2 月 28 日,由全球近 1,000 名顶尖学者打造的 AI 新基准“人类最后一次考试”(HLE,Humanity's Last Exam)的相关论文发在 Nature。这套新试卷覆盖数学、物理、化学、历史、语言、医学,每一道题都来自专家自己的研究领域,每一道题都有唯一正确的答案,每一道题也都经过 AI 的经验,如果哪个 AI 能够答对,这道题就会作废。

图 | 相关论文(来源:Nature)
结果呢?GPT-4o 只拿了 2.7%,Claude 3.5 Sonnet 4.1%,OpenAI 最先进的 o1 模型,8%。发布之后,更强的 Gemini 2.5 Pro 和 GPT-5 也来挑战,一个 21.6%,一个 25.3%。可谓是全军覆没,没有一个能及格。
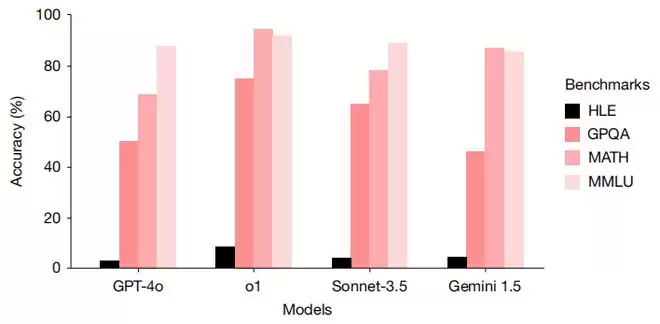
图 | 各个模型的得分(来源:Nature)
之所以出这套新卷子,是因为当前最聪明的大模型在那些曾难倒无数学生的考试里,已经能够考到 90 分以上。MMLU 这样一个包含 57 个学科、14,000 道题目的超难测试,AI 早就拿到了接近满分的成绩。
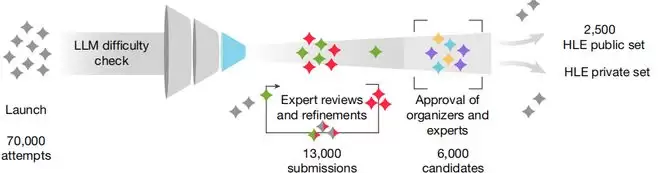
图 | “人类最后一次考试”的数据集创建流程(来源:Nature)
因此,“人类最后一次考试”的推出正是为了跟上和适应 AI 的发展。那么,这套题到底有多难?
有一道题是一张古罗马墓碑的照片,上面刻着帕尔米拉文字,要求 AI 把它翻译出来。帕尔米拉是古代叙利亚的一个城市,有自己的语言和文字,但是现在已经没人说了。翻译这种文字,需要懂古闪米特语、懂考古学、懂历史学。
另一道题问:蜂鸟身上有一块特殊的籽骨,位于某块肌肉的腱膜里,这块骨头支撑着几根肌腱?答案是数字。这就需要 AI 知道蜂鸟的解剖结构,知道那块骨头长在哪儿,知道它连着几根肌腱,差一点都不行。
还有一道题是数学,关于自然变换和余端,里面充满了 Σ、∞、Hom 这些符号。题目本身已经复杂到让大多数数学系学生直接跳过,但答案要求却是精确数字。
这套题的设计逻辑很残酷。每一道题提交之前,都要让 AI 先做一遍。如果 AI 做对了,这道题就不要。如果 AI 做错了,才会进入人工审核环节。审核要过两关,第一关是几个研究生水平的审稿人提意见,第二关是专家拍板。整个过程下来,1,000 个专家花费几个月,从几万道题里筛选出了这 2,500 道题。
如前所述,MMLU 已经无法满足当前 AI 的发展。2020 年,MMLU 刚出来的时候,AI 只能考三四十分。到了 2024 年,GPT-4 直接飙到 86 分。现在,随便一个开源模型都能考到 90 分以上。当考试分数都溢出来了,如何测量 AI 的聪明程度呢?因此,得换一套更难的新卷子。
“人类最后一次考试”这套基准测试名字听着吓人,但并不是字面意思,而是说这是 AI 最后一次可能考过的考试。等到 AI 哪天也在这套题上拿到 90% 的成绩,说明它已经具备了专家级的学术能力。
那么,AI 现在可以考多少分?前面提到,最厉害的 AI 也就考试 25% 左右,距离 90% 还有很大的差距。而且更有意思的是,AI 不知道自己不会。研究团队在让 AI 回答的同时给出信心分数,结果大多数 AI 明明答错了,却给出 80%、90% 的信心。这种过度自信非常危险,如果 AI 用在医疗和法律这些领域,而它不知道自己不知道,就会出现大问题。
还有一点值得注意。研究团队发现,推理模型在回答这套题的时候,思考时间越长,正确率越高。但当思考时间超过一定长度,正确率反而下降了。这说明不是想得越久就越好,当思考时间超过某个临界点,可能就是 AI 在瞎绕。这也给 AI 开发提了个醒,以后不能光拼推理时间,还得拼推理效率。
这套题现在已经在网上公开了一部分,网址是 lastexam.ai。任何人都可以去看看这些题目长什么样,也可以看看自己能不能答对几道。当然,大部分人可能不太能答对,因为题目本来就是给专家出的。

图 | 长长的论文作者名字,截图仅为部分论文作者(来源:Nature)
那么,这道题对于 AI 开发有什么用?
它就好比一面镜子,可以照出来 AI 到底有几斤几两。以后谁再宣称自己的 AI 多厉害,先拿这套题目考一下。考不过 25%,就谈不上超越人类。透过这套题也可以看清楚 AI 擅长什么和不擅长什么。比如,从目前的得分来看,AI 在数学和计算机上的表现稍好,但是在历史和语言上表现得惨不忍睹。
这说明 AI 的智能和我们想象得还不一样。论文里有一句话写得很克制,AI 在这些专家级问题上表现很差,说明真正的智能还需要深度、需要上下文、需要专业知识。那些觉得 AI 马上就要统治世界的人,通过尝试一下这套题目,可能就不再会那么悲观。
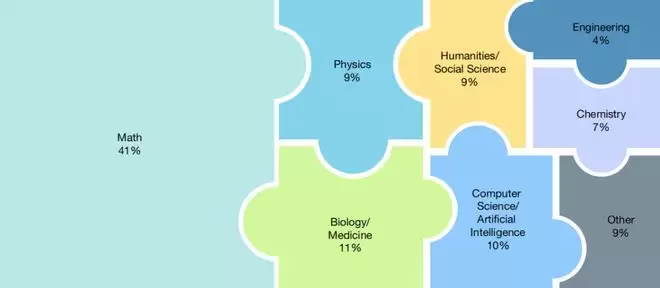
(来源:Nature)
美国德克萨斯 A&M 大学的助理教授阮东(Tung Nguyen,音译)参与了出题,他写了 73 道,是贡献第二多的作者。他告诉媒体,这套题是一种理解 AI 的方法。它就好比是 AI 的入学考试,通过设置这套门槛,我们可以知道 AI 强在哪里、弱在哪里,才能造出更安全、更可靠的技术。同时,也说明了人类的专业知识依然重要。
参考资料:
相关论文 https://www.nature.com/articles/s41586-025-09962-4
https://techxplore.com/news/2026-02-dont-panic-humanity-exam-begun.html#google_vignette
排版:胡巍巍




