1月27日,DeepSeek公布了其新一代文档识别模型DeepSeek - OCR 2。该模型基于上一代产品升级而来,核心突破在于全新设计的视觉编码器架构。
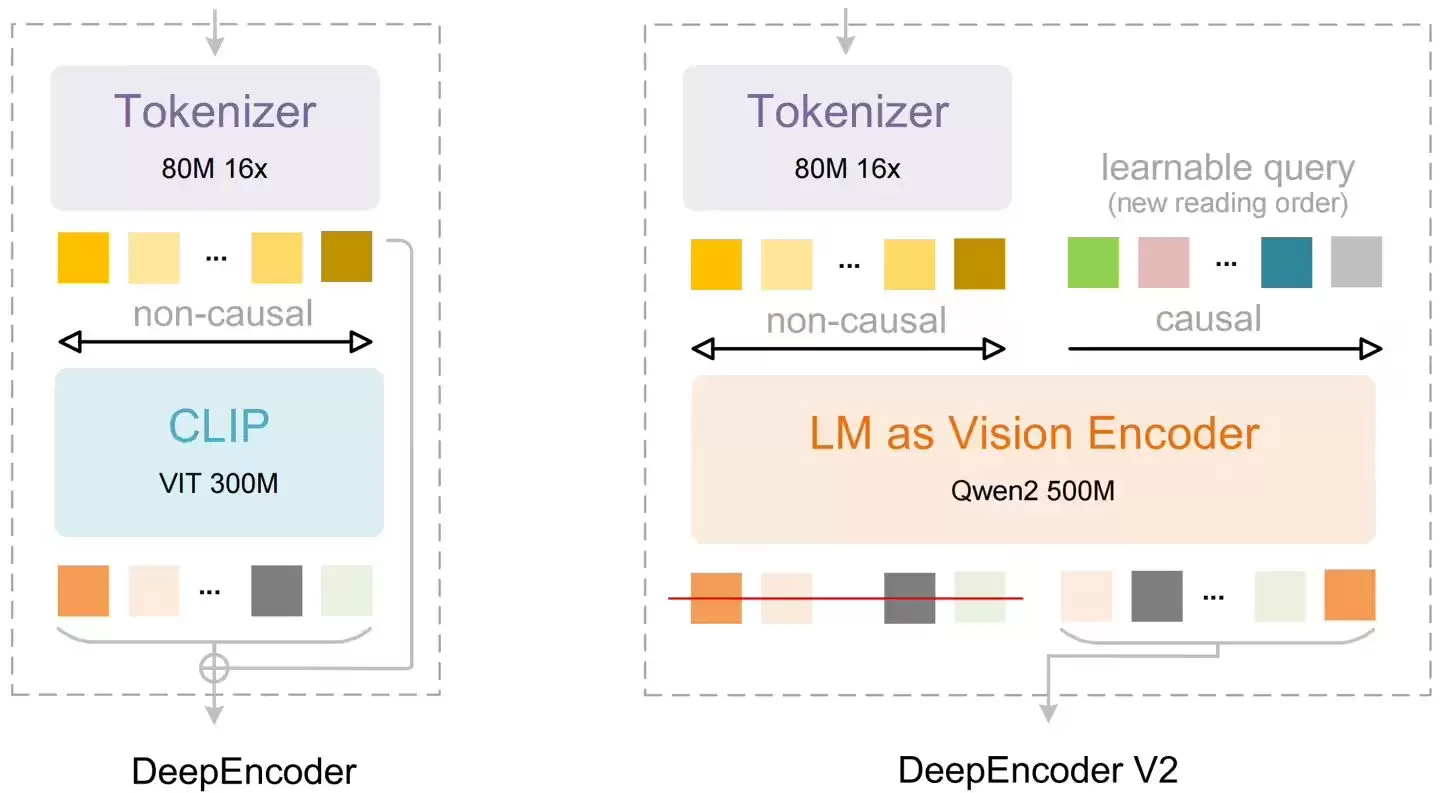
研究团队推出名为DeepEncoder V2的全新编码器结构。它能够根据图像语义动态调整视觉信息的处理顺序,让模型在识别文字之前,先对画面内容进行智能排序。这项技术创新源于对传统视觉语言模型处理方式的重新思考,旨在让机器更接近人类的视觉阅读逻辑。
在传统模型中,图像通常被分割为若干视觉单元,并按固定网格顺序送入模型处理。这种方式虽简单直接,但却有别于人类阅读文档、表格或公式时,那种基于语义和逻辑关系进行跳跃式浏览的习惯。
论文进一步指出,在版式复杂的文档场景中,视觉元素间往往存在明确的逻辑先后关系。若仅依赖空间顺序,可能限制模型对内容结构的理解能力。
DeepSeek-OCR 2的改进重点在于引入“视觉因果流”概念。团队用类语言模型结构替代了原先基于CLIP的视觉编码模块,并在编码器内部引入可学习的“因果流查询标记”。
该编码器同时包含双向注意力与因果注意力两种处理机制。原始视觉信息通过双向注意力进行全局感知,而新增的查询标记则通过因果注意力逐步建立语义顺序,从而在编码阶段对视觉单元的序列进行动态重排。最终,只有经过因果重排后的查询标记会被送入后续的解码器,用于生成识别结果。
整体架构上,DeepSeek-OCR 2延续了前代模型的编解码框架。编码器将图像转换为视觉标记并进行压缩,被压缩为较少数量的视觉单元后,再由DeepEncoder V2进行语义建模和顺序重组,最后交由一个基于混合专家架构的语言模型解码。
论文表示,该设计在不显著增加解码负担的前提下,将单页文档所使用的视觉标记数量控制在256至1120之间,与前代模型及同类系统的资源开销保持相近水平。
为验证模型性能,研究团队在OmniDocBench基准上进行了全面评估。该基准覆盖多种类型的中英文文档,包括学术论文、杂志、报告等,重点考察文本识别、公式解析、表格结构还原以及阅读顺序等指标。
测试结果显示,在视觉标记上限更低的情况下,DeepSeek-OCR 2的整体得分达到91.09%,相比前代提升了3.73%。尤其在阅读顺序准确性方面,编辑距离从0.085降至0.057,表明新模型能够更合理地理解文档内容结构。
该模型在生产环境中也表现出更好的稳定性。在线用户日志图像的重复率从6.25%降至4.17%,批处理PDF数据的重复率从3.69%降至2.88%。这些改进使得模型在保持高压缩率的同时,提升了实际应用场景中的可靠性。




