文 | 孙永杰
近日,当国家数据局披露“日均Token调用量突破140万亿”的数据时,这个看似技术性的指标,很快被赋予了宏大的意义—中国正在成为AI时代最重要的“算力输出者”。
Token(词元)原本只是大模型处理信息的最小单位,但在今天,它已经悄然转化为一种新的计量与计价方式。在OpenAI、Anthropic等主流平台上,开发者购买的不是模型本身,而是Token的使用量。这种变化,使得Token逐渐具备了类似“资源”的属性,也让“Token是AI时代硬通货”的说法开始流行。
但如果我们把视角从数量增长转向结构变化,一个更值得思考的问题浮出水面,那就是Token规模的爆发,是否意味着我们已经掌握AI发展的主动权,还是仅仅占据了某一层优势?未来的决胜点到底在哪里?
流量狂飙背后,中国Token规模与营收倒挂
如果只看数据,中国Token的增长速度几乎可以用“失重”来形容。从千亿级到万亿级,再到如今的百亿亿级,这种跃迁并不是简单的技术进步,更像是一种基础资源正在被大规模释放的过程。具体表现为AI正在从实验室走向现实世界,从能力展示转向基础设施,而Token正是这个过程中的“流量单位”。
需要说明的是,支撑这种爆发的并非单一因素,而是几条长期曲线的交汇。最直观的表现就是价格曲线的快速下探。例如以DeepSeek、阿里云、百度为代表的厂商,在过去一年中将Token价格压到了一个前所未有的区间,使得原本只属于头部企业的能力,开始向中小开发者甚至个人用户开放。彼时AI从“用得起才用”,变成“几乎任何场景都可以试一试”。这种价格重构,本质上是在重新定义AI的使用门槛,也在重塑市场结构。
与此同时,中国独特的基础设施路径开始显现出威力。在国家数据局推动下形成的“东数西算”体系,让西部的低价电力得以转化为东部乃至全球可调用的算力资源。过去难以直接参与全球贸易的电力,正在通过数据中心与模型服务,被转换为可以按需调用的Token。而这种“能源—算力—服务”的链条,使中国具备了将本土资源转化为全球性数字供给的独特能力。
更重要的是,这种供给并非建立在牺牲质量的基础上。随着模型能力的快速迭代,中国厂商在代码生成、长文本处理、多语言支持等方面,已经能够在大量实际场景中对标OpenAI和Anthropic等。同时鉴于在不少应用中,开发者更看重的是够用且便宜,而非极限性能,使得这种“工程上的可用性”,叠加成本优势,让中国模型应用在全球范围内迅速上量,越来越多的调用请求流向中国模型,Token规模由此被迅速放大。
但如果我们把视角从调用规模切换到商业价值,另一幅有些反直觉的结果出现了。
一组来自非凡产研统计的数据显示(截至去年8月份),在“全球AI公司月活”里,中国公司拿下了约46.0%的全球月活(美国约43.2%),而在“全球AI公司收入Top100”里,包括OpenAI、Anthropic等少数头部美国AI公司却拿走了约91.9%的全球ARR(经常性收入),中国公司仅占3.5%。
这里我们不妨用更直观的对比来感受一下:百度的全网月活约7.30亿,字节约3.72亿,深度求索约2.05亿,美图约1.95亿;而收入榜侧,OpenAI一家ARR约174.75亿美元,Anthropic约72.68亿美元,而中国收入榜的总和仅约12.87亿美元。
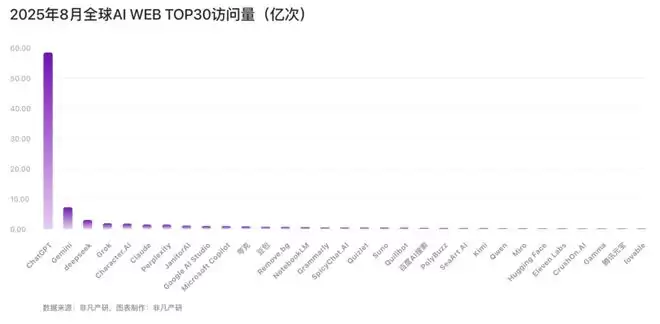
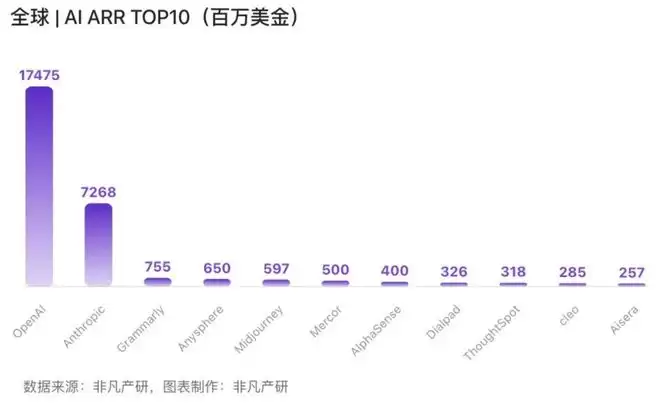
