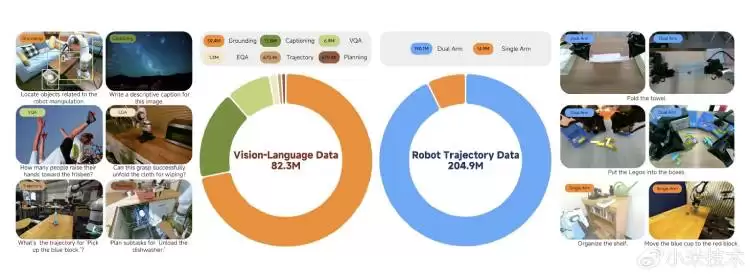
2026年2月12日,小米机器人团队正式将具身智能视觉语言动作模型Xiaomi-Robotics-0对外开源。这一模型参数量高达470亿,采用MoT混合架构,并以多模态视觉语言大模型为底座,融合了多层扩散变换器结构,成功在通用语义理解与精细化动作控制之间实现了高效协同。
在Libero、Calvin和SimplerEnv三大主流评测基准上,Xiaomi-Robotics-0在全部标准测试任务及涵盖30种模型的横向对比中,平均成绩均位列第一。该模型可在消费级显卡上完成实时推理,无需依赖专业计算设备。
训练过程中,模型同步开展跨模态预训练,完整保留了物体检测、视觉问答等基础感知能力。针对传统视觉语言动作模型因推理延迟引发的动作不连贯问题,研发团队引入异步推理机制与λ形注意力掩码技术,显著提升了响应连续性与场景适应性。实际任务验证显示,该模型在积木拆解、毛巾折叠等对精细操作与多感官协同要求较高的复杂场景中,展现出稳定可靠的手眼协调能力。




