3月2日最新消息,阿里巴巴今日正式发布了两款语音新模型:基于参考音频的声音克隆模型Fun-CosyVoice3.5,以及无需参考音频的音色设计模型Fun-AudioGen-VD。

据介绍,这两款模型均引入了强大的“指令遵循”能力,让用户可以自由控制声音的情感表达、语速快慢以及场景适配。
它们支持freestyle(自由风格模式)定制角色,适用于有声书制作、游戏配音、智能客服、播客内容、在线教育、直播互动等多个应用场景。
值得一提的是,这两款模型在同尺寸模型的基准测评中斩获了多项SOTA(最先进水平)成果。
在Seed-TTS基准测试的中文“困难案例”指标中,Fun-CosyVoice3.5表现尤为抢眼,其词错误率(Word Error Rate, WER)和说话人相似度(Speaker Similarity, SSIM)均达到最佳水平。
同时,由于优化了“困难案例”的发音表现,生僻字句错误率从原来的15.2%显著降低至5.3%。
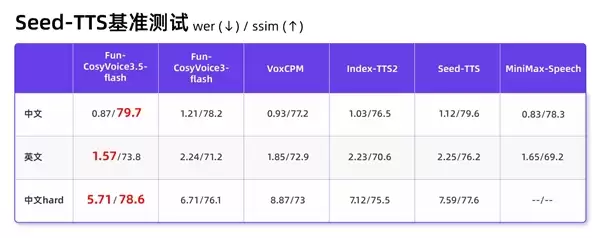
其中,Fun-CosyVoice3.5支持freestyle指令控制,有效解决了传统克隆模型只能模仿、无法指定具体角色的痛点。
Fun-AudioGen-VD则专注于“从无到有”的音色设计。在指令遵循能力和可控性的Instruct-TTS基准测试中,其表现超越了gemini2.5-pro和gpt-4o-mini-tts。
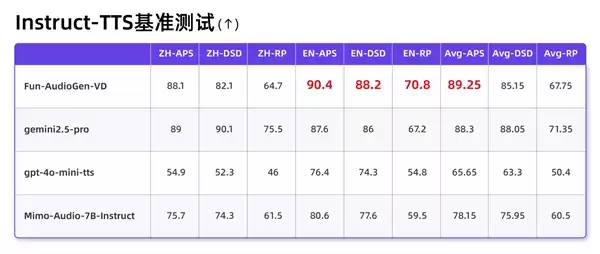
该模型不仅能根据文字描述定制音色和情感,还能同步模拟复杂的听觉环境,实现“人物+场景”的一体化生成效果。
在强化学习训练过程中,两款模型通过采用DiffRO和GRPO技术,增加了时长和韵律多通道的奖励机制。
此外,Fun-CosyVoice3.5所使用的tokenizer帧率减半,不仅提高了训练效率,其首包延迟也降低了35%,大幅提升了实时交互体验。
即日起,用户可在阿里云百炼平台直接调用这两款最新模型。




