IT之家 1 月 6 日消息,智元具身研究中心提出 SOP(Scalable Online Post-training)—— 一套面向真实世界部署的在线后训练系统。最新称,这是业界首次在物理世界的 VLA 后训练中,系统性地融合在线学习、分布式架构与多任务通才性,使机器人集群能够在真实环境中持续进化,让个体经验在群体中高效复用,从而将“规模”转化为“智能”。

IT之家附最新介绍如下:
01、真实世界中的规模化智能增长挑战
要在真实世界中大规模运行,通用机器人必须同时满足两个看似矛盾的要求:
在复杂多变的环境中保持稳定性与可靠性在处理差异巨大的任务时,仍具备良好的泛化能力
现有 VLA 预训练模型已经提供了强大的通用性。但真实世界的部署受困于更高的任务专精度要求,以及离线数据采集方式的边际效益递减,往往需要通过后训练获得更高的任务成功率。遗憾的是,当前主流的 VLA 后训练方法仍受离线、单机、串行采集等因素制约,难以支撑高效、持续的真实世界学习。
这些限制并非源自具体算法,而是来自学习范式本身。
02、SOP:分布式在线后训练框架
SOP 的核心目标,是让机器人在真实世界中实现分布式、持续的在线学习。
我们将 VLA 后训练从“离线、单机、顺序”重构为“在线、集群、并行”,形成一个低延迟的闭环系统:多机器人并行执行 → 云端集中在线更新 → 模型参数即时回流。
1.SOP 架构设计
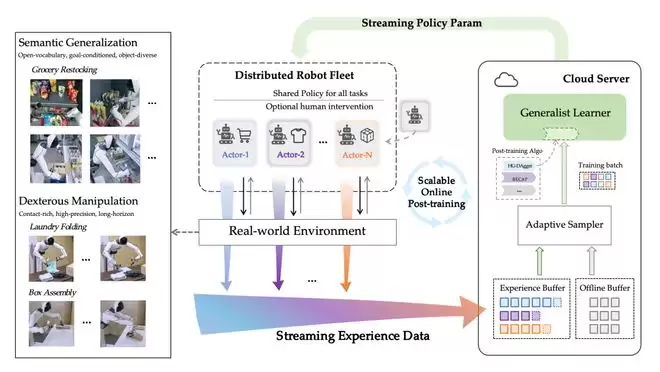
SOP 采用 Actor–Learner 异步架构:
Actor(机器人侧)并行经验采集
多台部署了同一 policy 模型的机器人(actors)在不同地点同时执行多样任务,持续采集成功、失败以及人类接管产生的交互数据。每台机器人的经验数据被汇总传输至云端 Experience Buffer 中。
Learner(云端)在线学习
所有交互轨迹实时上传至云端 learner,形成由在线数据与离线专家示教数据组成的数据池。
系统通过动态重采样策略,根据不同任务的性能表现,自适应调整在线 / 离线数据比例,以更高效地利用真实世界经验。
即时参数同步
更新后的模型参数在分钟级别内同步回所有机器人,实现集群一致进化,维持在线训练的稳定性。
SOP 本身是一套通用的框架,可以即插即用的使用任意后训练算法,让 VLA 从在线经验数据中获益。我们选取 HG-DAgger(交互式模仿学习)与 RECAP(离线强化学习)作为代表性算法,将其接入 SOP 框架以进化为分布式在线训练。
2.关键优势
高效状态空间探索
分布式多机器人并行探索,显著提升状态–动作覆盖率,避免单机在线学习的局限。
缓解分布偏移
所有机器人始终基于低延迟的最新策略进行推理采集,提升在线训练的稳定性与一致性。
在提升性能的同时保留泛化能力
传统的单机在线训练往往会使模型退化为只擅长单一任务的“专家”,SOP 通过空间上的并行而非时间上的串行,在提升任务性能的同时保留 VLA 的通用能力,避免退化为单任务专家。
3.实验评估:性能提升与预训练的关系
我们围绕三个问题系统评估 SOP:
1、SOP 能为预训练 VLA 带来多大性能提升?
