据智通财经App了解,1月26日,阿里旗下千问系列旗舰推理模型Qwen3-Max-Thinking正式亮相。据悉,Qwen3-Max-Thinking在事实知识、复杂推理、指令遵循、人类偏好对齐以及智能体能力等多个关键维度上均实现了显著提升。在19项权威基准测试中,其性能已能媲美GPT-5.2-Thinking、Claude-Opus-4.5及Gemini 3 Pro等顶尖模型。
此次推出的Qwen3-Max-Thinking引入了两项核心创新技术:
(1) 自适应工具调用能力,该系统能够按需调用搜索引擎和代码解释器等工具,该能力现已上线Qwen Chat;
(2) 测试时扩展技术,该技术显著提升了模型的推理性能,使其在关键推理基准上超越了Gemini 3 Pro。
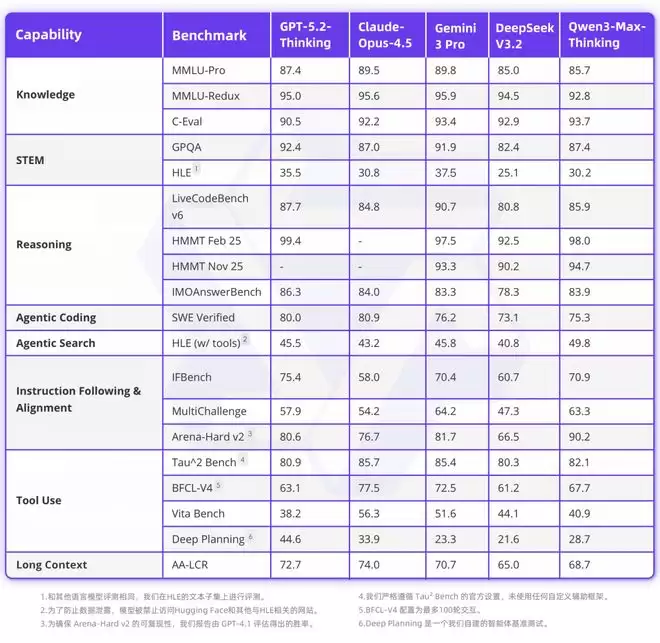
更全面的评估分数如下表所示:
自适应工具调用能力
与以往需要用户手动选择工具的方式不同,Qwen3-Max-Thinking能够在对话中自主选择并调用其内置的搜索、记忆和代码解释器功能。这一能力源于专门设计的训练流程:在完成初步的工具使用微调后,模型在多样化任务上结合规则与模型反馈进行了进一步训练。实践证明,搜索和记忆工具能有效缓解幻觉问题、提供实时信息访问并支持更个性化的回复。代码解释器则允许用户执行代码片段,并应用计算推理来解决复杂问题。这些功能共同构成了流畅且强大的对话体验。
测试时扩展技术
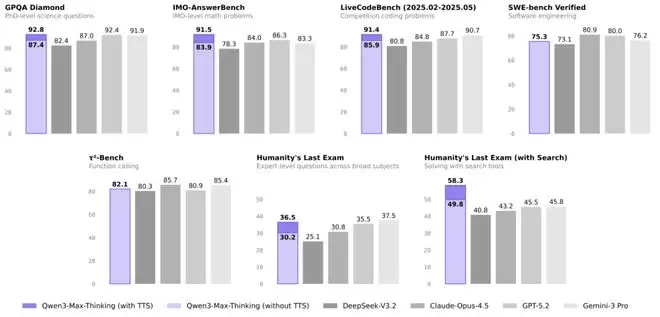
测试时扩展指的是在推理阶段分配额外计算资源以提升模型性能的技术。我们提出了一种经验积累式、多轮迭代的测试时扩展策略。不同于简单地增加并行推理路径数量(这往往导致冗余推理),我们限制并将节省的计算资源用于由“经验提炼”机制引导的迭代式自我反思。该机制从过往推理轮次中提炼关键洞见,使模型避免重复推导已知结论,转而聚焦于未解决的不确定性。关键在于,相比直接引用原始推理轨迹,该机制实现了更高的上下文利用效率,能在相同上下文窗口内更充分地融合历史信息。在总体token消耗大致相同的情况下,该方法在多个基准上持续优于标准的并行采样与聚合方法,例如GPQA(90.3 → 92.8)、HLE(34.1 → 36.5)、LiveCodeBench v6(88.0 → 91.4)、IMO-AnswerBench(89.5 → 91.5)以及HLE(w/ tools)(55.8 → 58.3)。
Qwen3-Max-Thinking现已上线Qwen Chat,用户可直接与模型及其自适应工具调用功能进行交互。同时,Qwen3-Max-Thinking的API也已开放。




