11月26日,业界领先的空间推理基准测试榜单SpatialBench发布了最新一期成绩,阿里千问的视觉理解模型Qwen3-VL与Qwen2.5-VL包揽冠亚军,综合表现超越了Gemini 3、GPT-5.1、Claude Sonnet 4.5等国际顶尖模型。
SpatialBench榜单数据显示,Qwen3-VL-235B与Qwen2.5-VL-72B分别取得13.5和12.9的高分,显著领先于Gemini 3.0 Pro Preview(9.6分)、GPT-5.1(7.5分)及Claude Sonnet 4.5等海外旗舰模型。
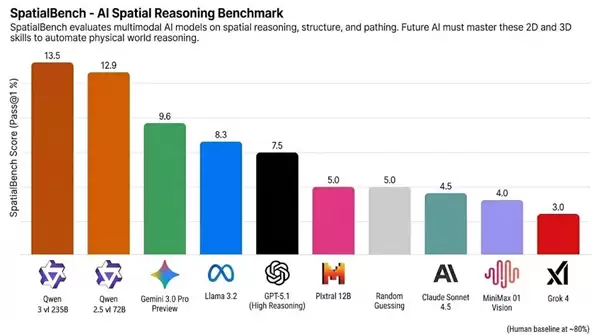
不过需要指出的是,当前AI大模型的整体表现与人类水平仍存在差距,人类基准线约为80分左右。在电路分析、CAD工程设计和分子生物学等复杂空间推理任务中,专业人士依然保持着明显优势,现有大模型还无法完全自动化完成此类工作。
据了解,Qwen2.5-VL于2024年开源,而Qwen3-VL则是阿里在2025年推出的新一代视觉理解模型。
Qwen3-VL在视觉感知与多模态推理方面取得重要突破,在32项核心能力测评中超越了Gemini 2.5 Pro和GPT-5。它不仅能够调用截图、搜索等工具完成"带图推理"任务,还能凭借一张设计草图或一段游戏视频直接进行"视觉编程"。

同时,Qwen3-VL专门增强了3D检测能力,能够更精准地感知空间环境。基于该模型,机器人可以更好地判断物体方位、视角变化和遮挡关系,实现如同远处采摘苹果般精准的动作控制。
目前Qwen3-VL已开源多个版本,包括2B、4B、8B、32B等密集模型,以及30B-A3B、235B-A22B等MoE架构模型。每个模型都提供指令版和推理版两种选择,成为目前最受企业和开发者欢迎的开源视觉理解模型。此外,Qwen3-VL模型也已上线千问APP,用户可免费体验其强大功能。
据悉,SpatialBench是近年来兴起的第三方空间推理基准测试榜单,主要关注多模态模型在空间、结构、路径等方面的综合推理能力,被AI社区视为衡量"具身智能"发展水平的新兴测试标准之一。
SpatialBench不仅测试模型已有知识,更着重评估模型在二维和三维空间中感知和操控抽象概念的能力,这对具身智能的实际落地应用尤为关键。




