
AI 已经学会了电影的视觉语法,但还没学会世界的物理语法。
作者|汤一涛
编辑|靖宇
Seedance 2.0 有多猛,过去一个月大家已经见识过了。好莱坞已经集体下场发了声明,西半球最强法务部迪士尼也给字节跳动发了律师函。
但如果你让它做一件事:生成一个男人从 1 数到 10 的视频,它就露馅了。
能分清这是瑞安·雷诺兹还是本·斯蒂勒吗?好莱坞的抵制是有道理的|视频来源:@fofrai
生成出来的「人」五官端正、皮肤质感逼真,厨房背景细节丰富得像是实拍。他说出「one」的时候还一切正常,然后就开始鬼打墙,嘴里不断重复「t、t、t」这个音节(不是从 1 到 10 中任何一个数字的发音);或者伸出三根手指,口中却自信地说出「ten」。从头到尾,他竖起的手指没超过三根。
因为背景和人物都太真实了,所以手指崩坏的瞬间反而制造出了一种强烈的「伪人感」。
这道题不只是 Seedance 2.0 的噩梦。
视频来自一位在 X 网友 fofr(简介显示是在 DeepMind 的开发者)。去年他就发现,「从 1 数到 10 并用手指比出数字」这个对三岁小孩都毫无难度的任务,是当前所有 AI 视频模型的共同死穴。
Seedance 2.0 发布后,他第一时间把这道老题扔了过去,果然也翻车了。
网友在这条推文下面掀起了一场自发的「AI 数数挑战赛」。他们把同一道题喂给了 Sora、Veo、Kling 等几乎所有主流模型,结果全军覆没,没有一个能正确地从 1 数到 10。
Veo 也没法从 1 数到 10|视频来源:@AGI_FromWalmart
当一个行业最强的产品们被一道幼儿园级别的题目集体难倒,这其实指向了一个问题:为什么这些模型已经能骗过你的眼睛,却无法理解常识?
它们到底「理解」了什么,又缺失了什么?
01
统计预测 vs 理解世界:
AI 视频的能力边界
「数不到 10」不是一个孤立的 bug,它揭示了一整片当前 AI 的能力盲区。
原因也不复杂:所有的视频模型本质上做的是同一件事,从海量视频数据中学习统计规律,然后在生成每一帧画面时预测「接下来什么样的像素排列最可能出现」。这和大语言模型的「预测下一个词」(Next-Token Prediction)是同一套逻辑。
所以它们能把人脸毛孔、厨房光影、衣服褶皱渲染得以假乱真,因为训练数据里有海量样本,统计规律足够丰富。但一旦任务超出了样本的范畴,进入「常识」的领域,问题就来了。
这些问题大致可以分成三类。
首先就是手部精细动作,这是最广为人知的「AI 照妖镜」。从图像生成时代的「六指人」,到视频生成时代的「软糖手指」,手一直是 AI 的噩梦。

Midjourney 和 DALL-E 爆火的 2024 年,「手部多指」是当时文生图最明显的 Bug|图片来源:Medium
公平地说,AI 在「画手」这件事上已经取得了巨大进步。日常场景里,六指人和软糖手已经越来越少见了。
但 fofr 的测试之所以能让所有模型集体翻车,是因为它只是一个视觉渲染问题,同时还暗含了一个逻辑推理问题。它要求在 10 秒内连续变换 10 个不同手势,每个手势的手指数量严格递增,同时嘴里说的数字还要对得上。
人的手有 27 块骨骼、34 块肌肉、超过 100 条韧带,单个手掌就有 18 个自由度。即便采用高分辨率扩散模型,若缺乏明确的三维先验知识,也难以表达这种精确度。
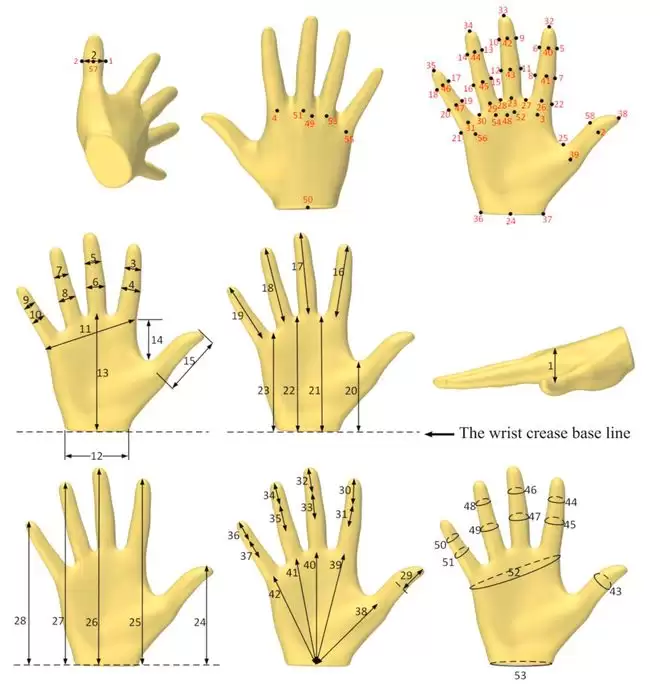
人体运动维度示意图|图片来源:ScienceDirect
况且,在训练数据中,手通常出现在画面边缘、被物体遮挡或处于运动模糊中。模型能学到的高质量手部样本远少于面部。
