
AI 的竞争成为模型公司全栈能力和创新的博弈。
文丨江思远
2000 年,美国互联网泡沫破灭时,Google 面临巨大的商业化压力。当时他们搜索引擎的流量暴涨,但离盈利还有一段距离。Google 曾尝试把自己的技术授权给友商,以赚取微薄的 “经费”。但还是无法支撑公司的长远发展。
公司作为商业组织本质是逐利的。但有技术信仰的企业,往往会在短期利益与长期投入之间,选择那条更难、更慢、也更烧钱的路径。
Google 没有放弃技术。2002 年,Google 的工程师们发现,用户在搜索框中输入关键词,不只是为了搜寻信息,也是在表达购买意图。Google 将 “用户搜索意图” 与 “商业广告” 通过竞价排名结合,在行业中找到了一个独特的身位,将技术和商业化真正连接了起来。
伟大的技术突破往往能带企业打开新的市场。苹果未止步于个人电脑,而缔造出了划时代的 iPhone;字节跳动抓住推荐算法,才完成对信息流的重构;OpenAI 固执地进行大模型训练,让算法涌现出了智能。
但过去两年,AI 技术受困于找不到落地场景,商业化受阻。2025 年,DeepSeek 在保持成本优势的同时,展现出接近人类的思考能力,让 C 端用户对 AI 的价值有了新的认知。不久后,OpenAI 的原生多模态模型 GPT-4o,展现了其对图片内容的理解能力,让 AI 生成 “吉卜力” 画风的图片引爆社交网络。
AI 技术的进展带来了解决以下两大难题的可能性,让市场重新评估 AI 的商业潜力。
- 物理: AI 对真实世界的理解和执行能力不足。
- 商业: 推理成本过高,限制了 AI 的大规模应用。
2025 年底,百度发布文心大模型 5.0,Google 发布 Gemini 3,模型实现在统一原生架构下能理解图片、看懂视频,大模型统一原生多模态的潜力被逐步看到。
技术进步也带来商业化的可能。目前,大模型有望通过算法层、架构层、系统层,乃至芯片侧的全栈优化,降低推理成本,提高模型效能,如 Anthropic 的 Claude 系列、Google 的 Gemini 系列、百度文心系列。
AI 行业的竞争不止在于算力、数据,也成为一个公司全栈工程能力和基础创新的综合博弈。
AI 能力正从文本生成走向原生多模态
大模型还无法做到完全理解用户的意图,但语言模型正在进入 “收益平台期”——尽管算力、数据投入指数级增加,但大模型在预测下一个 Token 的任务上,所表现出的泛化性曲线已明显放缓。单一文本维度的缩放路径,无法满足大模型智能继续进化的目标。
业界一个广泛流传的观点是,大模型要理解世界。“现在的大模型达不到 AGI”,大模型理解世界,需要视觉、听觉、语言等多种感官信息的融合。两位图灵奖得主,杨立昆、Geoffrey Hinton 都曾提出类似的观点。
目前,多数多模态模型就像 “传话筒”,图像、语音等信号需经过独立模型解码后再转译给语言模型,最终实现理解、生成。构建原生多模态大模型,可以让模型从训练阶段起,就具备理解图片、语音等各种模态信息的能力。
原生多模态模型就是能像人一样,“端到端” 理解各种模态的信息——前者训练时只需专注处理单一模态信息,难在保持 “传话” 过程中不出现信息失真的现象;后者则是在训练时就要让模型理解图片、视频、语音等信息,但难在让各种类型数据的意义互通。但原生多模态模型在训推中需要处理大量多模态的数据,给架构设计、训练过程和推理等多个层面都带来了指数级的压力。
Google 从开始训练 Gemini 系列,便确定原生多模态的技术路径。但训练数据较难统一,刚开始 Google 的模型在应用侧的效果并算不突出。直到 2025 年末,Gemini 3.0 展现的多模态理解能力,让业界重新相信了 “原生多模态”。
