1月16日消息,美团旗下的LongCat团队今天正式发布了开源的LongCat-Flash-Thinking-2601模型。
根据美团团队的介绍,作为LongCat-Flash-Thinking模型的升级版本,LongCat-Flash-Thinking-2601在智能体搜索、工具调用以及工具交互推理等核心评测基准上,均达到了当前开源模型的领先水平。

美团方面表示,该模型尤其在工具调用方面展现出卓越的泛化能力,在依赖于工具调用的随机复杂任务中,其性能超越了Claude,能够显著降低真实场景下适配新工具的专项训练成本。同时,它也是首个完整开源并支持在线免费体验“深度思考模式”的模型,能够启动多个推理线程并行运转,确保思考周全、决策可靠。
得益于全面升级的“深度思考”模式,当遇到高难度问题时,模型会把思考过程拆分为并行思考和总结归纳两步来完成:
在并行思考阶段,模型会同时独立梳理出多条推理路径,就像人面对难题时会琢磨不同解法一样,还会特意保证思路的多样性,以免遗漏最优方案。而在总结归纳阶段,它会对多条路径进行梳理、优化与整合,并将优化结果重新输入,形成闭环迭代推理,持续推动思考深化。
除此之外,美团还专门设计了额外的强化学习环节,有针对性地打磨模型的总结归纳能力,让LongCat-Flash-Thinking-2601真正实现“想清楚再行动”。
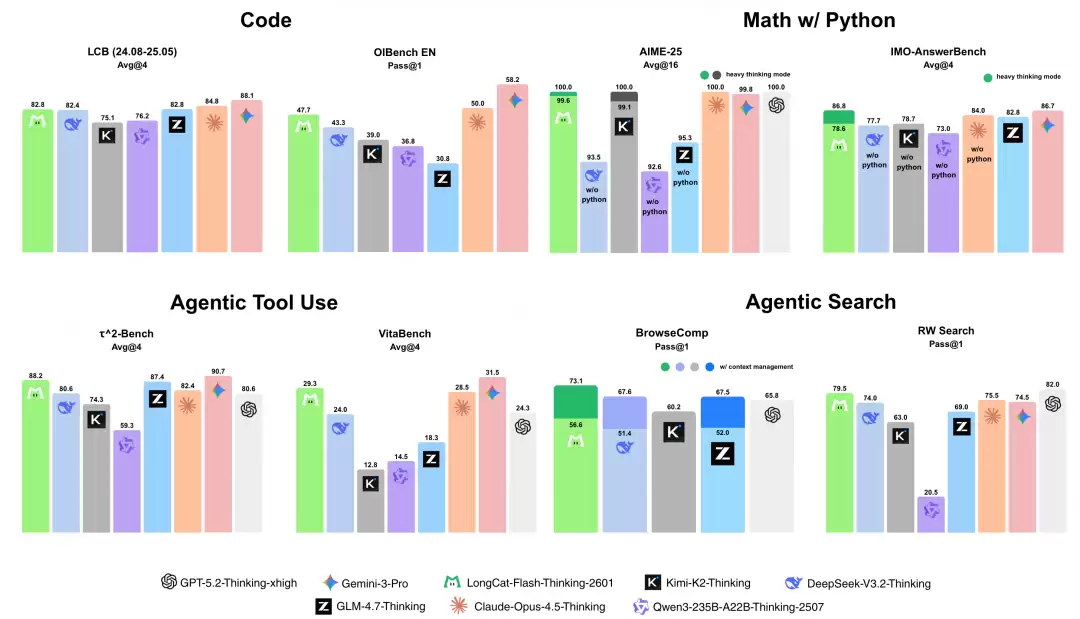
美团表示,经过全面严谨的评估显示,LongCat-Flash-Thinking-2601模型在编程、数学推理、智能体工具调用以及智能体搜索等维度的表现全面领先:
编程能力方面:LongCat-Flash-Thinking-2601在LCB评测中取得82.8分,OIBench EN评测获得47.7分,成绩处于同类模型第一梯队,展现出扎实的代码基础能力。数学推理能力:在开启深度思考模式后表现突出,LongCat-Flash-Thinking-2601在AIME-25评测中获得满分,IMO-AnswerBench中则以86.8分达到当前先进水平。智能体工具调用能力:在τ²-Bench评测中拿到88.2分,VitaBench评测中获得29.3分,均获得开源领域的领先水准,在多领域工具调用场景下表现优异,适配实际应用需求。智能体搜索能力:在BrowseComp任务中取得73.1分,RW Search评测获79.5分,LongCat-Flash-Thinking-2601具备强劲的信息检索与场景适配能力,达到开源领先水平。
同时,为了更好地测试智能体模型的泛化能力,美团还提出了一种全新的评测方法——通过构建一套自动化任务合成流程,支持用户基于给定关键词,为任意场景随机生成复杂任务。每个生成的任务都配备了对应的工具集与可执行环境。
由于这类环境中的工具配置具有高度随机性,美团通过评估模型在该类环境中的性能表现,来衡量其泛化能力。实验结果表明,LongCat-Flash-Thinking-2601在绝大多数任务中保持领先性能,印证了其在智能体场景下强大的泛化能力。
最新开源地址为:
GitHub,Hugging Face,ModelScope,API开放平台以及正式站点。




