2026 年 2 月 23 日,一家名为 Standard Intelligence 的旧金山初创公司发布了 FDM-1(Forward Dynamics Model,前向动力学模型),并称其为“首个完全通用的计算机行为模型”。
这个模型在一个包含 1,100 万小时屏幕录制视频的数据集上进行训练,能够以每秒 30 帧的速率直接处理视频流,在 CAD 建模、 安全测试甚至真实世界的自动驾驶场景中展示出令人意外的泛化能力。
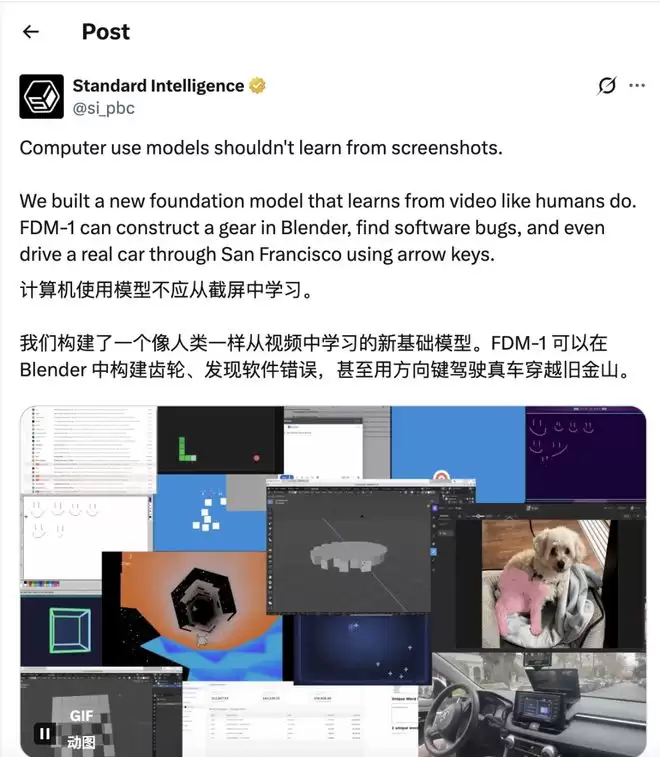
图丨相关推文(来源:X)
当前主流的计算机使用代理(computer-use agent)走的是另一条路线。Anthropic 在 2024 年 10 月推出了 Claude 的 Computer Use 功能,让 AI 通过截屏、识别界面元素、模拟点击和键入来操作计算机,到 2026 年 2 月 Claude Sonnet 4.6 在 OSWorld 基准上已达到 72.5% 的得分。
OpenAI 在 2025 年 1 月发布了名为 Operator 的 Computer Using Agent(CUA,计算机使用代理),基于 GPT-4o 的视觉能力加上强化学习实现网页操控。Google DeepMind 也有 Project Mariner 和 Gemini 2.5 Computer Use 在布局同一赛道。
这三家巨头的做法有一个共同特征:都是在已有的视觉语言模型(VLM,Vision-Language Model)基础上叠加工具调用能力,依赖截屏分析和像素级定位来理解界面,本质上仍然是“看图说话”的思路。
Standard Intelligence 认为,这条路走不远。
他们的核心论点是:要造出真正通用的计算机操作智能体,需要的不是在截屏上做分类和推理,而是直接从大规模视频中学习人类操作计算机的行为模式。就像 GPT-3 需要互联网规模的文本语料库才能涌现出语言能力,通用的计算机行为模型需要互联网规模的视频语料库。
目前最大的公开计算机操作数据集还不到 20 小时的 30 FPS 视频,而互联网上累积了数以百万计小时的剪辑制作、编程直播、游戏实况和各类软件操作录像,这些数据从未被系统性地利用过。FDM-1 正是瞄准这个缺口。
Standard Intelligence 的路线,更接近 2024 年 OpenAI 发布的 VPT(Video PreTraining,视频预训练)方法。VPT 的核心思路是:互联网上有海量人类玩 Minecraft 的游戏录像,但这些视频只记录了画面,没有标注每一帧对应的键盘鼠标操作。
OpenAI 当时的解决办法是,先花钱请承包商标注少量带操作标签的数据,用这些数据训练一个 IDM(Inverse Dynamics Model,逆向动力学模型)。IDM 能从前后帧的变化中反推出中间发生了什么操作——比如屏幕上多出来一个字母“K”,那大概率就是按下了 K 键。然后用训练好的 IDM 去给约 7 万小时的 YouTube 游戏视频自动打上操作标签,再用这些带标签的数据做行为克隆训练。
