印度169PI公司近期推出了一款名为Alpie的大型语言模型,该模型因其出色的表现被外界誉为“印度版DeepSeek”。目前,这款模型已在多个开源平台正式发布,并同步开放了便捷的API接口,供开发者集成使用。
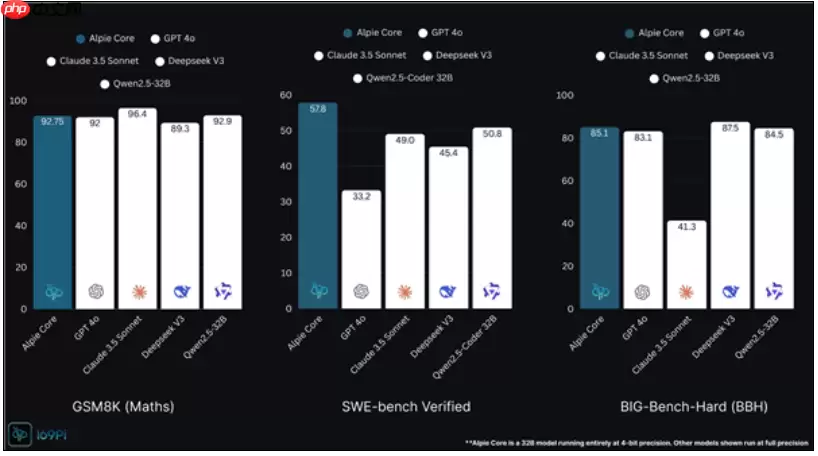
Alpie作为一款定位轻量级的大模型,其参数量达到320亿。它的核心亮点在于原生支持4bit量化技术。别看模型规模不大,它在多项权威AI基准测试中却展现出了令人惊讶的强劲实力:在GSM8K数学推理榜单上,其得分超越了知名的DeepSeek-V3,与GPT-4o、Qwen-2.5-30B等模型同处第一梯队,仅以微小差距落后于Claude-3.5。
在SWE(软件工程)专项能力榜单中,Alpie的表现更为突出,一举夺魁,成功超越了包括Claude-3.5在内的诸多主流竞品。而在更为复杂的BBH推理评测中,它同样表现优异,得分超过了GPT-4o、Qwen-2.5以及Claude-3.5等顶尖模型,仅稍稍落后于DeepSeek-V3。
当然,围绕Alpie也并非没有争议。需要指出的是,它并非由印度本土团队从零开始训练而成,其本质是基于中国的开源大模型DeepSeek-R1-Distill-Qwen-32B进行了深度的二次优化与蒸馏。换句话说,它是在中国开源大模型的基础上,通过知识蒸馏与量化压缩技术衍生出的产物。
这种技术路径带来了显著的现实优势:其研发与部署成本被大幅压缩,据称仅为GPT-4o的十分之一;同时,模型显存占用减少了75%,仅需配置16到24GB显存的GPU,即可实现流畅的推理运行。




