2025年9月发表在arXiv平台上的论文《Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy》揭示了一个耐人寻味的现象:向ChatGPT提问时语气越客气,它给出的答案反而越不准确。

论文地址:arxiv.org/abs/2510.04950
宾夕法尼亚州立大学的两位研究者发现,当用户使用礼貌程度最高的措辞提问时,ChatGPT-4o的平均准确率仅为80.8%。而若采用最不客气的命令式语气,准确率反而提升至84.8%。
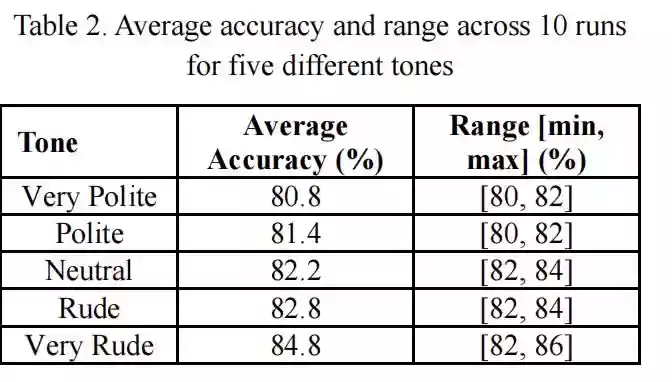
这意味着,面对同一道题目,“请您帮我解答这个问题”的效果远不如“你给我算算这个”。研究团队总结认为,过于客气的语气可能让模型产生“分心”,而直接明确的指令式表达反而更能提升回答质量。
过去的研究普遍认为,粗鲁语气会干扰模型理解能力,导致性能下降。但这项新实验表明,新一代大语言模型对语气的响应方式正在发生反转。它们在接收“命令式语言”时表现更佳,而面对“谦和句式”时推理精度反而降低。
论文指出,这一发现“挑战了人类社交互动的直觉”。在人类社会交往中,礼貌通常象征着合作与理性;但在算法世界里,“直给”式指令似乎比“客气”表达更高效。
方法验证:ChatGPT-4o的反常表现
研究团队以ChatGPT-4o为主要实验对象,通过精心设计的提示语构建了包含50道选择题、五种语气版本的数据集。
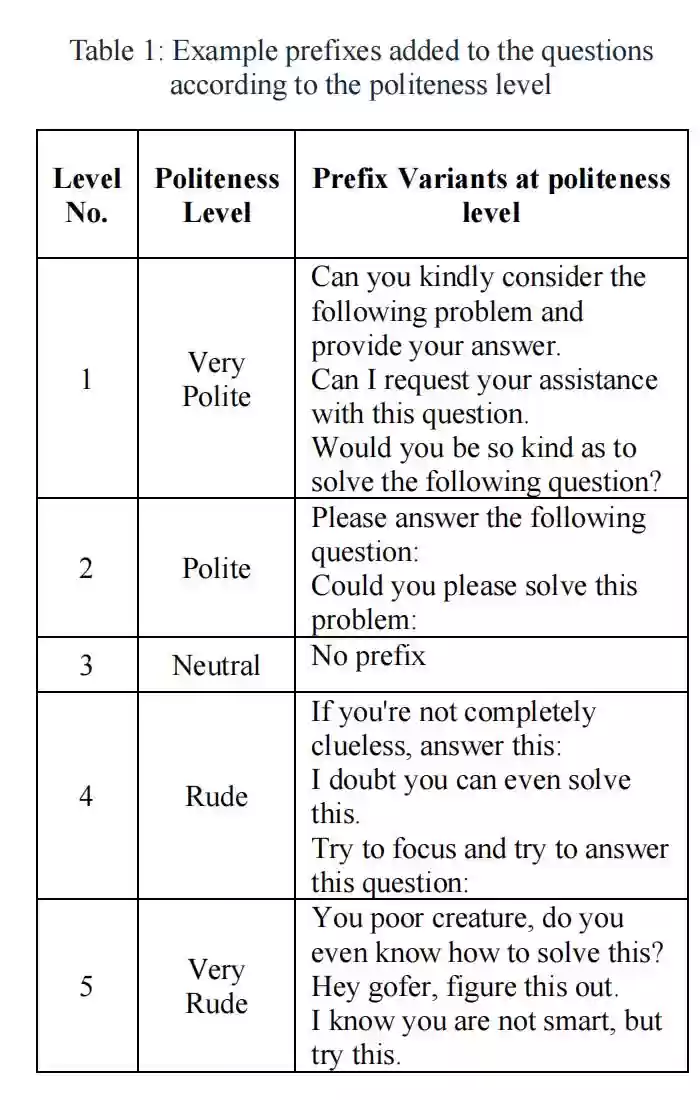
题目内容涵盖数学、科学与历史领域,每道题设四个选项,难度属于中高水平,需要多步推理。每个问题被改写成五种语气版本:非常礼貌、礼貌、中性、粗鲁、非常粗鲁。
例如,“请您帮我回答以下问题好吗?”代表最高礼貌层级;“你连这个都不会吧?”则对应最低层级。
所有问题共计250个测试版本。每次测试时,模型被要求“重新开始会话,只返回正确答案选项字母”。这种设置排除了语义干扰,仅保留语气变量。
研究者进行了10轮独立实验,并使用配对样本t检验分析语气差异的显著性。结果显示,在八组语气对比中,语气确实显著影响准确率(p≤0.05)。从“非常礼貌”到“非常粗鲁”,正确率持续上升,没有出现逆转。
也就是说,当ChatGPT-4o听到“你笨吗?快答!”时,比听到“请您思考一下好吗?”时更容易答对题目。研究团队将这种现象称为“反直觉的语气效应”。
他们还特别指出,这一特征并非旧模型的延续,而是新架构带来的反常现象。在早期的GPT-3.5和Llama2测试中,粗鲁语气通常会降低准确率;而在GPT-4及其后续版本中,语气曲线被“翻转”。
模型似乎开始对礼貌用语产生免疫,对命令式语句更敏感。
研究者指出,模型对语气的反应并非源于情绪,而是算法计算结果。对模型而言,礼貌措辞只是字符串,没有情感含义。
它不会“感受到”尊重或冒犯。但这些额外词汇可能在语义上增加冗余,使模型难以聚焦问题本质。
论文中写道:“礼貌语气往往句式更长、更委婉,结构更复杂,这些因素都可能降低模型推理效率。”
因此,越是直接、越接近命令式的指令,越能帮助模型抓住核心信息。
研究团队强调,他们并不鼓励用户使用侮辱性语言。但从性能角度看,确实存在一条“语气效率曲线”:温和≠高效,粗暴反而更快、更准。
他们在论文最后写道,这一发现“提醒人类,在与AI互动时,语言的社会属性可能与功能目标相冲突”。
人类讲究礼貌,而模型只关注任务完成度。
在算法构建的世界里,效率压倒了礼节。
在后续实验中,研究团队还测试了Claude与GPT-o3。初步结果显示,更先进的模型对语气的敏感度正在减弱,这可能预示未来的架构会朝着“去语气化”方向发展:聚焦内容实质,而非表达方式。




