
(图片来源:摄图网)
1月21日,月之暗面Kimi总裁张予曦在瑞士达沃斯举行的世界经济论坛2026年年会时坦言,“从创业第一天起我们就清醒地意识到,中国初创公司没有随意堆砌算力的条件。这迫使我们通过大量的基础研究创新来换取极致的效率。”她表示,Kimi仅动用了美国顶尖实验室1%的算力资源,便开源出了Kimi K2、Kimi K2 Thinking这样领跑全球的模型,甚至在部分性能指标上超越了美国一流的闭源模型。
张予曦解释,他们投入大量精力,将工程化思维引入研发环节,确保所有算法创新都能在生产系统中大规模稳定运行。这种创新策略让Kimi在资源有限的情况下实现了技术突破。据她透露,Kimi最新模型将很快发布。
这种以小博大的技术传奇背后,是一场系统性的效率革命。Kimi K2系列模型总参数量高达1万亿,却通过混合专家架构(MoE)将单次激活参数精准控制在320亿,运行成本仅为同类闭源产品的五分之一。在代码修复权威榜单SWE Bench Verified中,K2以65.8%的准确率刷新开源纪录,同时在数学推理、智能体任务等多维度保持领先。
自2024年末起,ChatGPT以其突破性技术在全球舞台掀起了一场人工智能革命。随之而来的,是无教大预模型(LPTMs)的涌现,它们如同春日里的竹笋般迅速生长,遍佈学术界与工业界。
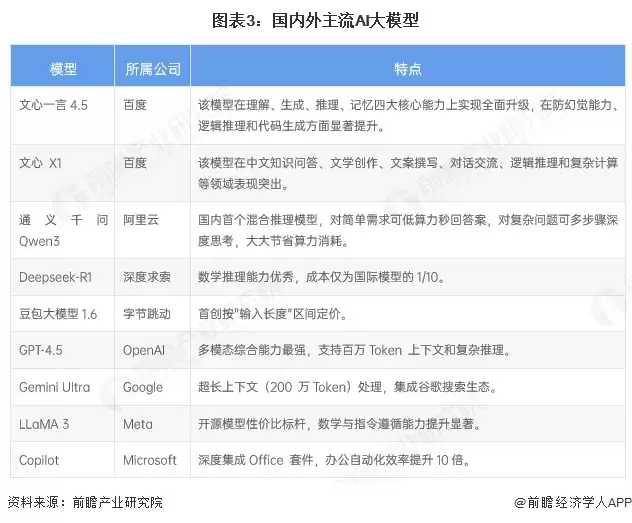
与国际巨头相比,我国AI大模型在训练成本、推理成本和硬件适配成本等方面均远低于对手。例如,DeepSeek-R1的推理成本约为OpenAI运行成本的三十分之一。2025年3月,百度正式发布文心大模型4.5及文心大模型X1。文心大模型4.5是百度首个原生多模态大模型,其多模态理解、文本和逻辑推理能力显著提升,在多项测试中表现优于GPT-4.5,API调用价格仅为GPT-4.5的1%;文心大模型X1为深度思考模型,性能对标DeepSeek-R1,调用价格约为R1的一半。
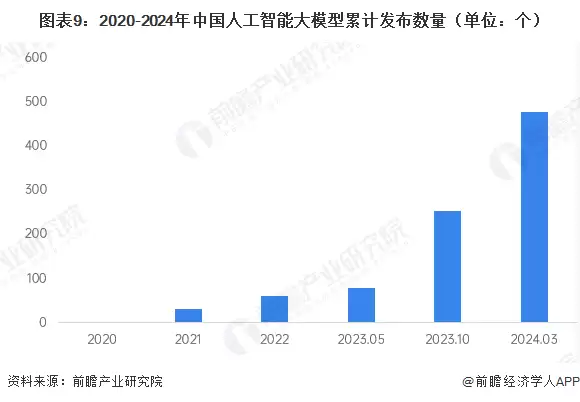
这种成本优势为中国AI大模型的市场崛起提供了有力支撑。在政策红利和市场需求下,我国大模型数量已跃居全球第二,排名仅次于美国。截至2024年第一季度,累计发布478个大模型。
统计数据显示,相关产业投融资额从约55亿元飙升至近150亿元。资金的涌入为中国AI大模型的研发和推广提供了充足动力,推动了行业的快速发展。

我国人工智能产业在规模与专利布局上已奠定全球领先地位,正步入从量变到质变的关键转型期。1月23日,国家知识产权局副局长在国新办发布会上披露,我国人工智能专利有效量已位居全球前列。
与此同时,产业主体规模持续扩大。数据显示,目前人工智能企业数量已突破6200家,大模型加速融入千行百业,并催生出更丰富的应用场景。
业内专家研判,未来大模型发展需兼顾突破与补短。其一,探索新兴大模型架构,推动从技术跟随向原创引领转型,重点布局面向具身智能的VLA模型、面向AI for Science的数理—AI融合架构等前沿方向。其二,破解高质量数据供给瓶颈,加强数据治理能力,发展基于物理约束的合成数据技术。其三,打造开放协同的产业生态,加大开源社区培育力度,推动智能体协议等关键标准制定,为迎接通用人工智能乃至超级智能时代做好准备。




