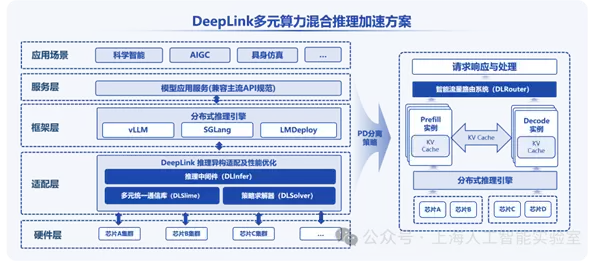
3月8日传来的最新消息,上海人工智能实验室(上海AI实验室)正式宣布,在原有DeepLink混训技术方案与跨千里多智算中心长稳混训千亿参数大模型的基础上,推出了DeepLink多元算力混合推理加速方案,实现了对华为昇腾、沐曦、阿里平头哥、壁仞等多款国产GPU芯片的混合调度与协同推理。
据了解,DeepLink混推方案基于统一推理中间件、低时延通信、智能流量路由、策略求解器等原创技术,不仅能对多款芯片进行混合调度与协同推理,性能也实现了大幅提升。与单一芯片方案相比,推理时延TTFT最高可优化34.5%,推理吞吐最多可提升32%。

近年来,国产AI GPU如雨后春笋般涌现,性能日益强劲,但一方面,各家芯片往往各自为战,互不通联;另一方面,大模型推理技术本身也需要不断优化和效率提升。
上海AI实验室在国产GPU异构算力整合中,运用了预填充-解码分离(PD分离)策略,验证了混合芯片高效协同推理的可行路径。
在同一数据中心内,将不同规格属性的GPU芯片组合优化使用,可以形成最具性价比的异构算力搭配。
具体实现上,上海AI实验室通过四大原创技术底座,实现了对异构算力资源的兼容调度。
推理中间件(DLInfer):
以标准化融合算子接口打通上层框架与底层硬件壁垒,实现算法模型在多元硬件上的统一推理,降低应用门槛。
高速通信库(DLSlime):
全面兼容各类主流物理连接协议,实现跨架构设备高速互联,核心场景带宽利用率突破97%;具备较强的异步处理能力,可实现计算与通信的重叠。
智能流量路由系统(DLRouter):
支持KVCache感知的请求路由,最大限度减少重复或重叠请求,节省计算资源,实现分布式集群负载均衡分配。
策略求解器(DLSolver):
自动获取异构芯片全方位置性能评测数据,结合模型配置以及用户服务等级目标等输入,匹配最优PD分离配置策略,兼顾推理性能与成本。
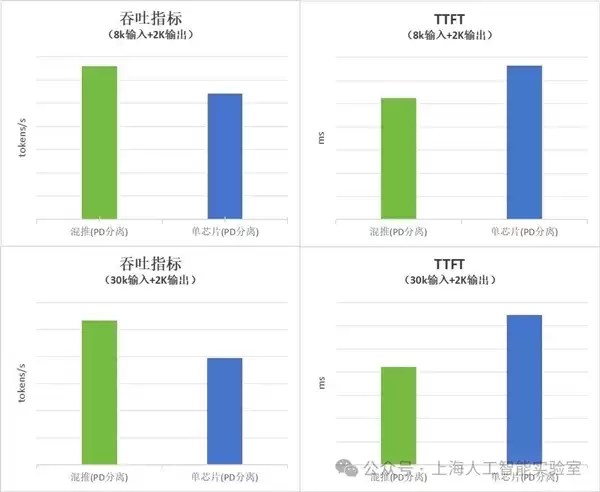
在单一算力平台推理加速方面,方案已在华为昇腾A2平台上,针对千卡规模下的化学数据生成场景,实现了61.9%的吞吐率提升;在沐曦曦云C500上,则使MinerU多模态生成推理加速了60%。
在多款国产GPU芯片的深度混合调度与协同推理方面,千卡规模推理集群实测数据表明,在多模态生成、高并发智能服务等典型场景下,对比单芯片方案,推理时延TTFT最大可优化34.5%。
在科学论文处理等长输入短输出推理任务中,推理吞吐可提升32%。
值得一提的是,除了以上四家厂商,寒武纪、燧原科技、天数智芯、无问芯穹、商汤科技、中科曙光等也都是上海AI实验室和DeepLink技术方案的重要合作伙伴。
我们相信将看到越来越多的国产GPU并肩作战!




