
本图片由AI技术生成
1月16日,美团LongCat团队正式宣布,其最新模型LongCat-Flash-Thinking-2601现已面向开源社区发布。
美团方面表示,作为LongCat-Flash-Thinking模型的升级版本,新模型在智能体搜索、智能体工具调用、工具交互推理等核心评测基准上,均达到了开源模型领域的领先水平。
据介绍,该模型在工具调用的泛化能力方面优势尤为明显。在面对依赖工具调用的随机复杂任务时,其性能表现超越了Claude-Opus-4.5-Thinking,能够大幅降低实际应用场景中新工具的适配训练成本。同时,新模型支持创新的“重思考”模式,可同时启用八条独立的推理线程来协同解决问题。
新增的“重思考”模式,让“龙猫”具备了“谋定而后动”的深度决策能力。
具体来看,当遇到高难度问题时,新模型会将整个思考过程拆分为“并行思考”和“总结归纳”两个阶段同步推进:
在并行思考阶段,就像人类面对难题时会同时尝试多种解法一样,启用“重思考”模式的模型会在保证思路多样性的前提下,独立梳理出多条推理路径,并行地寻找最优解;而在总结归纳阶段,模型则会对多条推理路径进行梳理、优化与整合,并将优化结果重新输入,形成闭环迭代,推动思考持续深化。
除此之外,LongCat团队在新模型中加入了额外的强化学习环节,针对性打磨模型的总结归纳能力,从而使LongCat-Flash-Thinking-2601真正实现了“想清楚再行动”的结果。
经评估,LongCat-Flash-Thinking-2601模型在编程、数学推理、智能体工具调用、智能体搜索等多个维度上均表现出色。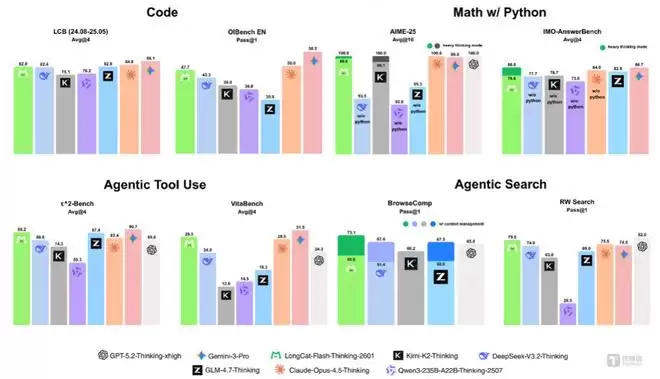
LongCat-Flash-Thinking-2601模型的平均性能比较,图片来源:美团
为了更准确地测试智能体模型的泛化能力,团队提出了一种新的评测方法——通过构建一套自动化任务合成流程,允许用户基于给定的关键词,为任意场景随机生成复杂任务,并为每个生成的任务配备相应的工具集与可执行环境。
由于这类环境中的工具配置具有高度随机性,该方法可通过评估模型在此类环境中的性能表现,有效衡量其泛化能力。
实验结果表明,LongCat-Flash-Thinking-2601在大多数任务中均保持了领先的性能优势。
对于新模型的技术思路,LongCat团队解释道,传统智能体训练往往局限于数个简单的模拟环境,这带来的问题如同只在靶场训练的士兵,到了真实“战场”可能会出现不适应。
而基于“环境扩展+多环境强化学习”这一核心技术,团队为模型打造了多样化的“高强度练兵场”,构建了多套高质量训练环境,并在每套环境中集成60余种工具,形成密集的依赖关系图谱与复杂联动,从而支撑起高度复杂的任务场景。
实践证明,训练环境越丰富,模型在未知场景中的泛化能力就越强。得益于此方案,LongCat-Flash-Thinking-2601在智能体搜索、智能体工具调用等核心基准测试中稳居前列。
LongCat团队称,在复杂随机的分布外任务中,LongCat-Flash-Thinking-2601的性能优于Claude-Opus-4.5-Thinking。