这意味着一个耐人寻味的倒挂正在形成,即流量在中国,收入却集中在美国。
值得注意的是,进入2026年,尽管部分国产模型(如MiniMax、Kimi)已展现出海外收入占比显著提升的势头,例如MiniMax海外收入占比已超70%,Kimi海外收入开始超过国内,但整体营收倒挂的结构性特征依然存在。
由此可见,中国虽然正在赢得调用规模,却尚未完全转化为商业价值。而这一结构性错位,正是理解中国Token繁荣背后真正含义的关键入口,即当Token成为一种“资源”之后,我们不仅要看“产量”,更要看“含金量”和“定价权”。也正是在这个意义上,如果我们把视角从调用规模切换到商业价值,一个更值得关注、也更具解释力的结构性现象开始浮现。
规模之上的Token,价值和规则才是核心竞争力
如上述,Token的爆发,很容易让人产生调用量越大,代表产业越强的错觉。而如果把这些Token拆解来看,就会发现其中的差异远比数字本身更重要。
众所周知,在现实应用中,并非所有Token都具有相同价值。一部分Token来自高价值场景,例如复杂决策、专业分析、科研辅助,这些调用往往对应着较高的付费能力和长期依赖;而另一部分Token,则来自测试调用、低质量内容生成或大规模自动化任务,它们在数量上庞大,但在经济意义上相对有限。尽管两者在统计上没有区别,但在产业结构中却扮演完全不同的角色。这意味着,如果缺乏高价值场景的支撑,单纯的Token增长,很容易陷入规模膨胀而价值不足的怪圈。
当然,在讨论Token规模时,还有一个无法回避的结构性因素,那就是中国市场本身的“封闭性”在一定程度上放大了这一数字。
业内知道,在中国大陆,OpenAI、Anthropic以及谷歌(Gemini)等模型的直接使用和商业化部署存在客观限制,这意味着大量原本可能流向全球多家模型厂商的调用需求,被集中留在本土体系之中。相较之下,美国市场的开发者可以在多个模型之间自由分流调用(包括部分中国模型),至于在中国,绝大多数应用调用天然集中在国产模型之上。
而正是这种结构差异,使得Token规模在中国呈现出一种集中放大的效果。从统计上看,这无疑强化了中国在Token调用量上的领先地位,但如果简单将其等同于全面竞争力优势,则容易产生误判。换言之,中国的Token规模领先,既来自真实的供给能力提升,也受到需求结构“内聚化”的放大。
需要强调的是,这种放大并非虚假繁荣。毕竟能够承接并放大这部分需求的前提仍然是中国模型在成本、性能与工程能力上的进步已经足够支撑大规模应用。否则,即便外部模型受限,AI应用本身也难以如此快速铺开。因此,这种现象更接近一种真实能力叠加结构红利的结果,而不是单纯由外部环境使然。
然而,其潜在影响还是需要我们警惕。原因在于长期处于相对封闭的竞争环境,容易让规模增长掩盖结构差异,尤其是在高价值场景与顶级能力层面的差距判断上。如果缺乏与全球最强模型的持续对标与竞争,Token规模的领先,可能更多停留在使用密度层面,而难以自然转化为价值密度的领先。
与此同时,为了快速扩大规模,不少国产模型选择了一条更现实的路径,即在接口层面兼容OpenAI的标准。类似的messages结构、相似的参数设计、甚至“只改base_url即可切换”的调用方式,使开发者几乎可以无成本迁移。而这种策略无疑极大地降低了使用门槛,是Token规模迅速增长的另外重要原因之一。
但问题也恰恰出在这里。当一种生态的“语言”和“接口范式”已经被定义时,后来者即使在规模上实现反超,也往往难以在规则层面取得主导权。相较之下,Anthropic之所以成为OpenAI最强劲的对手,在于其并没有完全兼容OpenAI接口,而是保持一定相似性的同时,构建了独立的API体系,并借助Amazon的AWS生态进行分发。虽然这种路径牺牲了部分迁移效率,却在长期发展中保留了争夺标准话语权的空间。
上述策略的差异,实际上揭示了一条更底层的逻辑:规模和规则并不等同。实际上,历史已经反复证明,使用最多的系统未必制定规则,出货量最大的产品也未必掌握标准。在AI领域,这种逻辑同样适用。而事实是,当前的API范式、开发框架乃至企业级集成路径,仍然深受OpenAI、微软和谷歌等体系的影响。
也正因为如此,一种看似矛盾的结果出现了,那就是中国在Token规模上快速领先,但在规则与生态层面,仍然处于“参与者”的位置。而这种“规模领先、规则滞后”的错位,正是当前阶段最值得警惕的隐忧。
Token产业化,亟待底层创新与规则定义能力
综上,如果说Token规模回答的是量的问题,那么决定未来的,始终是结构的问题。从这个角度看,中国AI真正需要跨越的,并不是再多产生一些Token,而是完成一次更深层的结构跃迁。
首先需要突破的,是从成本优势走向不可替代能力。不可否认,低价格可以迅速打开市场,但很难长期锁定市场。一旦竞争进入充分阶段,单纯依靠价格优势,往往会演变为持续的内卷。而真正能够形成定价权的,往往是那些在关键场景中不可替代的更强的推理能力以及更稳定的企业级表现,抑或在特定行业中的深度优化。这些能力,才是将“可用”转化为“必须用”的关键。虽然我们在编程、Agent等特定领域已有局部领先的迹象,但整体仍需向更高阶能力跃升。
其次,是从接口兼容走向标准定义。当前AI生态中最隐蔽却最关键的控制力,并不在模型本身,而在接口、工具链与开发范式。谁定义了这些,谁就决定了开发者如何构建应用、企业如何接入AI。基于此,如果我们长期停留在“兼容者”的位置,那么即使规模再大,也很难在生态层面取得主导权。而只有当中国厂商开始在接口设计、开发框架乃至应用范式上提出自己的标准时,规则层面的竞争才真正开始。
更深一层则是底层技术与系统能力的持续突破。毕竟Token只是最终的表现形式,其背后是芯片、算法与工程体系的综合能力,而在这一层面,英伟达仍然掌握着关键的算力节点;顶级模型能力也仍主要集中在欧美厂商手中。此背景之下,如果我们缺乏持续的底层创新,Token的成本和规模优势,很可能难以长期维持。
最后,也是最容易被忽视的一点是高价值场景的应用。未来真正决定AI产业格局的,并不是谁生成了更多Token,而是谁掌握了最有价值的那部分Token。无论是金融、医疗,还是工业与科研,这些领域对模型能力、稳定性和可信度的要求远高于普通应用,同时也对应着更高的商业价值。所以只有在这些场景中建立优势,Token规模才会转化为真正的产业能力。
综上,我们认为,140万亿Token,确实可喜可贺,它说明中国已经在AI时代占据了一席重要位置,甚至正在成为全球最重要的算力供给方之一。但我们同样需要看到,真正决定长期格局的,从来不是单一维度的领先,而是多层结构的协同演进。
而真正的分水岭,不在于Token能否继续增长,而是中国能否从“生产更多Token”,走向“定义Token如何被使用“。只有当这一步完成,Token才不只是一个高速增长的数字,而是成为一个真正具备产业化能力的基础资源。