2025 年,国内企业发布的模型开始呈现原生多模态转向,发布的模型有各自的特点。阶跃星辰的 Step-3 针对国产芯片带宽进行了优化,降低了企业的商用成本;智谱的 GLM-4.6V 和字节的豆包大模型 1.8,都是将工具调用能力原生融入大模型,让 AI 可以行动;阿里发布的 Qwen 3-Omni 主要通过优化用户交互与开源,扩大生态。

百度文心大模型 5.0 则专注于模型本身,发布了参数量达 2.4 万亿的原生全模态大模型。在国内为数不多的全模态模型中,参数量最大,并在底层架构实现了文本、图像、音频、视频多模态的统一。
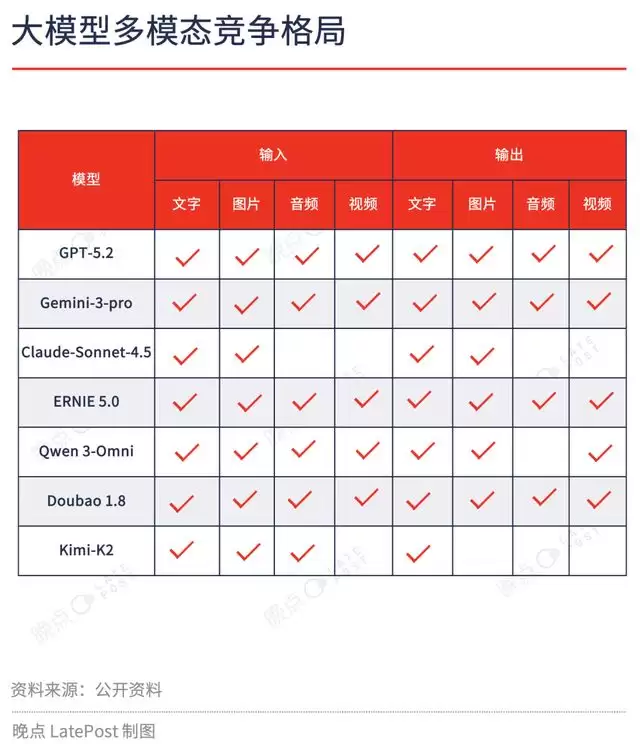
真实世界本质是跨模态的信号流,大模型要理解世界,原生多模态是技术上的趋势。以百度文心大模型 5.0 为例,其文本与视觉理解能力体现出的泛化性,均在 LMArena 大模型竞技场相应领域的全球排行榜中,占据前列。

通过原生多模态架构,模型能捕捉到更多非语言信息,AI 能够像人类一样感知现实,并通过 Agent 建立与世界更深层的连接。这也让大模型切入具身智能、智能座舱、消费硬件等万亿美金级赛道的商业场景成为可能。
推理成本定义 AI 商业化拐点
2024 年底,行业从 “快思考” 转向 “慢思考”。慢思考是让模型在回答问题之前,先模仿人类思考路径,在后台列出完整思维链条,自我修正后再生成回答。慢思考模式下用户每提一个问题,单次消耗的 token 数量都激增。
OpenRouter 发布的年度报告指出,2025 年推理任务消耗 token 的占比不断升高,模型专用于推理类任务的调用量,占 token 消耗总额的超 50% 。用户规模扩大后,模型厂商需为用户消耗的 token 支付高额的成本。
能否降低推理成本,成为 AI 走向商业化的关键。
2025 年初,DeepSeek 凭借 MLA 架构和精细化的 MoE 设计,显著降低大模型计算消耗的同时,提高了模型的性能,被行业视为 “效率标杆”。
但 DeepSeek 只是语言模型。语言模型的降本经验并不能直接平移到多模态领域。GPT-5、Gemini 3、豆包 1.8、文心 5.0 等原生多模态模型,需要处理视觉和音频流,其对训练算力的需求是纯文本模型的 5 到 10 倍,推理过程也更加复杂。GPT-4o 训练投入超 1000 PFlop/s-day,大约相当于数千台顶级 GPU 满负荷运行数周。

原生多模态模型若要实现 DeepSeek 式的降本,仅靠模型层面的算法创新是不够的。以文心 5.0 为例,依托飞桨深度学习框架进行大规模 MoE 模型训练,模型预训练性能较基线提速 230%,激活参数比低至 3%。
在国产芯片替代的大背景下,大模型降本需要同时掌握芯片、框架、模型和应用四个层面的自主权,对企业全栈系统工程能力提出了更高的要求。目前国内具备这种闭环能力的只有百度和华为。
当推理成本降低,模型可以在后台持续完成自我博弈、工具调用和逻辑反思,以 Manus 为代表的通用 Agent 就能实现在网页间穿梭,完成报表分析。这不光重塑了软件,也驱动模型能力从 “云端” 向 “端侧” 下沉。原本昂贵的 AI 被尝试融合进 AI 眼镜、智能座舱和手机 OS 中。
显然,AI 的下半场不再只是比拼模型规模,而是比 “谁能以更低的成本提供更深的智能”。在这场效率革命中,降本不是目的,而是手段。
谁是 AI 时代下一个 “超级入口”?
2000 年,百度也凭借自身技术,为搜狐、新浪、网易等门户 提供搜索方面的支持。彼时,这些门户 虽然拥有庞大的搜索流量,但 “搜索” 却仅被其视为一个附属的功能模块,没进行深度优化。2001 年,李彦宏力排众议要推出自己的门户 ,以搜索引擎为核心的入口 “百度”(Baidu.com)应运而生。
百度凭借超链分析技术和精准的中文分词,从门户 的索引中脱颖而出。那时,百度的成功在于解决了 “搜得准” 的问题。百度成为了最初的 “平台级入口”。
时间回到 2025 年,AI 技术让 “超级入口” 的逻辑发生了质变,下一代超级入口正从 “汇聚流量的 app” 转向 “多模态的智能助手”。
在 “超级入口” 之争上,国内能与大厂竞争的创业公司屈指可数。大厂不会放弃任何一种扩张的可能。字节跳动、阿里、腾讯与百度正依托各自的生态,抢占 “平台级入口” 这一高地。
12 月 1 日,字节发布和中兴努比亚合作开发的豆包手机助手,试图重塑人机交互的底层逻辑。用户仅通过语音交互,就可以让豆包手机助手直接接管用户屏幕。
同期,阿里调动整个集团资源,打造 AI 时代的超级助手。阿里成立千问 C 端事业群,将之前阿里云事业部下通义千问 APP 改名 “千问 APP” 发布,以 “一周一更新” 的速度迭代。近日,千问 APP 已接入高德地图,未来阿里或把夸克、UC、天猫精灵等功能也整合进千问 APP。
百度基于搜索,也上线了百度文心助手,对标 Gemini 3,竞争超级入口。百度搜索全面升级文心助手 AIGC 创作能力,支持 AI 图片、AI 视频、AI 音乐、AI 播客等多种模态创作。从硬件布局的演进趋势来看,百度可以依托文心 5.0 大模型的技术底座,通过萝卜快跑接管物理空间,用小度占据家庭交互入口,让信息实现从虚拟空间向真实空间的渗透。
几周前,Google 将 Gemini 3 嵌入核心搜索业务,通过跨应用的数据调取,实时生成能与用户交互的 UI 页面,向用户直接交付搜索结果。Google 通过自研 AI 芯片和 Google Cloud 支持大模型训练、推理,训练出的先进的模型又能与自身搜索、云盘、Android 生态等入口融合,继续产生相应领域的高质量数据,持续推动智能升级。
有行业人士认为,Google 已形成 “算力-模型-数据-应用” 的系统级飞轮,而百度是中国为数不多能与 Google 对标的 “AI 六边形战士”。因为下个时代的 AI 竞争的不止是模型能力,而是演进为全栈式的系统竞争,比拼的是谁能完成 “算力—系统—模型—入口—资源—行动能力” 六个层面的闭环。
他们认为,百度依托昆仑芯、智能云作为算力与系统底座,以文心大模型作为能力中枢,链接搜索、网盘、小度等流量入口,并通过搜索、地图与自动驾驶等业务将能力落地到现实世界,形成了六大要素闭环,是国内最接近 “AI 六边形战士” 形态的公司之一,具备长期演进的系统飞轮能力。
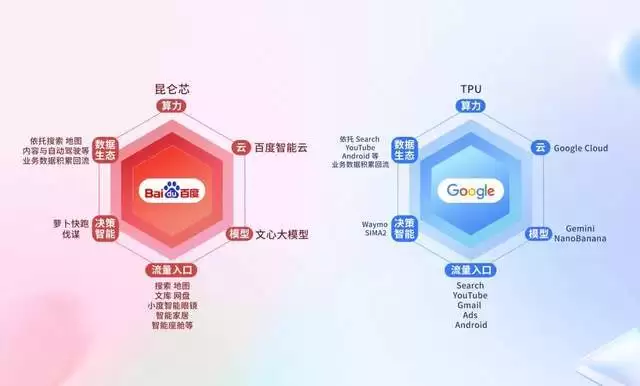
图源网络
水面之下,腾讯同样暗流涌动。12 月下旬,腾讯新成立 AI Infra 部、AI Data 部、数据计算平台部,27 岁的前 OpenAI 研究员姚顺雨出任 “CEO / 总裁办公室” 首席 AI 科学家。过去数月里,腾讯也以加倍薪资挖角 AI 人才,强化研发体系。
在生成式人工智能的第一波流量交锋中,有的公司水涨船高,有的公司陷入沉静。但在喧嚣之下,坚守 “技术信仰” 的企业,正在等待那个规则被重新定义的时刻。
题图来源:Transformers: Dark of the Moon