第二类 AI 的能力盲区是物理规律。流体怎么流、物体怎么碰撞、织物怎么飘……这些人类靠直觉就能判断的东西,AI 视频经常给出违反物理定律的答案。OpenAI 在发布 Sora 时的最新技术报告中就明确承认:Sora 无法准确模拟许多基本物理交互,比如玻璃破碎,也无法正确反映某些物体状态变化。
第三类是时序逻辑的一致性。视频不是一组彼此独立的图片,而是一条有因果关系的时间链:第 3 秒的画面必须建立在第 2 秒的基础上。但当前的扩散模型把时间当作一个潜在的数学维度来处理。它在生成第 N 帧时,没有内部机制去「记住」前面伸了几根手指、下一步该加 1。时间一长,前后就对不上了。
作个类比的话,当前的 AI 视频模型像一个从没见过真手的画家,看了一百万张手的照片之后凭印象画手。大部分时候画得挺像,但他不知道手指只有五根,不知道伸出三根手指代表数字 3,更不知道从 3 到 4 意味着要再伸出一根。
02
另一条路:世界模型
既然问题的根源是「不理解物理世界」,那有没有人在试图从根本上解决这个问题?
事实上,这正在成为 AI 领域最受关注的新方向之一。一个正在凝聚共识的思路是:与其让模型从海量视频中学习「世界看起来是什么样的」,不如让它先理解「世界是怎么运作的」。
这条路径有一个共同的名字,叫做世界模型(world model)。世界模型的核心思路是让 AI 建立对三维物理世界的结构性理解,包括空间的几何关系、物体的物理属性、运动的动力学规律等。
这就和当前视频生成模型的路径产生了本质区别。当前模型在二维平面上预测像素排列的统计概率,世界模型则试图让 AI 在「懂」物理规律的基础上做生成。
这个方向最知名的创业者是李飞飞。这位 ImageNet 的缔造者在 2024 年创办了 World Labs,核心目标是让 AI 拥有「空间智能」。她在去年的一篇长文中写道:
「语言是人类认知的产物,但世界遵循更复杂的规则——重力控制运动,原子结构决定光线如何产生颜色,无数物理定律约束着每一次交互。要让 AI 真正理解这一切,需要一种全新的、远超大语言模型的架构」。
今年 2 月,World Labs 完成了 10 亿美元融资,其首个产品 Marble 已经上线,可以从图像或文本生成持久的 3D 环境。
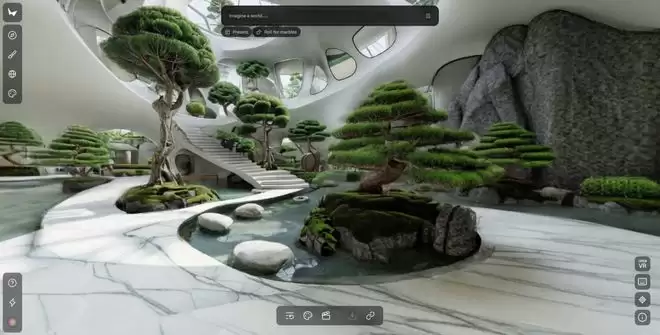
Marble 可以从一张图片或一段文字生成一个你能在里面自由走动、持续编辑的 3D 世界|图片来源:World Labs
李飞飞不是唯一的入局者。杨乐昆从 Meta 离职后创办了 AMI Labs,同样聚焦世界模型方向;Google DeepMind 的 Genie 系列模型也在探索 3D 环境的生成与模拟;Nvidia 则推出了 Cosmos,定位为「世界基础模型」,试图将视频生成、物理感知模拟和机器人工作流统一到一个框架里。
当这个领域最顶级的几位研究者和最有钱的几家公司同时往一个方向走,这本身就说明了一些问题。纯数据驱动路径的天花板,正在成为越来越多人的共识,只是解法还在探索中。
Seedance 2.0 刚出来的时候确实引起了一大波恐慌。《死侍》编剧 Rhett Reese 看完演示后甚至写下了「我不想承认,但我们可能完了」。
这种反应可以理解,Seedance 2.0 确实很强,但「数不到 10」提供了一个有用的校准视角:这些模型学会了电影的视觉语法,但还没学会世界的物理语法。它们的进步,更多是「看起来更真」,而不是「更懂现实」。
从本质上说,一个不知道手指只有五根的系统,距离真正取代人类创作者,中间还隔着一次范式级别的跨越。
人类可以稍稍松口气了,至少在 AI 学会数到 10 之前。
*头图来源:Nano Banana