VPT 最终甚至学会了合成钻石镐这种需要连续 24,000 步操作、人类熟手也要花 20 分钟以上的任务。这在当时是一项突破,但它有两个显著局限:一是只适用于 Minecraft 这个特定环境,二是上下文窗口极短,只有大约六秒。真正的计算机工作,比如 CAD 设计、金融交易、文档编辑,动辄需要数分钟到数小时的连贯操作上下文。六秒远远不够。
Standard Intelligence 的 FDM-1 试图在两个维度上同时突破:数据规模和上下文长度。
在数据规模上,他们先是在 4 万小时的标注员录屏数据上训练了一个 IDM,然后用这个 IDM 对 1,100 万小时的互联网视频语料库进行自动标注。IDM 的工作原理比较直观:屏幕上突然出现了一个字母“K”,那大概率是有人按了 K 键;光标从屏幕左侧移动到了右侧,那一定发生了相应方向和距离的鼠标位移。通过观察前后帧的变化来反推操作动作,这在技术上是可行的,虽然存在噪声和歧义。
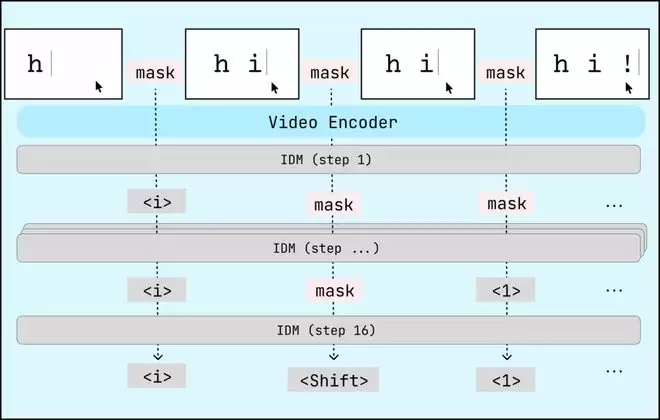
图丨逆动力学模型(IDM)架构(来源:Standard Intelligence)
他们在 IDM 的架构选择上做了一个有意思的决策:采用了掩码扩散(masked diffusion)架构。原因在于,给视频标注动作这件事天然是非因果(non-causal)的。比如你看到有人按了 Cmd+C,单看这一帧是无法确认的,你得看到后面出现了粘贴的内容才能确认之前确实发生了复制操作。掩码扩散模型可以同时参照所有帧来推断每个时间步的动作,先标注高置信度的简单动作,再把计算资源集中在模糊的难例上。
按他们的说法,这种方法比纯因果模型过拟合更慢,数据效率更高,且 IDM 标注数据训练出的模型在鼠标移动和界面操作等任务上甚至超过了人工标注数据的效果。
在上下文长度上,突破来自他们自研的视频编码器。现有 VLM 处理屏幕录制视频的方式极度浪费 token:一分钟的 30 FPS 视频就要消耗大约 100 万个 token。这意味着在 200k token 的上下文窗口里,GPT 大约只能装下 240 帧,Gemini 约 775 帧,Claude 约 162 帧——连几秒钟的视频都看不完。

(来源:Standard Intelligence)
Standard Intelligence 的视频编码器声称能把近两小时(约 36,000 帧)的 30 FPS 视频压缩进同样的 token 预算,比此前最优方案高效 50 倍,比 OpenAI 的编码器高效 100 倍(需要注意的是,博客中提到的 36,000 帧/200k token 是“屏幕录制”场景下的数字,而用来对比的 GPT、Gemini、Claude 的帧/token 比是通用视觉接口的数字。
两者的任务和优化目标不同,直接放在同一张图表里对比有些不完全对等。不过,即使打个折扣,这个压缩能力也是相当可观的)。
他们在 200k token 上下文中能装入约 20 分钟视频,1M token 中则能装入约一小时 40 分钟。这个压缩比是通过在屏幕录制数据上训练掩码压缩目标来实现的。
他们观察到,屏幕录制与自然视频有本质不同:信息密度的波动剧烈。鼠标划过空白桌面时几乎没有信息量,而滚动浏览密集文本时信息量极大。固定大小的嵌入空间必然在语义细节和压缩比之间取舍。他们的编码器在一个文本转录基准测试上,相比标准 ViT(Vision Transformer,视觉变换器)收敛速度快约 100 倍。
