AI 产业正从参数竞赛走向“兑现真实能力”的关键阶段
你发现了吗?AI产业的焦点正在发生一次静默但深刻的转移。随着智能体(Agent)应用、长文档理解、多轮复杂交互快速成为标配,大模型落地的核心命题,已经从“能不能训出来”悄然转向了“能不能高效跑起来”。而在推理这个关键环节,“Attention”机制,正成为制约长上下文性能的核心瓶颈。它直接决定了部署成本、响应速度与最终的用户体验,更关乎整个AI算力体系,能否稳稳承接住长上下文、长链条推理与多智能体协同等新一代的产业需求。
长上下文普及之下,Attention 量化成为行业新战场
与模型中的Linear层相比,Attention的计算路径更长、数值波动更为剧烈、对数据流高度敏感。这就导致了一个难题:传统的量化方案,往往难以在“精度保留、动态范围、工程简洁”这三大目标间取得平衡。结果通常是,要么在复杂的数据分布下精度“塌陷”,要么依赖极其细粒度的量化策略,大幅抬升工程实现成本,要么就是无法在真实的业务场景中,充分释放出硬件的峰值算力。可以说,Attention量化长期被视为大模型高性能推理的“卡脖子难题”。在这个领域,谁率先取得实质性突破,谁就能掌握长上下文时代的推理主动权。
“HiFloat8(HiF8)”:面向长上下文 Attention 的全新解法
正是在这样的背景下,“HiFloat8”(简称HiF8)给出了一个面向长上下文Attention的全新解法。必须指出,这不仅仅是一次简单的8-bit精度优化,更是针对AI算力与大模型推理瓶颈的底层突破。
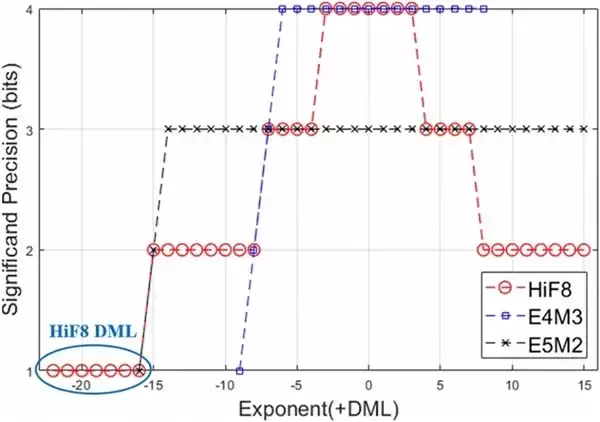
图一:有效精度 VS 指数值:HiF8 锥形精度示意图
它的核心创新在于设计思路。不同于传统FP8格式固定划分指数位与尾数位,HiF8采用了一种适配Attention数据特征的“动态精度分配”设计,呈现出独特的锥形精度分布。简单来说,它在数值出现概率最高的区间保留了充足的精度,同时在数据分布的两端覆盖了更大的动态范围。关键在于,这一设计并未显著增加数据流的复杂度,却成功地将8-bit量化真正落地到了Attention这条最关键、也最敏感的推理链路上。
这一创新的价值,远超单点的技术优化。回顾过去,AI基础设施的焦点多集中在模型适配、框架兼容与生态建设上。而HiF8直指更底层的核心瓶颈,其思路是“不被动适配已有模型,而是主动破解推理关键痛点”。这标志着一个重要的转变:AI算力与基础软件正从“能支撑”迈向“能优化、能突破”的全新阶段。
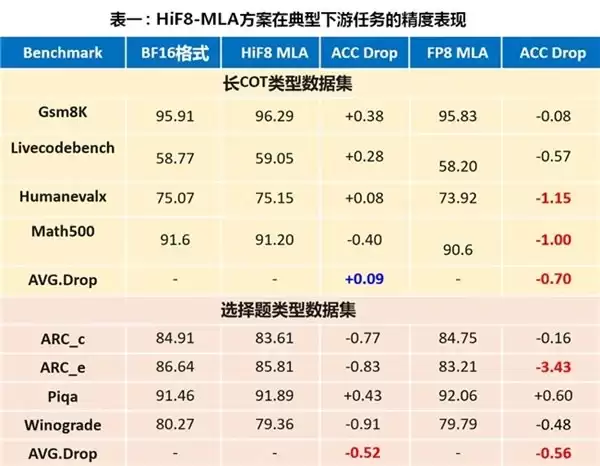
实测数据:精度与性能不必二选一
那么,实际效果如何?实测数据印证了HiF8“精度与性能双优”的特性,真正实现了鱼与熊掌可以兼得。在LongCat模型的典型下游任务中,采用HiF8进行Attention量化,在保持高效数据流的同时,整体精度与BF16基线基本持平。在长链思维(CoT)任务中,其稳定性优于参考的FP8方案。即便是在最长输入达“128K”的LongBench v2测试集上,其精度表现依然稳健。
更值得关注的是,其性能收益随着上下文长度的增长而持续放大。基于昇腾 910B 平台的实测数据显示:对于LongCat-560B模型,端到端加速比从“1.59倍”提升至“2.60倍”;对于DeepSeek v3.1模型,则从“1.52倍”提升至“2.65倍”。输入序列越长,HiF8带来的优势越显著,完美匹配了长上下文、复杂推理与Agent应用的主流产业趋势。
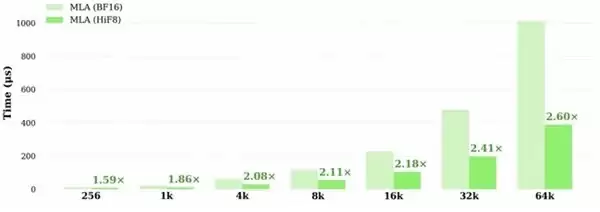
图二:LongCat-560B HiF8 量化方案相对于 BF16 的加速比
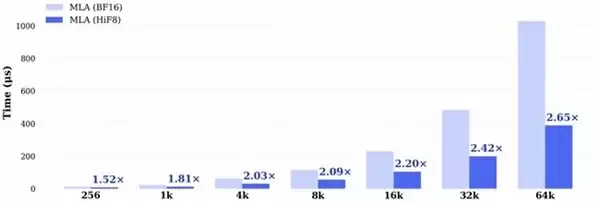
图三:Deepseek-v3.1 HiF8 量化方案相对于 BF16 的加速比
行业意义:突破规模化落地的核心命题
从更宏观的行业视角看,HiF8的意义远不止于局部优化。它精准回应了大模型规模化落地的核心命题:当模型能力持续跃升之后,底层的推理系统能否同步进化,在成本、时延、精度和工程效率之间达成新的、更优的平衡?答案是,唯有突破Attention量化这一关键环节,大模型才能真正从实验室、从评测榜单,走向大规模的企业级部署与深度的行业落地。
话说回来,Attention量化的这次突破,也是整个AI技术体系向深处生长的缩影。当前的算力竞争,早已超越了“有无”的层面,进入了“把关键底层问题做透”的新阶段。HiFloat8在长上下文Attention量化上的创新,为大模型的高性能推理补上了关键一块拼图,为AI算力突破打开了新的想象空间,无疑将助力中国AI产业在长上下文时代筑牢更坚实的创新底座。




