作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。

图 | 徐玉庄(来源:徐玉庄)
由其担任第一作者的一篇论文于近日被 AAAI 2026 接收,在论文中他和所在团队打造出一种名为 CAMERA 的新技术,该技术能在短短五分钟,为一个拥有 570 亿参数的巨型模型 Qwen2-57B-A14B 完成一次全面的冗余检查,并在此基础上进行高效的修剪和压缩,从而让大模型在手机、平板等小型设备上的高效运行距离普通人更进一步。
徐玉庄告诉 DeepTech:“我们的方法能够实现精准剪枝 20% 后模型效果几乎无损。我甚至有一个或许还值得讨论的提议就是,基础模型训练团队可以用我们这个分析框架判断自己的模型是不是充分训练了,如果没有或许值得多训一些。”
思维大转变:从修剪枝叶到修剪神经元
此次成果要解决的问题是:想象一下,你有一个由上百位不同领域的专家组成的超级智库,每当你问一个问题,一个聪明的调度员就会根据问题类型,立刻叫出其中几位最擅长的专家来为你解答。这就是当前的大模型内部的一种名为混合专家模型的先进工作方式,它让 AI 拥有了处理海量知识和复杂任务的能力。
然而,这个超级智库有一个幸福的烦恼:专家太多了。虽然每次只需要激活几位,但是所有专家的知识储备也就是模型参数都需要时刻准备着,这会带来惊人的计算消耗和存储成本。
更关键的是,人们发现增加专家数量带来的性能提升,远不如增加的成本那么明显,这意味着智库里存在大量的冗余或不那么关键的知识。
而徐玉庄等人就像是给这个巨型大脑做手术的神经外科医生,他们发现了一种更加精妙的手术方案,不仅能让大模型大幅瘦身,还能保持甚至提高其智商。
(来源:资料图)
在过去,人们为了让混合专家模型(MoE,Mixture of Experts)瘦身,主要采用两种粗放式的方法:
第一种方法是专家级修剪,即直接砍掉整个专家,就好比由于某个专家的偶尔懒散,因此把他的整个团队解散了,但这难免会丢失重要知识;
第二种方法是专家级合并,即把几个看似相似的专家合并为一个,这就像让一位文学教授去教高等数学,往往效果不佳。
这些方法之所以效果有限,是因为它们要么把一个专家当做不可分割的整体来决定去留,要么仅局限于对单个参数矩阵进行孤立地压缩。但是,徐玉庄等人想到一个更加本质的视角:为什么不看得更细一点呢?
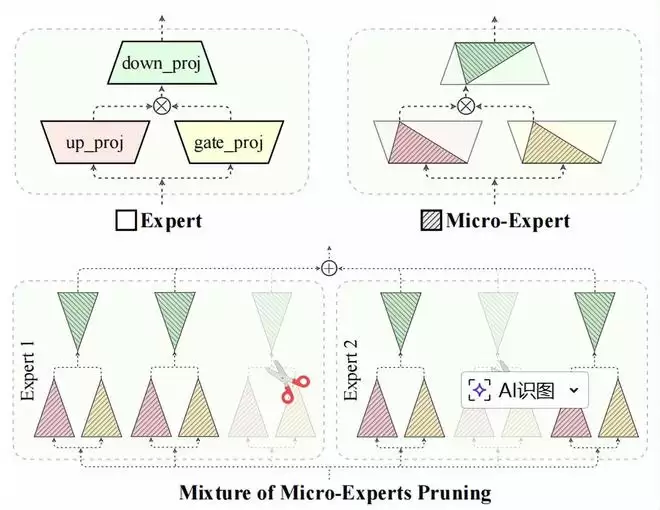
基于此,他们提出了微专家这样一个全新的概念。如果把每个专家看做一个功能部门,那么微专家就是这个部门里最基础的、一个个独立负责具体任务的神经元或工作小组。
关键在于,一个微专家是由跨三个矩阵的特定行列共同定义的,它们通过协同工作完成了一个最基础的知识转换动作。
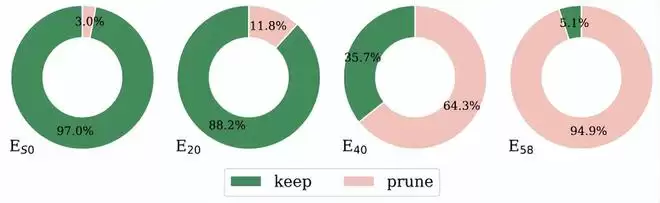