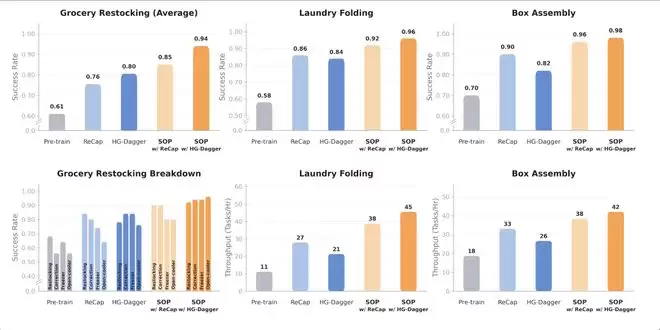
实验结果说明,在各类测试场景下,结合 SOP 的后训练方法均得到了显著的性能提升。相比预训练模型,结合 SOP 的 HG-Dagger 方法在物品繁杂的商超场景中实现了 33% 的综合性能提升。对于灵巧操作任务(叠衣服和纸盒装配),SOP 的引入不仅提升了任务的成功率,结合在线经验学习到的错误恢复能力还能明显提升策略操作的吞吐量。
结合 SOP 的 HG-Dagger 方法让叠衣服的相比 HG-Dagger 吞吐量跃升 114%。SOP 让多任务通才的性能普遍提升至近乎完美,不同任务的成功率均提升至 94% 以上,纸盒装配更是达到 98% 的成功率。
SOP 性能提升
为了进一步测试真机 SOP 训练后 VLA 模型是否达到专家级性能,我们让 SOP 训练的 VLA 模型进行了长达 36 小时的连续操作,模型展现出了惊人的稳定性和鲁棒性,能够有效应对真实世界中出现的各种疑难杂症。
完整视频请访问我们的 :
2、机器人规模如何影响学习效率
我们使用了三种机器人队伍数量(单机、双机、四机配置),在同样的数据传送总量的基础上,进行了比较。实验结果表明,在相同的总训练时间下,更多数量的机器人带来了更高的性能表现。在总训练时间为 3 小时的限制下,四机进行学习的最终成功率达到了 92.5%,比单机高出 12%。我们认为,多机采集可以有效阻止模型过拟合到单机的特定特征上。同时,SOP 还将硬件的扩展转化为了学习时长的大幅缩短,四机器人集群相比单机能够将模型达到目标性能的训练速度增至 2.4 倍。

SOP 学习效率提升
3、不同预训练规模下 SOP 是否稳定有效?
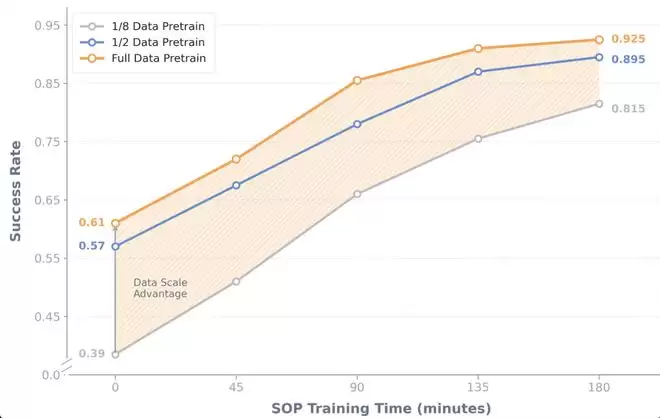
最后,我们探究了 SOP 和预训练数据之间的关系。我们把总量为 160 小时的多任务预训练数据分为了三组:20 小时,80 小时和 160 小时,分别训练一组初始模型后再进行 SOP。我们发现,预训练的规模决定了基座模型和后训练提升的轨迹。SOP 能为所有初始模型带来稳定的提升,且最终性能与 VLA 预训练质量正相关。
同时,对比 80 小时和 160 小时实验效果,我们也可以明显注意到,在解决特定失败情况时,在轨策略经验带来了非常显著的边际效果。SOP 在三小时的在轨经验下就获得了约 30% 的性能提升,而 80 小时额外人类专家数据只带来了 4% 的提升。这说明在预训练出现边际效应递减的情况下,SOP 能够高效突破 VLA 性能瓶颈。
SOP 在不同预训练数据规模下的对比
4.部署即进化:重塑机器人生命周期
最后我们将机器人队伍放到了预训练模型没有见到的真实新环境下执行任务,并使用 SOP 进行在线训练。
当机器人被置于不同的环境时,即便是同样的任务,起初成功率和吞吐量如预期般下降,但在 SOP 介入仅仅几个小时后,机器人的性能便显著回升,能够鲁棒地执行相对复杂的实际任务。
结语
SOP 改变的不仅是训练范式,更是机器人系统的生命周期。我们相信机器人不应当是“性能固定的标品”,而是“在真实世界中持续提升的生命体”。部署不是技术迭代的终点,而是更大规模学习的起点。如果说 VLA 让机器人第一次具备了通用理解与行动能力,那么 SOP 所做的是让众多机器人的经验共同驱动智能的快速成长。训练不被锁死在过去,智能成长在当下。




