11月19日消息,互联网基础设施服务提供商Cloudflare于昨晚突发全球性故障,导致包括社交平台X(原推特)和OpenAI的ChatGPT在内的多个主流网站出现服务异常。有不少网友调侃道:上次亚马逊故障让半个互联网瘫痪,这次Cloudflare直接让剩下的一半也歇菜了。
针对此次事件,Cloudflare随后发布了官方博客,详细解释了昨晚全球故障的具体原因。

世界标准时间2025年11月18日11:20(北京时间19:20),Cloudflare的网络开始出现核心网络流量传输异常的重大故障。表现为互联网用户在尝试访问客户网站时看到错误页面,这反映了Cloudflare网络内部确实出现了系统性问题。
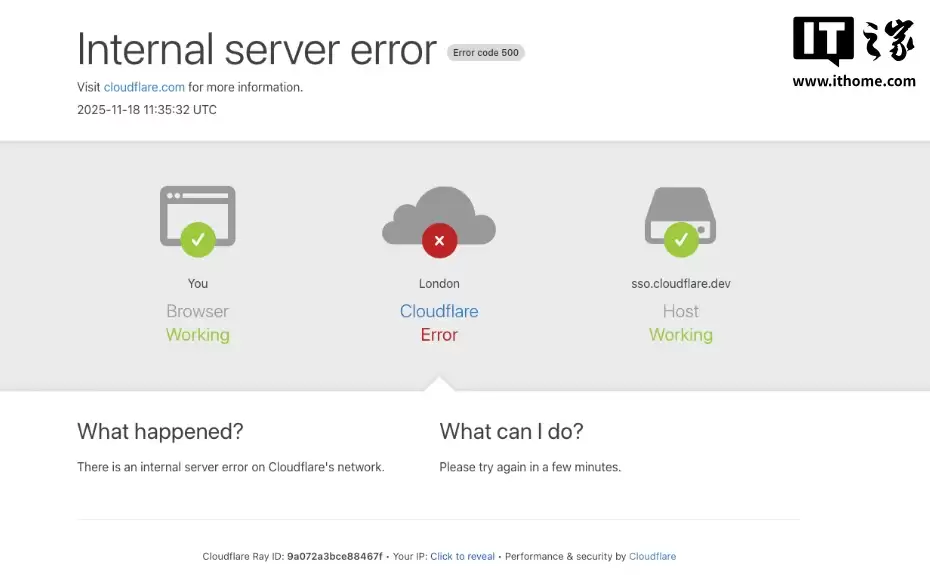
Cloudflare在最新声明中明确表示,此次故障并非由任何形式的网络攻击或恶意活动直接或间接引起。实际上,问题源自Cloudflare数据库系统权限的变更,该变更导致数据库向Cloudflare机器人管理系统使用的“功能文件”中输出多个异常条目,致使该文件体积意外翻倍。这个超出预期的大型文件随后被传播到构成网络的所有机器上。
运行在这些机器上的软件负责跨网络路由流量,它会读取这个功能文件以便Bot Management系统能够及时应对不断变化的威胁。但该软件对功能文件的大小有限制,当文件超过其两倍大小时,就导致了软件失效。
Cloudflare透露,最初他们错误地怀疑故障是由超大规模DDoS攻击引起的,随后才准确识别出核心问题,并用该文件的早期版本进行了替换。到北京时间22:30,核心流量已基本恢复正常。在接下来的几个小时内,团队持续努力减轻网络各部分的负载,随着流量逐步重新上线。截至北京时间11月19日01:06,Cloudflare的所有系统均已恢复正常运行。
下图展示了Cloudflare网络提供的5xx错误HTTP状态代码的数量。正常情况下,这个数值应该非常低,而且在故障开始之前也确实如此。
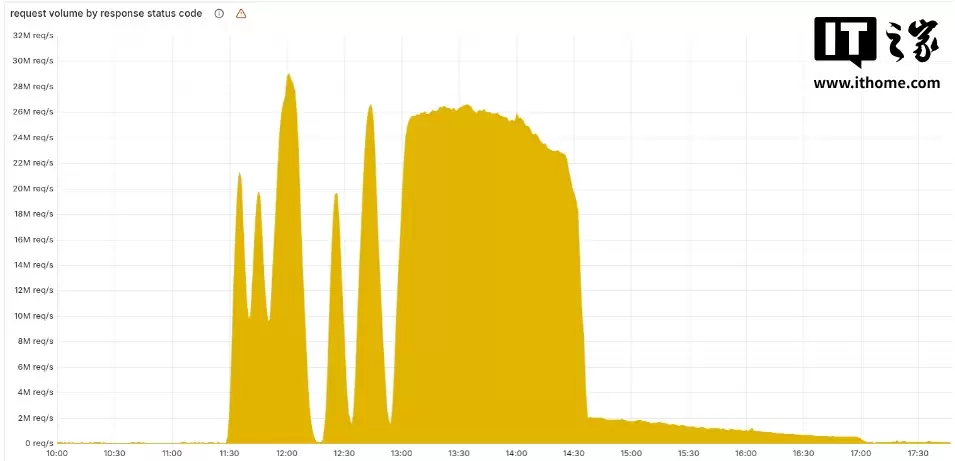
图中11:20(北京时间19:20)之前的量是网络观测到5xx错误的预期基准。峰值及随后的波动表明系统由于加载了错误的功能文件而失效。值得关注的是,系统在一段时间后会自动恢复,然后又再次挂掉。这种反复无常的表现对于内部错误来说是非常不寻常的行为。
官方解释道,该文件每五分钟由一个在ClickHouse数据库集群上运行的查询生成,该集群当时正在逐步更新以改进权限管理。只有当查询运行在已更新集群部分时才会生成错误数据。因此,每五分钟都有可能生成一组配置良好或存在错误的功能文件,并在网络中快速传播。
错误一直持续到14:30(北京时间22:30),直到团队识别并解决了根本问题——通过停止不良功能文件的生成和传播,并将一个已知良好的文件手动插入到功能文件分发队列中。随后强制重启了核心代理,最终解决了这个问题。
受影响的服务如下:




