12月20日,摩尔线程在年度开发者大会上正式推出“花港”架构,并同步发布了MUSA 5.0全栈软件升级。大会现场同时亮相了“华山”与“庐山”两款核心芯片,前者专注于AI推理训练一体化,后者则主打高性能图形渲染场景。

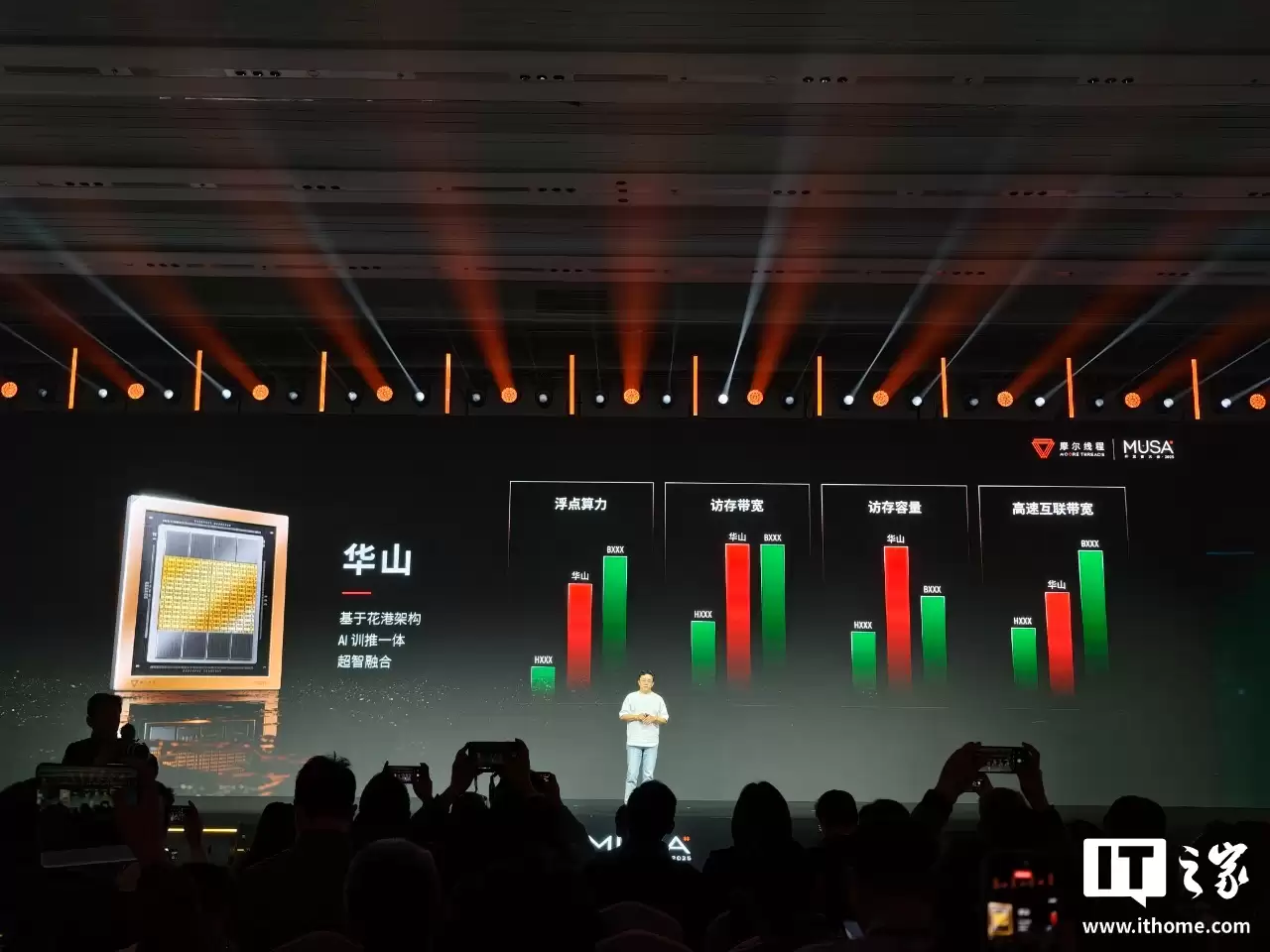
作为花港架构的首款芯片,“华山”致力于实现AI训练与推理的超智融合。其在浮点算力、访存带宽、访存容量及高速互联带宽等多个维度均有显著提升。芯片内置新一代异步编程技术与异步编程模型,具备高效线程同步、线程束特化等先进特性。

具体而言,“华山”芯片搭载了新一代张量计算引擎,拥有TF32/FP16/INT8等全精度MMA(矩阵乘加)能力,可大幅提升FP6/FP4等低精度数据格式的张量运算性能。新增的TCE-PAIR模式增强了内部数据重用效率,同时还配备了MTFP8/6/4混合低精度计算技术,兼容MXFP与NVFP等业界主流格式。


