12月5日消息,火山引擎今日发布了豆包语音识别模型2.0(Doubao-Seed-ASR-2.0),该模型基于Seed混合专家大语言模型架构构建。
据悉,2.0版本模型在推理能力方面显著提升,通过深度理解上下文情境实现精准识别,上下文整体关键词召回率提升了20%。
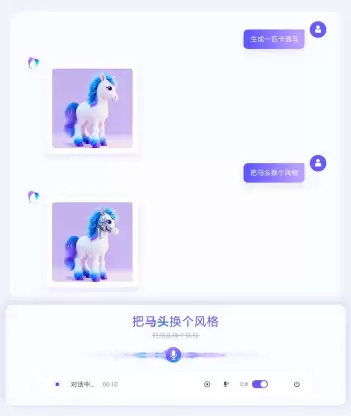
同时该模型支持多模态视觉识别,不仅能够"听懂文字",还能"看懂图片",借助单图和多图等视觉信息输入,使文字识别更精准。
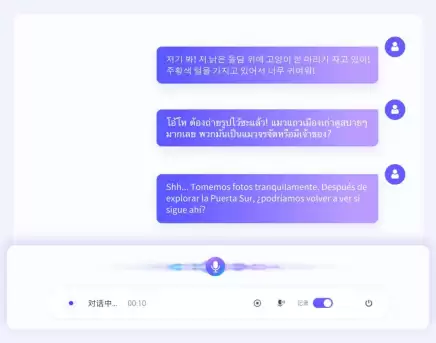
此外,2.0版本还支持日语、韩语、德语、法语等13种外语的精准识别。
新版本重点针对专有名词、人名、地名、品牌名称及易混淆多音字等复杂场景进行了升级优化。
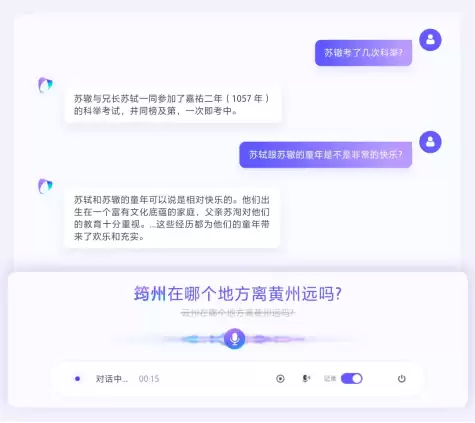
以历史人物生平讨论场景为例,当用户提到苏轼谦称"筠(yún)州"时,若模型缺乏推理能力容易将其误识为同音的"云州""郓州"等。
而豆包语音识别模型2.0可依托"当前讨论苏轼、苏辙"这一背景,即使上下文中从未出现过"筠州",也能通过逻辑推理锁定用户所指的特定地名,最终实现对多音字地名的精准识别。
目前,豆包语音识别模型2.0已上线火山方舟体验中心,并对外提供API服务。