有了大规模的 IDM 标注数据和高效的视频编码器,他们就可以训练 FDM 本身了。FDM 是一个标准的自回归模型,接收此前的视频帧和动作序列,预测下一个动作 token。输出空间由键盘按键和鼠标移动增量组成。
由于鼠标每帧可以移动任意数量的像素,直接离散化会导致状态空间过于庞大。因此他们将鼠标位移分解为 X 和 Y 分量,用屏幕宽高进行归一化,然后使用指数分箱(exponential binning)将其映射到 49 个指数尺寸递增的箱中。小而频繁的移动分入细粒度箱,大而稀少的移动分入粗粒度箱。同时,每个鼠标移动 token 还附带预测下一个点击位置,帮助生成更精确的轨迹。
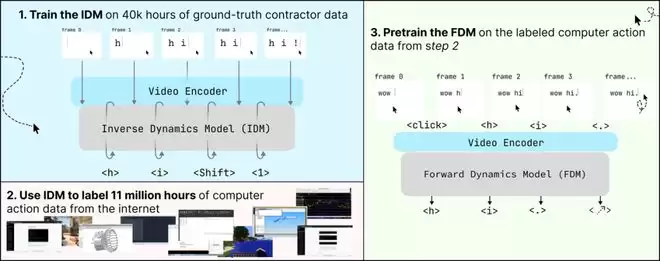
图丨FDM-1 训练方法的示意图(来源:Standard Intelligence)
与 VLM 路线形成对比的是,FDM 完全不使用链式思维推理、字节对编码或工具调用。它直接在视频和动作 token 上运作,这使得推理延迟很低,也使模型能够处理滚动、3D 建模、游戏操控等 VLM 框架难以建模的连续性任务。
评估基础设施方面,团队建了一套可运行 8 万台分叉虚拟机的系统,每小时能跑超过 100 万次 rollout。每台 VM 是一个最小化的 Ubuntu 桌面环境,配 1 个 vCPU 和 8 GB 内存;一块 H100 GPU 能同时控制 42 台。分叉机制允许他们对操作系统状态做完整内存快照并复制到新的 VM 上,从而在同一个起始状态上并行跑数千次评估。
这基本上是在把测试时计算(test-time compute)的思路用到了行为模型评估上。他们还把 GPU 和 VM 放在同一云区域、使用低延迟 VNC 配置和自定义 Rust 输入绑定,把从屏幕截取到动作执行的往返延迟压缩到 11 毫秒。
他们公布的初步评测结果显示,IDM 标注数据在鼠标操作、目标点击、符号记忆和 UI 操控等方面的表现已经超过了人工标注的承包商数据。不过在打字和语言理解任务上,IDM 数据上的进步速度慢于承包商数据,团队认为这是 IDM 标注噪声造成的,未来计划混合使用两种数据。
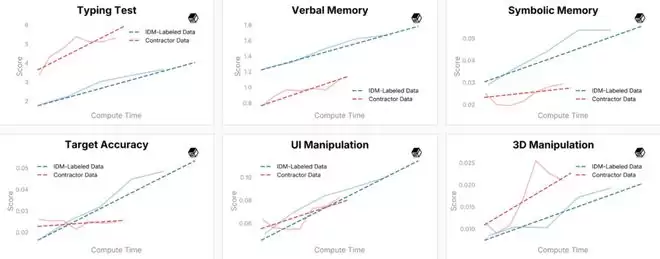
(来源:Standard Intelligence)
在自动驾驶的微调实验中,FDM-1 在不到 1 小时的驾驶数据上微调后,就能用方向键控制汽车在旧金山绕街区转弯,起始准确率为 50%(在“无操作/左转/右转”三选一中),明显高于仅有视频编码器而没有互联网视频预训练的基线模型。
关于这支团队。Standard Intelligence 于 2024 年 3 月在旧金山注册成立,自我定位为“对齐的 AGI 实验室”。研究团队的核心作者是 Neel Redkar、Yudhister Kumar、Devansh Pandey 和 Galen Mead。Neel Redkar 来自 UCLA,曾在高中时期就凭借用于碳捕获的金属有机框架神经网络获得 ISEF 大奖,在 Notion 的 AI 团队实习过,2024 年底还在 NeurIPS 上展示过文本与材料生成的跨模态研究。
