今天要聊一个Kubernetes部署过程中看似基础却极易踩坑的问题:网段规划。
这个看似简单的配置项,往往会让很多刚上手的朋友栽跟头。

1. 故障现象
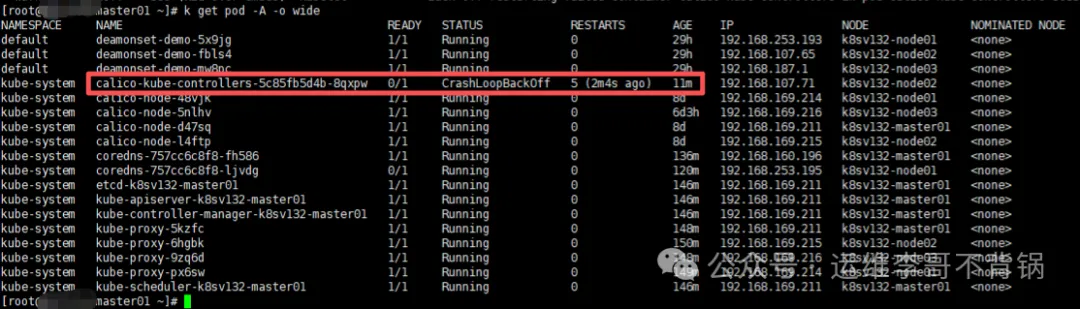
昨天在帮社区运维同行答疑时,有位工程师说他刚部署的Kubernetes集群中,Calico组件一直处于CrashLoopBackOff状态,不断重启。
2. 解决问题
我首先让他用describe命令查看Pod的详细状态。

从截图来看,就绪检测失败了,无法连接到API Server。
为了尽快定位问题,我通过远程工具连接他的电脑进行操作。
我先查看了失败Pod的日志。执行下面命令:
kubectl logs -n kube-system calico-kube-controllers-775fd85945-bx8fk
查看到日志里的关键报错。
Get "https://10.224.0.1:443/apis/crd.projectcalico.org/v1/clusterinformations/default": dial tcp 10.224.0.1:443: i/o timeout
也就是说Calico控制器(calico-kube-controllers)在启动时无法访问Kubernetes API Server(10.224.0.1:443)。
Calico连接不上API Server。这基本上等同于网络"断了主干线"。
这时我已经初步判断可能是网络原因,检查了防火墙,结果都是关闭的,那很可能是Kubernetes网络问题。
在群友提供的截图中还有一个pod没有完全起来,那就是CoreDNS处于Running但未就绪(Ready=False)状态。
于是我顺手看了下CoreDNS的信息:
kubectl describe po coredns-757cc6c8f8-4t6qt -n kube-system
果然,熟悉的错误出现了:
Readiness probe failed: HTTP probe failed with statuscode: 503
这时候可以断定,问题不在镜像,也不在探针。整个Pod网络已经失联。出现503状态
接着我检查了主机IP,找到了最根本的原因:Pod网络和宿主机网络冲突了
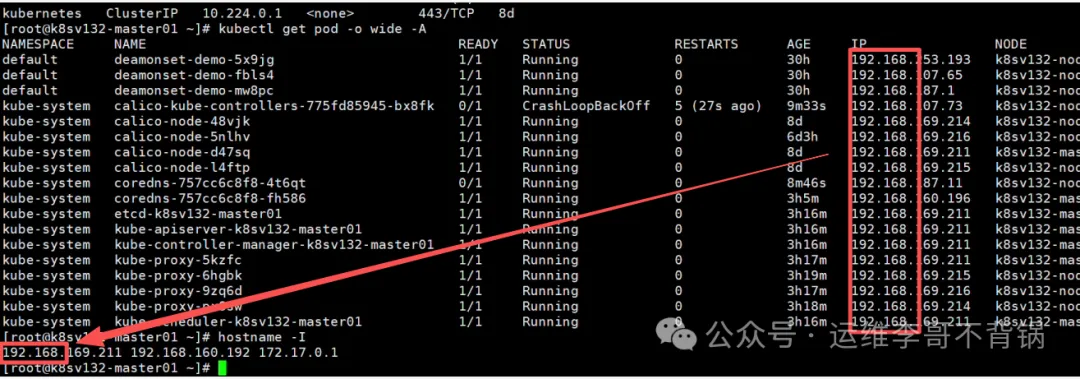
群友初始化时将Pod网段设置为192.168.0.0/16,而他的宿主机网卡就在192.168.169.0/24,宿主机网段在Pod网段里。
这俩网段就重叠了!
3. 根本原因
最根本原因是网段冲突了,Pod流量被错误地送进了"虚拟网卡"
因为这次网段冲突,Pod想访问API Server时,路由表判断:"192.168?那是我Calico管的",于是流量被错误地送进虚拟网卡caliXXX,然后直接丢包。
最后让群友修改网段重新初始化后,Kubernetes集群所有的Pod都已正常运行。

4. 后续正确做法
为了避免这种坑,记住一个原则:Pod网段、Service网段、宿主机网段,绝对不能重叠。
Kubernetes的网络设计,本质上有三层独立的网段:每一层都要相互隔离、不重叠、不冲突。
5. 其他启示
本次排查过程,还可以得出下面三个启示:
Calico不停重启≠镜像问题,很多时候是底层网络冲突。先看CoreDNS、再查Calico路由表,能快速定位问题。网段规划要在集群初始化前定好,别用宿主机的同一段。



