人类处理日常事务时,往往先静心思索再采取行动。撰写邮件时需要构思整体架构,制定餐饮计划时要考虑营养均衡,这些日常决策背后都蕴含着复杂的思考过程。心理学家丹尼尔·卡尼曼将这种深度思考能力称为"系统2思维",它体现了人类智能的本质特征。
现有人工智能系统在可验证领域如数学运算、编程解题等方面取得进展,借助规则化奖励机制提升了推理能力(RLVR强化学习)。但在面对开放性问题时,系统的泛化能力仍有局限。普林斯顿大学陈丹琦团队的最新研究实现了突破,成功将可验证领域的推理能力迁移至通用对话场景。

研究团队创新性地提出"基于模型奖励思维的强化学习"(RLMT)框架。该框架要求语言模型在生成最终回答前,必须先输出详细的思考过程,然后通过偏好奖励模型对整套"推理+回答"进行优化。实验数据显示,经过RLMT训练的8B参数量模型在对话和创意写作等任务上超越了GPT-4o,与Claude-3.7-Sonnet水平相当。更令人惊讶的是,仅用7000个提示训练的Llama-3.1-8B基础模型,就超越了经过2500多万样本复杂训练的指令优化版本。

RLMT框架:融合两大训练范式
现有语言模型训练面临两个主要挑战:基于人类反馈的强化学习(RLHF)虽能对答案进行整体评分,但缺乏对思考过程的引导;可验证奖励强化学习(RLVR)在特定领域效果显著,却难以推广到开放式问题。RLMT框架创新性地结合了两者的优势。

该框架有三个关键设计:训练算法采用GRPO效果最佳,但DPO/PPO也有所提升;选用Skywork-v1-Llama-3.1-8B-v0.2作为奖励模型;从WildChat平台筛选7.5k条真实对话构建提示库。值得注意的是,RLMT支持两种训练模式:监督微调热启动和零训练直接应用,后者仅需添加指令前缀即可引导模型思考。

