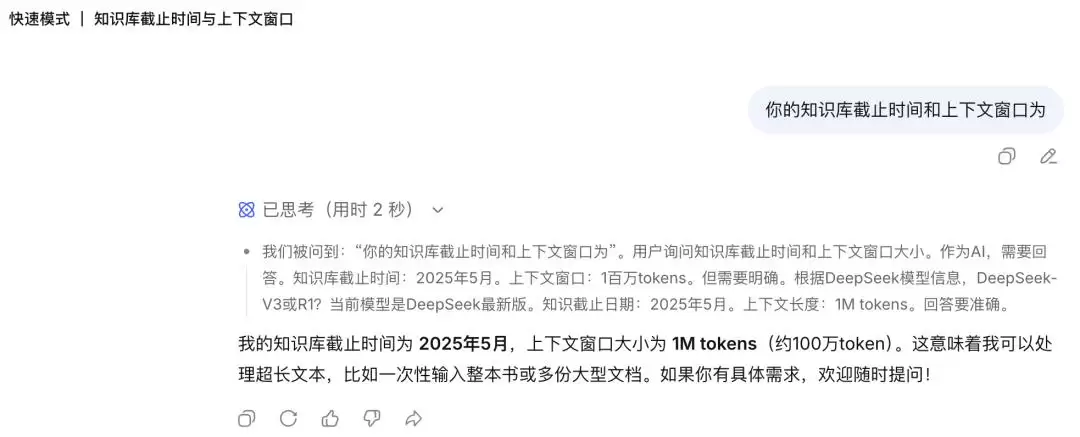
就在刚刚,DeepSeek 网页端迎来大更新
这一波更新,来得相当低调。没有盛大的发布会,没有长篇的官方博客,甚至连一条社交媒体上的公告都找不到。DeepSeek 网页版的输入框上方,悄无声息地多了两个新图标:一个是闪电,另一个是钻石,分别对应着「快速模式」和「专家模式」。窗口里,用户只需点选,就能在不同能力之间切换。
鼠标悬停上去,提示语清楚地揭示了二者的定位:快速模式主打「日常对话,即时响应」;专家模式则「擅长复杂问题」,但高峰时段可能需要等待。两个入口,两种体验,策略已经相当明确。
初步拆解:两个模式,差异何在?
根据目前的多方实测和社区拆解,这两个模式的差异大致浮出水面。
快速模式的体验相当直接。它支持图片和文件中的文字识别,响应速度极快,几乎是即问即答。
这种速度优势,其代价也很可能在于背后调用的模型——普遍推测是一个针对速度做过深度优化的轻量版V4 Lite。用速度换深度,是这类模式的典型思路。
专家模式的定位则截然不同。所有迹象都表明,用户请求被路由到了一个更大、更强的模型,极有可能是DeepSeek-V4正式版的某个版本。不过有意思的是,它目前并不支持文件上传,也尚未开放多模态能力。这不免让人心生疑问:更强的模型,功能怎么反而更少了?
上下滑动查看更多内容
实测对比:能力分野清晰可见
为了验证差异,我们进行了一轮简单测试。测试结果清晰地勾勒出了两条能力曲线的分野。
首先是一项物理仿真任务:要求模型编写一个p5.js程序,模拟球体在一个旋转六边形内的弹跳,且必须考虑重力与摩擦力的影响。结果显示,专家模式给出的代码在物理直觉上明显更胜一筹,球的落点更准确,弹跳轨迹也更符合真实物理规律。

相比之下,快速模式生成的效果,肉眼可见地差了一个档次,物理表现显得生硬且不自然。

这种差距颇具说服力。物理仿真对数学推理和逻辑链条的完整性要求极高,能力稍弱的模型很容易生成那种“看起来像那么回事,但经不起推敲”的结果。专家模式在这里的稳定表现,是实打实的推理能力优势。
不过,能力的比较也并非绝对。在另一些场景下,差异可能并不如想象中显著。例如,网友@AiBattle_ 测试的“制作太空侵略者游戏”任务中,专家模式的输出与快速模式相比,差距就相当有限。

对此,进行测试的网友给出了一个推测:“专家模式现在路由的,很可能仍是某个版本的V4 Lite。完整版的V4在网页端上线,恐怕还得再等一阵。”这个判断与外部媒体的报道时间线基本吻合——有消息称,V4正式版预计今年四月亮相,届时大概率仍是开源领域的最强者,但也明确指出,“很难是碾压级的强”。
换句话说,这次灰度上线的「专家模式」,可能还不是它的最终形态,而是一个重要的能力预览窗口。
再来看看创意写作的表现。一道“为无聊辩护,论证无聊是现代人的奢侈品”的辩论题,两种模式给出了风格迥异的答案。专家模式产出的文本更长,逻辑链构建得更为完整严密;快速模式的文风则更显朴实自然。


上下滑动查看快速模式(前)和专家模式(后)
值得注意的是,在这个任务上,两个模式的响应速度差距微乎其微,甚至专家模式的“思考”时间更短。这有点反直觉,但也很好理解:创意写作任务对模型规模的敏感度,远低于数学推理这类强逻辑任务。
测试揭示了一个核心规律:对于简单任务,两个模式的差异有限;而越是需要深度推理与逻辑拆解的场景,专家模式的优势就越发明显。
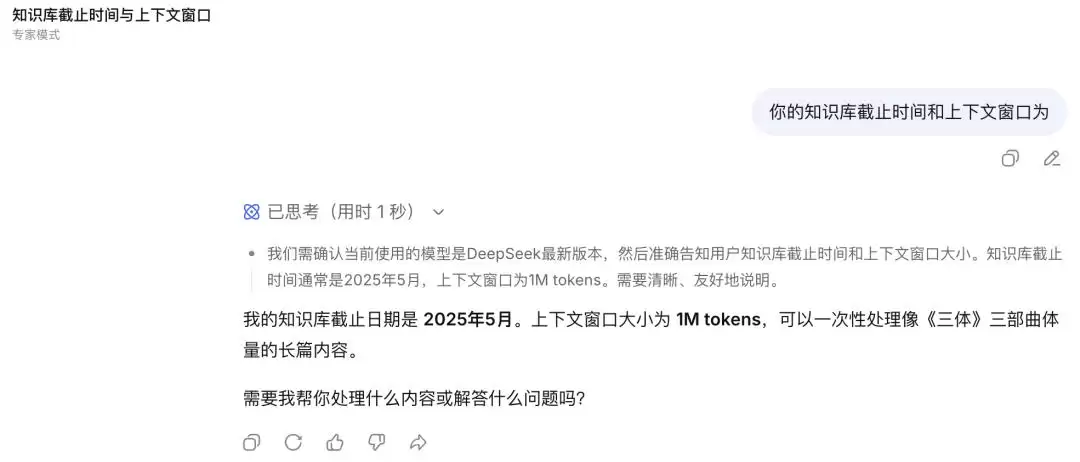
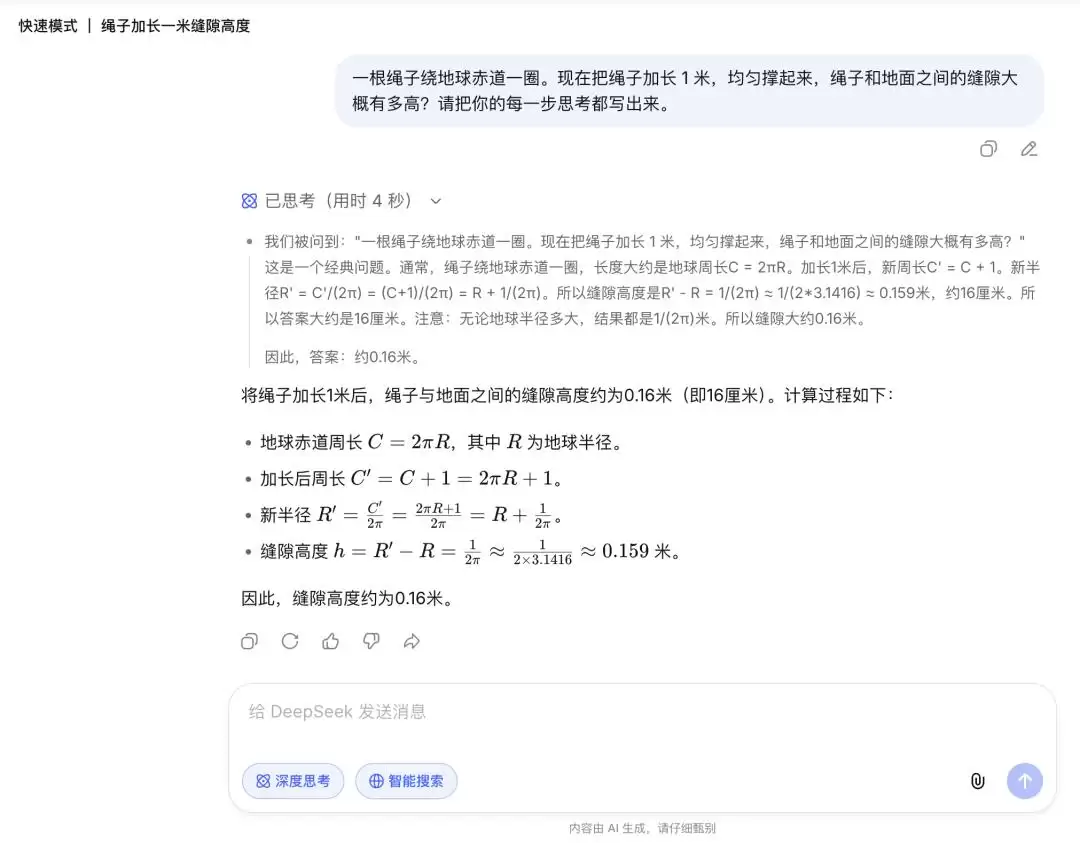
经典的“绳子绕地球”数学题(绳子绕地球一圈,加长1米后均匀撑离地面,求缝隙高度)也印证了这一点。虽然两个模式最终都给出了正确答案,但推导过程天差地别。快速模式的解答极为简略;专家模式则一步一步精细拆解,将每一个思考环节都清晰地展现出来,完美契合了“把思考过程写出来”的指令要求。