整个 MoE 层的输出,实际上是所有微专家工作成果的加权综合。徐玉庄等人的核心发现是:在不同的任务场景下,这些微专家的贡献天差地别。大部分输出其实是由一小部分至关重要的微专家决定的,而很多微专家则贡献甚微,存在大量的冗余和马太效应。
这就好比在解答如何做番茄炒蛋这一问题时,负责烹饪技巧和食材特性的微专家大放异彩,而负责量子物理的专家则几乎在围观。
传统的粗放修剪可能会误伤重要的烹饪专家,或者把量子物理专家硬塞进烹饪团队。而 CAMERA 的思路是:精准定位每一个围观或者低效的微专家,然后以几乎无伤害的方式剔除它。
(来源:资料图)
CAMERA 算法:给每个微专家打分的智能秤
那么,如何从数以万计的微专家中,快速准确地找出谁重要、谁冗余呢?这听起来像是一个超级复杂的组合优化问题,在数学上被证明是 NP 难题,即无法在短时间内精确求解。
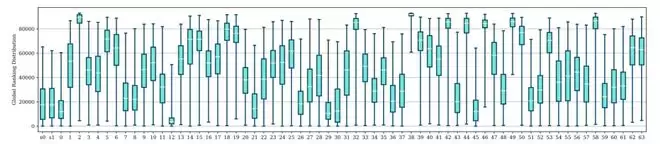
但是,徐玉庄等人的巧思在于:他们设计了一个极其巧妙的近似估计算法,为每个微专家定义了一个能量指标。
这个能量由两部分决定:
第一部分是激活系数,它指的是当模型处理不同问题的时候,这个微专家被调用的频繁程度和强度;第二部分是权重向量范数,它指的是微专家自身知识储备的规模大小。
一个微专家的能量越高,意味着它越经常得到使用,而且自身承载的知识量越大,也就越重要。相反,能量极低的,就是可以优先考虑修剪的冗余部分。
CAMERA 算法利用一个很小的校准数据集比如 128 段文本,就能在几分钟内为模型所有层中的所有微专家计算出来能量并进行排序。这就像使用一把智能秤,可以快速地称出来每个工作小组的贡献度。
更令人赞叹的是,他们从数学上证明了基于这种能量排序的修剪策略,其效果与理论上的最优的压缩方法之间的差距不仅很小而且是可控的,这为 CAMERA 的可靠性和有效性提供了坚实的理论背书。
(来源:资料图)
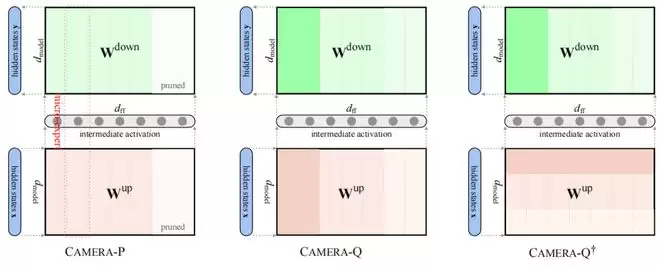
CAMERA-P:一把精准的大模型手术刀
有了精准的微专家能量排名,就可以开始做手术了,这就是 Camera-P,P 指的是 Pruning,也就是修剪的意思。
Camera-P 的目标是:按照设定的比例比如 20% 或者 40%,移除能量最低的那部分微专家。具体操作非常的结构化,对于一个被选中的冗余微专家,Camera-P 会将其对应的三个矩阵中的特定行或特定列同时置零或直接剪除。
这样做的好处是显而易见的:
首先,可以保持功能完整,避免了过去单独修剪某个矩阵可能造成的功能失调;其次,可以真正实现加速推理,被置零的权重在计算时会被跳过,这直接可以减少计算量,提高模型的运行速度;再次,无需进行重新训练,整个过程是训练后的,无需使用大量数据来重新训练模型。
实验结果表明:Camera-P 在多个主流 MoE 模型上比如 DeepSeek-MoE-16B、Qwen2-57B 上,从 20% 到 60% 的不同修剪比例下,在语言理解、常识推理、数学问题等 9 项任务上的表现,都超越了之前最好的方法。尤其在高达 60% 的激进修剪下,模型性能下降远远小于其他方法,展现了惊人的鲁棒性。