实验结果:小模型的逆袭
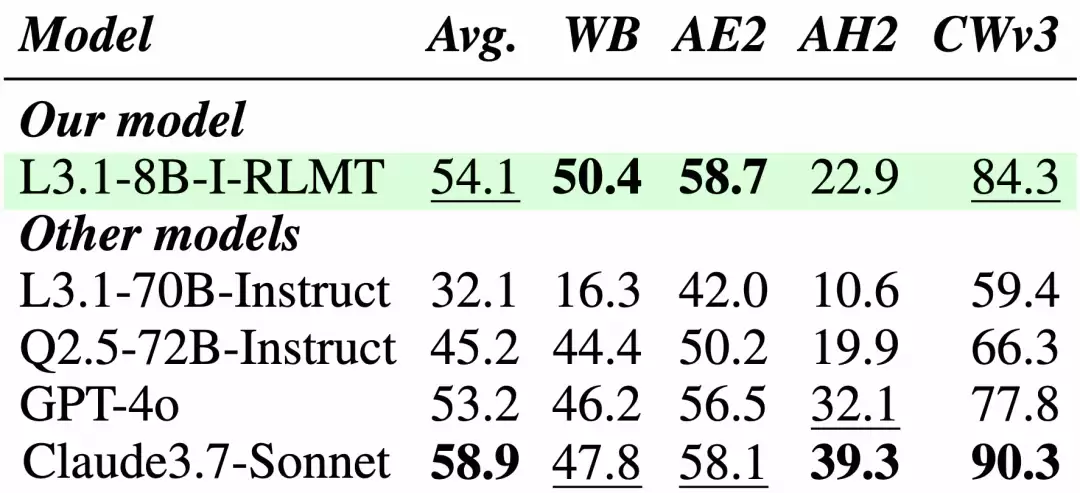
在Llama-3.1-8B和Qwen-2.5-7B两个模型系列上的40次训练表明,RLMT模型在所有测试任务中表现突出。特别在聊天基准测试中,平均领先基准模型3-8分。更令人瞩目的是,8B参数的模型在WildBench测试中获得50.4分,超越70B级别的大模型和GPT-4o。
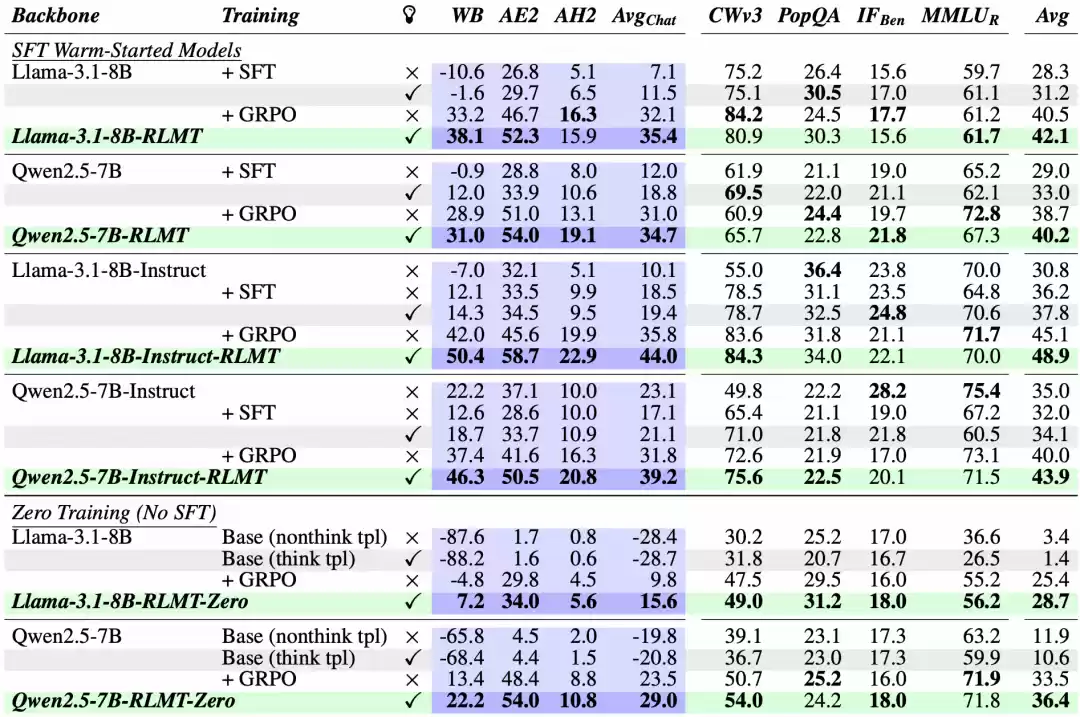
零训练模式同样取得显著效果:Llama-3.1-8B-RLMT-Zero模型在聊天任务上获得15.6分,比经过复杂训练的指令版本高出5.5分。消融实验证实,提示质量、奖励模型强度和思考过程三者缺一不可,即便奖励模型较弱,RLMT仍能保持优势。
思考模式的进化
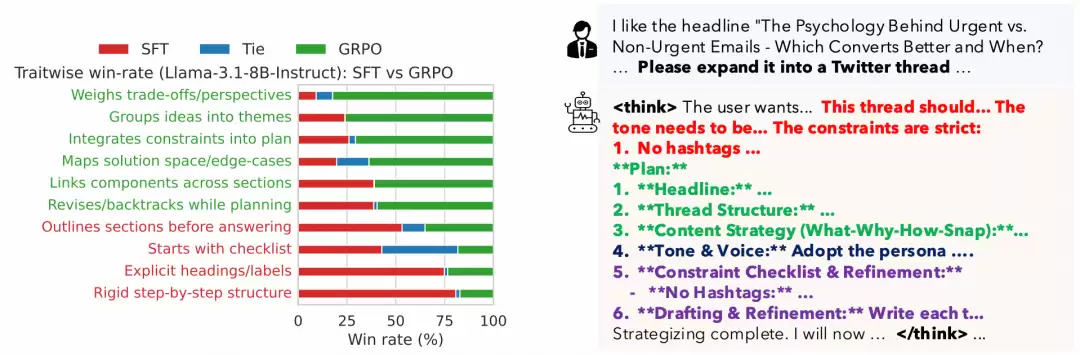
RLMT不仅提升性能,更改变了模型的思考方式。对比显示,传统模型输出像程序执行般线性推进,而RLMT模型展现出更接近人类的思维特征:先梳理约束条件,分组整合想法,最后优化细节。训练过程中,模型的思考长度持续增加,从200token扩展到600以上。
这项研究打破了"数据规模决定性能"的固有认知,证明激发模型思考能力同样关键。虽然还存在优化空间,但RLMT框架为语言模型的理解力培养开辟了新路径。当AI不仅能回答问题,还会像人类一样思考时,我们离真正的通用人工智能又迈进了一步。




