12月24日,据IT之家消息,阿里通义今日正式发布Qwen3-TTS家族的两款新模型:声音创作模型Qwen3-TTS-VD-Flash和声音克隆模型Qwen3-TTS-VC-Flash。两款模型的核心亮点整理如下:
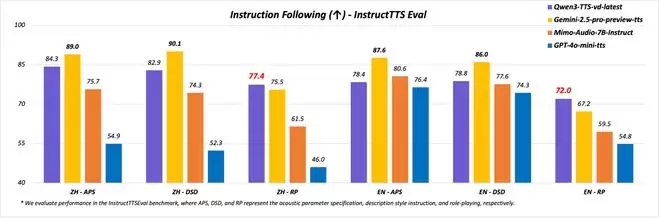
声音创作:Qwen3-TTS-VD-Flash能够理解复杂的自然语言指令,实现对音色、韵律、情感乃至人物设定的精细化调控,真正掌握从“说什么”到“如何说”的完整表达。用户得以自由定义想要的声音效果,彻底摆脱只能依赖现有音色进行克隆,或从有限预设音色库中做选择的束缚。在InstructTTS-Eval评测中,其综合表现显著优于GPT-4o-mini-tts和Mimo-audio-7b-instruct;在角色扮演测试中,其表现也超越了Gemini-2.5-pro-preview-tts。
声音克隆:Qwen3-TTS-VC-Flash支持仅需3秒音频即可完成高质量的语音克隆,并能在克隆音色的基础上,流畅生成中文、英文、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、法语、俄语等全球十大主流语言的语音。在MiniMax TTS多语言测试集上,其平均词错误率(WER)全面低于MiniMax、ElevenLabs及GPT-4o-Audio-Preview,展现出优异的准确性。
高表现力:无论是Qwen3-TTS-VD-Flash还是Qwen3-TTS-VC-Flash,均能生成高度拟人化、富有表现力的音色。它们能够稳定可靠地输出与输入文本高度契合的语音内容,并能根据文本语义自动调节语气节奏,呈现出自然生动的表达效果。
鲁棒的文本能力:Qwen3-TTS-VD-Flash和Qwen3-TTS-VC-Flash具备强大的文本解析能力,可自动处理复杂的文本结构,精准提取关键信息。面对多样化、非规范的文本格式时,两者均展现出较强的鲁棒性(IT之家注:robustness,指系统在内部结构或外部环境发生变化时,维持功能稳定运行的能力)。
定制化声音形象:Qwen3-TTS支持通过自然语言描述生成定制化的声音形象。用户可以随意输入声学属性、人设描述、背景信息等自由描述,轻松创造出符合自己期望的声音形象。
可控生成:在InstructTTS-Eval评测中,Qwen3-TTS的综合表现显著优于GPT-4o-mini-tts和Mimo-audio-7b-instruct,在角色扮演测试中也超越了Gemini-2.5-pro-preview-tts,显示出精准的指令跟随与生成控制能力。
高效语音克隆:Qwen3-TTS支持仅凭约3秒的音频样本实现高质量的语音克隆,并可基于克隆出的音色生成多语种语音。同时,模型对复杂文本和带有噪音的原始音频都具有较高的鲁棒性。
多语种声音克隆:在MiniMax TTS多语言测试集上,Qwen3-TTS在中文、英文、法语、意大利语等各项评测中的内容稳定性优于MiniMax、ElevenLabs及GPT-4o-Audio-Preview;其平均词错误率(WER)在所有参评模型中排名第一。

相关文档:Qwen3-TTS-Voice-Design API 文档
相关文档:Qwen3-TTS-Voice-Clone API 文档