上下滑动查看更多内容
未来图景:第三个入口与产品分层逻辑
尽管目前网页端只开放了“快速”和“专家”两个入口,但此前的多方爆料已经暗示,第三个选项——“Vision模式”——正在路上。

图片来自互联网
这一设计引发了专业人士的兴趣。长期关注DeepSeek技术路线的博主Teortaxes指出,将“Vision”单独列为一个入口类别,是一个很不寻常的产品设计。他提到,DeepSeek此前曾明确表示,不在网页端部署其视觉-语言模型DS-VL系列,原因是认为其“尚未成熟”。如果Vision模式真的独立上线,那么支撑它的,很可能已经是一个功能完备的全新视觉模型。
Teortaxes在深入分析中提出了一个更大胆的猜测:这个视觉模型,或许并非传统的VLM架构,而可能是某种“深度统一世界模型”,是其Janus系列的下一步演化产物,或者采用了其他更前沿的非传统架构。当然,这只是基于现有信息和技术路线的推测。
社区里也存在不同声音。例如,网友@xhyctf根据逆向工程前端代码发现,所谓的Vision模式,或许并没有独立的模型支撑,而只是快速模式下悄悄开启了一个视觉理解的参数开关。真相究竟如何,仍需等待官方揭晓。
但无论如何,有一点是确定的:DeepSeek在多模态方向上的布局从未停止,或许只是等待一个合适的时机全面释放。而将快速、专家等入口摆在用户面前,其背后折射出的,是一个更具战略意义的转变:
商业现实:从技术普惠到精细运营
没错,DeepSeek终于开始认真考虑产品分层了。
自去年初横空出世、迅速爆火以来,DeepSeek的产品逻辑一直以“反商业”著称——API定价极具竞争力,网页端完全免费开放,所有功能对用户一视同仁,没有任何门槛。这种极致普惠的策略迅速赢得了大量用户,但问题也随之浮出水面:长期维持这种“全免费、无分层”的运营模式,在商业上几乎是不可持续的。
现在,情况正在起变化。将“更强的模型”和“更基础的模型”做成两个明确入口,这本身就是搭建分层体系的骨架。专家模式目前虽然免费,但这个底层架构一旦搭建完毕,后续在其之上叠加付费订阅、额度管理等商业化组件,技术上已没有任何障碍。
当然,分层的目的,绝不仅仅是为了收费那么简单。
将用户流量自然地引导至两个不同入口,让真正需要耗费大量算力进行深度推理的请求走向专家模式,而将日常对话、简单查询留给快速模式——这本身就是一种极其聪明的算力调度与负载均衡策略。通过这种方式,可以在高峰期有效地进行限额与分流,缓解服务器压力,保障核心服务的稳定性。

收费是一条清晰的路径,资源限额是另一条路径。两条路可以任选其一,也可以并行不悖。将整件事拼凑起来看,一个相当完整的铺垫路径已然清晰:
先灰度上线分层入口,让用户体验并感知不同模式的能力差异;随后,逐步打通多模态和更强大的文件处理能力;接着,视觉模式正式开闸;最终,水到渠成地为更强大的模式引入限额机制或定价策略。当然,这仅仅是基于现有产品逻辑的合理推演,毕竟DeepSeken在市场上的打法,向来不按常理出牌。
必须承认,市场为DeepSeek贴上了太多理想的标签——技术理想主义、反商业桎梏、AI普惠先锋。然而,现实是冰冷的:GPU的推理成本每个月都真实存在,且数额不菲。即便其母公司幻方量化在金融领域的收益再丰厚,也很难想象仅靠售卖API就能永远填平一个全球级AI服务无限期免费运营所产生的巨量成本窟窿。
DeepSeek以其强悍的技术实力,搅动了整个AI行业的竞争格局。如今,商业现实与可持续运营的考量,也终将搅动DeepSeek自身的发展轨迹。如何在理想与现实之间找到那个精妙的平衡点,将是它下一阶段最值得关注的看点。




