人关注的是,Opus 4.7在某些能力上出现了不升反降的情况。
在长上下文信息检索方面,Opus 4.6的评分能达到78.3%,而Opus 4.7直接掉到了32.2%。Anthropic对此的解释是,新模型在遇到信息缺失时会直接报错,而不再像以前那样进行“脑补”。但用户实际测试下来发现,即便信息明明白白地存在于上下文中,它也可能遗漏。这对于依赖长文档工作的法律、金融等领域用户而言,需要格外谨慎。
Opus 4.7的联网搜索和智能体能力也出现了轻微下降。其智能搜索评测BrowseComp的分数从Opus 4.6的83.7%降至79.3%,与GPT-5.4(89.3%)的差距被进一步拉大。
被吐槽最多的,莫过于Claude Opus 4.7文风的突变。
许多文字工作者反映,Opus 4.7现在满嘴都是“稳稳接住”、“压实闭环”这类互联网大厂黑话,破折号使用混乱,续写的内容也显得干巴巴。用户无奈吐槽:“以前是用它来改文案,现在光是修改它生成的文案就要花两倍时间。”
最后,模型的思考过程被隐藏了。Opus 4.7默认不再输出推理摘要,用户若想了解其内在逻辑,必须手动添加命令。对于复杂任务,一旦出错,你根本无从知晓它是在哪一步思考上出现了偏差,导致排查问题的成本翻倍。有人认为这是官方为防止技术被“蒸馏”而采取的措施,但此举无疑牺牲了开发者的调试体验。
总而言之,Opus 4.7并非一次无痛的平滑升级。如果你的核心应用场景并非硬核编程,那么不妨先观望一下。