据发布会现场介绍,“华山”芯片还可应用于超十万卡规模的AI智算工厂。它能够搭载新一代Scale-up系统,兼容MTLink 4.0及多种以太协议,适配多种Scale-up交换设备,支持SHARP技术,片间互联速率高达1314 GB/s。

而“庐山”则是花港架构的第二款芯片,专攻高性能图形渲染场景。得益于架构的新一代指令集,其算力密度提升50%,能效比提升高达10倍。芯片内置第一代AI生成式渲染架构(AGR)与第二代光线追踪硬件加速引擎,并完整支持DirectX 12 Ultimate。

值得注意的是,“庐山”芯片还集成了AI计算加速引擎,可与几何/网格着色器、像素着色器、光线追踪材质着色器等核心单元进行高效互联。其配备的UNITE渲染架构,能够优化任务分配、负载平衡与同步流程。

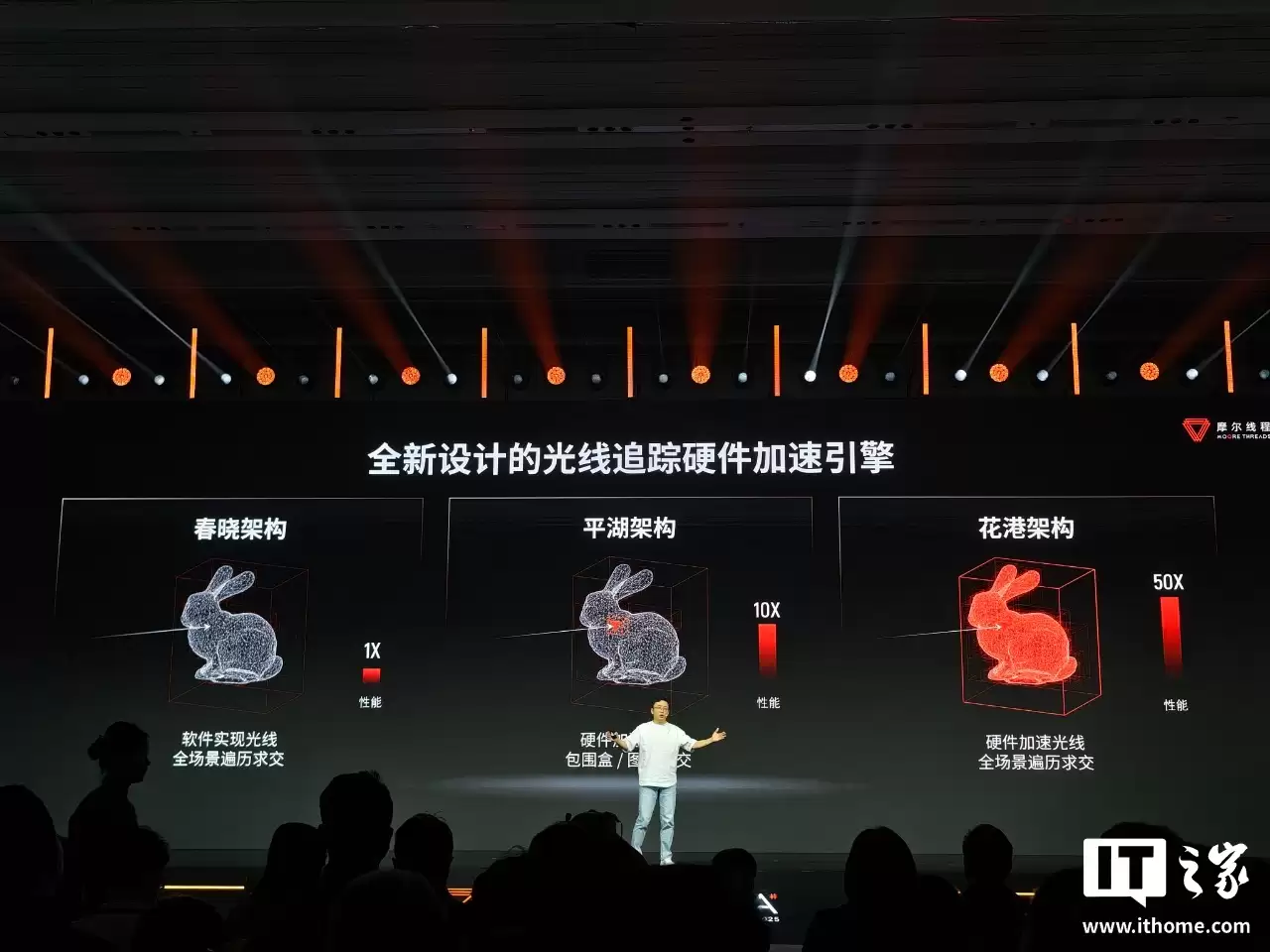
此外,花港架构还配备了全新设计的光线追踪硬件加速引擎,支持硬件加速光线全场景物求交。与最早的春晓架构相比,其光线追踪性能提升了50倍。

搭载“华山”和“庐山”芯片的全新硬件产品预计将于明年正式亮相。我们将持续关注,并在第一时间为您带来最新进展。




