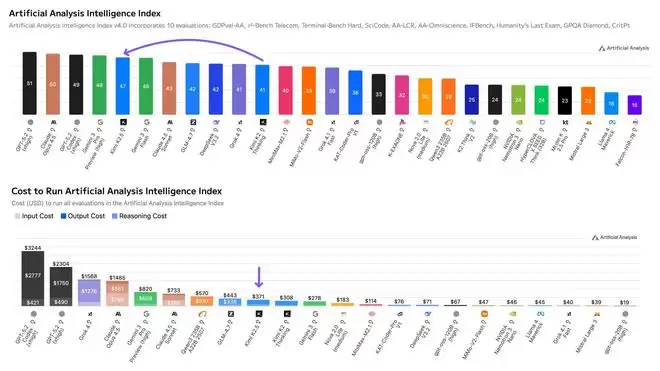
在知名第三方测评机构Artificial Analysis最新公布的大模型排名中,Kimi K2.5总体位列第五。具体得分如下:GPT5.2High得分为51,Claude Opus 4.5为50,GPT5.2CodexHigh为49,Gemini3 ProHigh为48,Kimi K2.5则为47分。
核心看点总结如下:
➜在智能体任务上表现优异:
Kimi K2.5在GDPval-AA评估中获得了1309的Elo评分,表现仅次于OpenAI和Anthropic的顶级模型,其成绩远超GLM-4.7、DeepSeek V3.2以及Gemini 3 Pro。GDPval-AA是衡量大模型核心通用智能表现的关键指标,主要用于评估大模型在实际知识工作(例如准备演示文稿和进行分析任务)中的表现。在测评中,模型通过一个名为Stirrup的智能体框架,在一个模拟智能体环境中获得了系统shell访问权限和网页浏览功能,并完成相关任务。
➜原生多模态首次实现:
Kimi K2.5是Moonshot公司首款支持图像和视频输入的原生多模态旗舰模型。作为领先的开源大模型,这是其首次实现对图像输入的原生理解能力,这在一定程度上消除了开源模型在关键应用场景上相对于前沿实验室私有模型的一个关键障碍。与DeepSeek V3.2、GLM-4.7、MiniMax M2.1和MiMo-V2-Flash等领先的开源模型相比,Kimi K2.5凭借此特性脱颖而出。在MMMU Pro视觉推理基准测试中,Kimi K2.5得分率为75%,略低于Gemini 3 Pro,但与GPT-5.2和Claude Opus 4.5的表现持平。
➜运行成本颇具竞争力:
在衡量模型综合运行成本的关键指标“运行人工智分”中,Kimi K2.5的得分为371美元,这意味着其成本比Claude Opus 4.5和GPT-5.2便宜4倍以上,但比DeepSeek V3.2和GPT-OSS-120b要贵5倍以上。
➜适中的推理令牌消耗:
Kimi K2.5的token消耗量处于同级别大模型的合理区间。在“人工智分”评估套件中,其推理过程使用了约8200万个推理token。这一数字略低于Kimi K2 Thinking(约9500万个推理令牌),远低于GLM 4.7(约1.6亿个推理令牌)。
➜实现混合推理架构:
Kimi K2.5将Moonshot的思考推理模式和非思考推理模式统一集成到一个模型架构中。本次评估已对开启推理功能的K2.5进行评估(关于关闭推理功能后的模型表现结果也将很快公布)。
➜保持较低的幻觉率:
Kimi K2.5在AA全知指数(该指标综合衡量模型的知识准确性及幻觉率)中得分为-11。这一分数主要源于其相对较低的幻觉率,仅为64%(低于Kimi K2 Thinking的74%),表明当模型对答案不确定时,Kimi K2.5更倾向于回避问题,而不是捏造信息。