11月21日,腾讯混元大模型团队正式宣布开源最新视频生成模型HunyuanVideo 1.5。这款轻量化视频生成模型基于Diffusion Transformer(DiT)架构,拥有83亿参数,支持生成5至10秒的高清动态视频。
目前该模型已率先在“元宝”平台上线,普通用户无需复杂配置即可直接体验。用户可通过两种方式生成视频:一是直接输入文字描述,系统即可根据文本内容智能生成相应视频;二是上传静态图片并搭配文字指令,轻松将图片转化为富有动感的视频片段。

据介绍,HunyuanVideo 1.5具备全面的视频生成能力,不仅支持中英文文本输入生成视频,还能以图片为素材进行视频创作。
在图文生成视频功能中,该模型表现出卓越的图像与视频一致性。生成视频的色调、光影、场景氛围、主体形象及细节处理等方面,都能与原始图片保持高度契合。
该模型还具备出色的指令理解与执行能力,能够精准呈现多样化的场景需求,包括运镜效果、流畅运动轨迹、真实物理规律模拟,以及写实人物描绘和人物情绪表情等复杂指令。
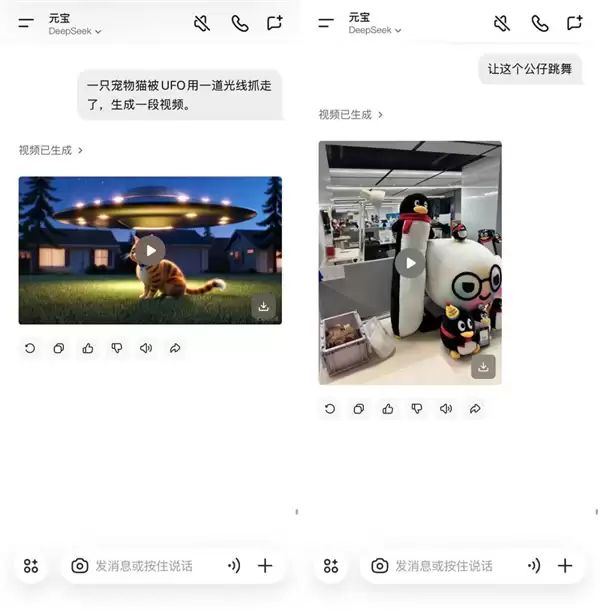 在元宝中可以通过文字和图片生成视频
在元宝中可以通过文字和图片生成视频
同时,HunyuanVideo 1.5支持写实、动画、积木等多种艺术风格,并可在视频中智能生成中英文字幕,充分满足各类内容创作的多样化需求。
在画质方面,该模型原生支持生成480p和720p高清视频,还可通过超分模型提升至1080p电影级画质。
此前,视频生成领域的开源SOTA旗舰模型参数规模普遍在200亿以上,部署时需要使用超过50GB显存的高端显卡。

HunyuanVideo 1.5定位为“开源小钢炮”,显著降低了使用门槛,可在14G显存的消费级显卡上流畅运行,真正让每一位开发者和内容创作者都能轻松上手使用。
通过多层次技术创新,HunyuanVideo 1.5在生成效果、运算性能与模型尺寸之间实现了最佳平衡。
该模型创新的SSTA注意力机制(全称Selective and Sliding Tile Attention,选择性滑动分块注意力)在保障高质量视频生成的同时,显著提升了推理效率。配合多阶段渐进式训练策略,在运动连贯性、语义遵循等关键维度均达到了商用水平。