Yudhister Kumar 的个人 显示他曾参与过 MATS(ML Alignment Theory Scholars,机器学习对齐理论学者)5.0 项目,研究过“预言机在合作 AI 中的应用”以及 Ramsey 理论中的非标准方法。这是一个背景相当年轻但研究嗅觉敏锐的团队。
在 FDM-1 之前,Standard Intelligence 已经有过两个引起关注的项目。一个是 2024 年中在旧金山市中心建造的 30 PB 存储集群,专门用来存放 9,000 万小时的视频数据。他们在博客中算过一笔账:如果用 AWS 存储,每年要花 1,200 万美元;通过租用旧金山的托管机房,包含折旧在内的成本降到了每年约 35.4 万美元,低了大约 40 倍。
另一个是 2024 年 11 月开源的 hertz-dev,一个 85 亿参数的全双工音频基础模型,在单张 RTX 4090 上实现了约 120 毫秒的实际对话延迟。这两个项目分别对应了 FDM-1 所需要的两个关键能力:大规模数据基础设施和跨模态学习。
回到此次推出的 FDM-1,其最大的价值或在于提出了一条与当前行业主流截然不同的技术路径。Anthropic、OpenAI、Google 的计算机操控代理本质上是“大脑外接手臂”,用已经训练好的强大语言/视觉推理模型去截图、识别 UI 元素、再生成点击指令。
这种方法的优点是可以利用现有模型的通用推理能力,缺点是操作频率低(每步都要截图-推理-动作),无法处理需要高帧率连续控制的任务,且受限于截屏分辨率下的 UI 理解。
FDM-1 则更接近端到端的行为克隆路线:直接从视频到动作,不经过语言中介。这让它天然擅长连续控制任务(比如 3D 建模中的连续拖拽、滚轮操作),但也意味着它可能缺乏 VLM 方案所拥有的抽象推理和自然语言理解能力。
目前,FDM-1 现在还远不是一个可用的产品。它没有指令跟随能力,所有演示都是模型自主探索或执行预设行为,没有任何自然语言驱动的展示。你没法用中文或英文告诉它“请打开浏览器搜索某个关键词”。
它也没有在任何公开标准化基准(如 OSWorld 或 CUB)上报告结果,所有评测都基于内部任务套件,缺乏与 Anthropic、OpenAI、Google 等主流方案的直接可比性。不使用任何语言模型能力迁移,意味着 FDM-1 可能在 CAD 建模、游戏操控、连续滚动浏览这些 VLM 完全做不了的任务上有独特优势,但也意味着产品化落地时需要解决指令理解、任务规划等一系列问题。
未来,FDM-1 代表的路线和 VLM 代理路线最终可能会趋于融合。一个能在 30 FPS 下连续操控 3D 建模软件的模型,如果加上语言条件化(language conditioning)和高级规划模块,有机会兼得两种路线的优点。
这个判断是不是成立暂且不论。但可以更加明确的是:在计算机行为建模这个赛道上,数据规模和上下文长度的重要性被严重低估了,而 Standard Intelligence 可能是第一个认真把这两个要素推向极致的团队。至于这条路最终能走多远,还需要更多定量验证、更多场景泛化、以及与 VLM 路线在真实生产任务上的正面比较。
参考资料:
1.https://si.inc/posts/fdm1/
运营/排版:何晨龙