(来源:资料图)
CAMERA-Q:给重要知识进行高保真,给次要知识省空间
除了直接修剪,另一种常见的模型压缩技术是量化,即降低存储每个权重数值所需的比特位数,比如从 16 比特降低到 4 比特,这就像把高清无损音乐转换成 MP3,在尽量保持听感的同时大幅减少文件体积。
现有的 MoE 量化方法主要是在专家级别分配不同的精度也就是比特数,比如给活跃的专家高精度,给不活跃的专家低精度。但是,徐玉庄等人认为这仍然不够精细,每个专家内部也有重要的微专家和次要的微专家。
于是,他们提出了 CAMERA-Q,Q 指的是 Quantization,就是量化的意思。它利用 CAMERA 得到全局微专家的能量排名,然后在每个专家内部进行混合精度分配。
具体来说:能量排名最高的那一小部分微专家,分配较高的比特位,精心保留其知识细节;能量中等的那一小部分微专家,分配标准的比特位比如 2 比特;能量最低的那一小部分微专家,分配较低的比特位比如 1 比特,从而可以大大节省空间。
这种方法的精妙之处在于,它确保了每个微专家内部三个矩阵的精度是一致的,避免了好比“一条腿穿皮鞋,一条腿穿草鞋”的尴尬,维护了基本功能单元的完整性。
实验证明,这种微专家感知的量化策略,在激进的 2 比特平均精度下,效果显著优于传统的专家级量化方法。
CAMERA 技术的意义远不止于学术论文中的漂亮数据。它为解决大模型落地应用的核心瓶颈——计算成本与存储开销提供了一套高效、实用的解决方案。
(来源:资料图)
徐玉庄表示:“在路线上,我们首次把大模型的压缩单元从一个权重矩阵内部扩展到了跨越多个权重矩阵的情形,首次把微专家这个功能完备的微结构作为剪枝或混合精度配置对象。”
在方法论上,这一研究也首次在数学上给出混合微专家的简洁表示形式,首次描述微专家压缩这一最优化问题并给出一个还算简单有效的解决方案。
未来,人们或许能在手机、平板电脑甚至智能手表上,运行如今需要庞大算力支撑的尖端 AI 模型。CAMERA 技术能让这些模型在保持高性能的同时,体积更小、耗电更少、响应更快。
对于提供 AI 服务的公司来说,模型压缩意味着可以用更少的服务器资源来服务更多的用户,从而可以降低运营成本,最终可能让 AI 服务的价格得到降低。
在生物、医药、材料等需要复杂 AI 模拟的科研领域,研究者们往往受限于计算资源,而更加轻量级的强大模型,能让更多科研机构参与前沿探索。
CAMERA 尤其是 CAMERA-P 还可以和其他模型压缩技术进行无缝结合,从而实现组合拳般的效果,进而达到更高的压缩率。
如前所述,徐玉庄目前在哈尔滨工业大学读博。此外,他也在以端侧大模型业务见长的面壁智能担任实习算法研究员。未来,他将继续深耕大模型领域。
参考资料:
相关论文 https://arxiv.org/pdf/2508.02322
运营/排版:何晨龙




