阿里云于今日(9月23日)正式推出开源项目Qwen3-Omni、Qwen3-TTS,以及对标谷歌Nano Banana的全新图像编辑工具Qwen-Image-Edit-2509。
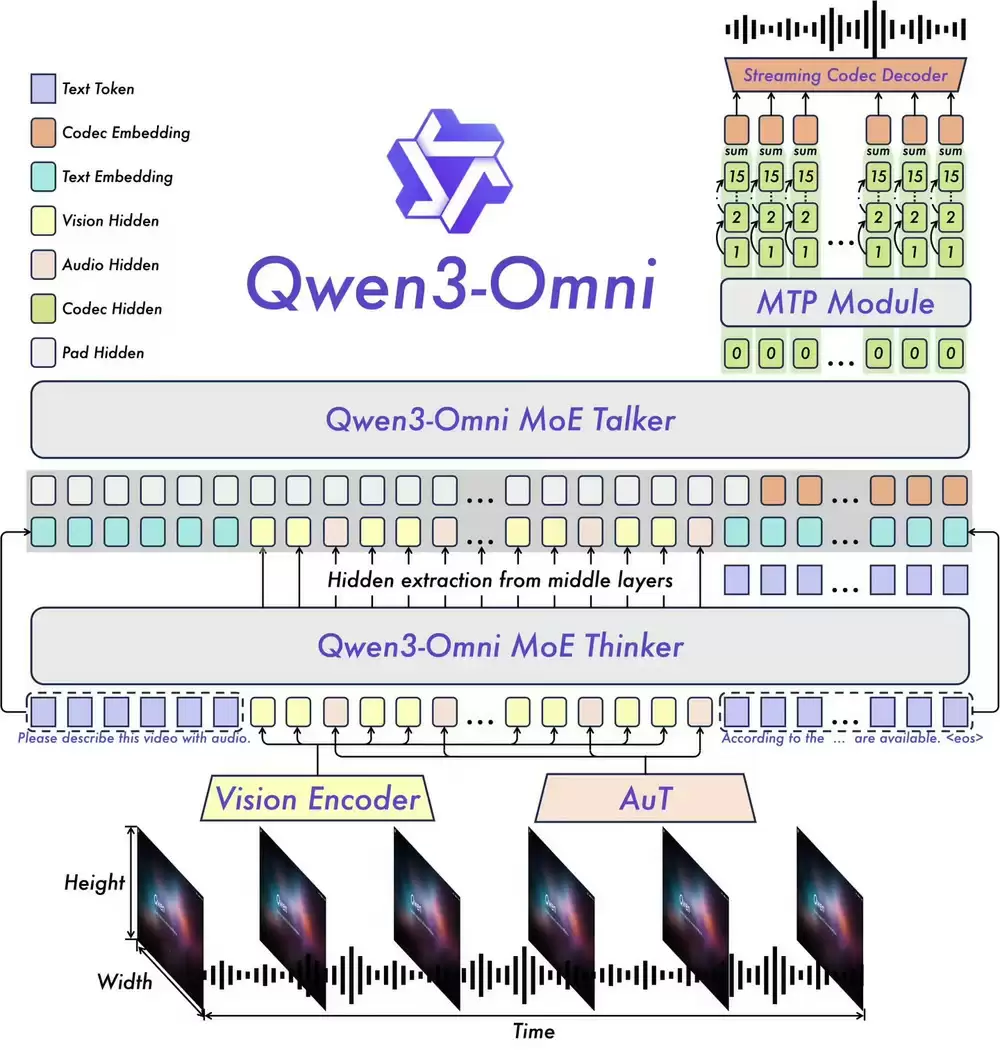
Qwen3-Omni作为全球首个原生端到端全模态AI模型,突破性地实现了文本、图像、音频和视频等多模态数据的同步处理能力。其创新的流式输出技术不仅支持实时文本交互,更能以自然语音方式呈现结果,有效解决了传统多模态建模必须权衡不同功能的行业难题。
这款多语言全模态基础模型具有以下显著优势:
行业领先的跨模态性能:基于文本预训练与混合多模态训练相结合的独特架构,在保持单模态文字和图像处理能力的前提下,音频及视频处理水平达到行业新高度。
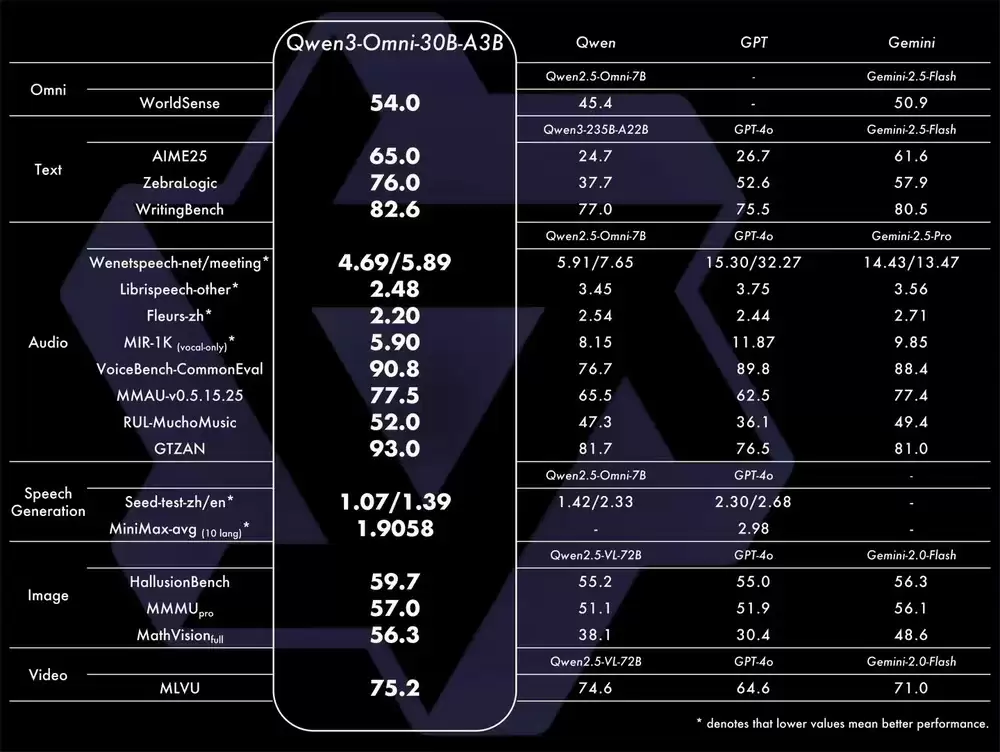
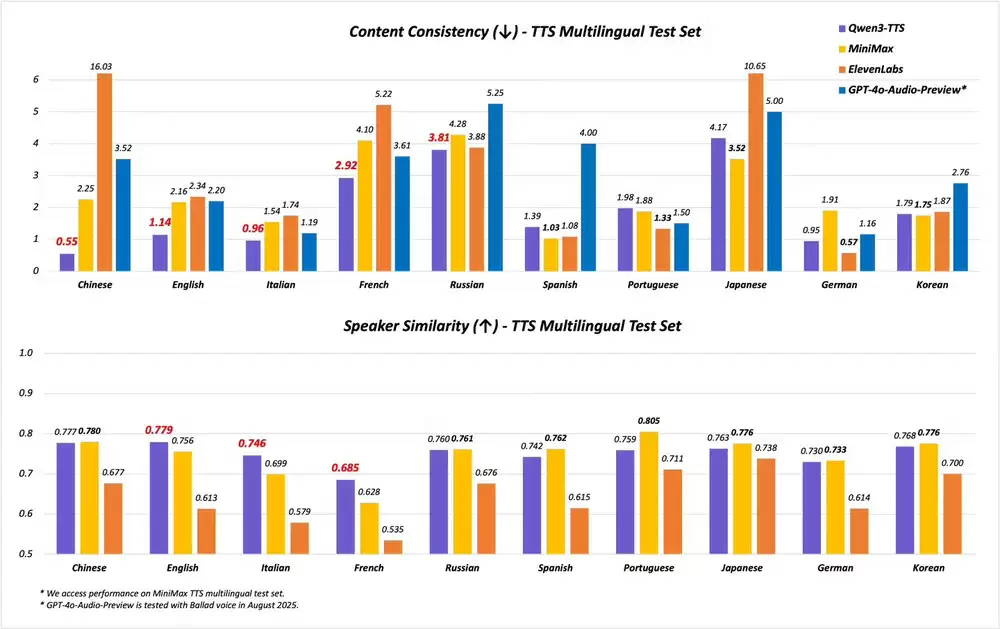
在36项核心测评指标中,22项位居世界领先地位,其中的32项在开源领域保持第一。特别是在语音识别(ASR)、音频理解和语音对话等关键场景,其综合表现与Gemini 2.5 Pro旗鼓相当。
多语言支持能力:可处理119种文本语言、19种语音输入语言及10种可输出语音语言。语音输入覆盖全球主要语种,输出则包括英、中、法、德等10种常用语言。
技术创新亮点:采用MoE架构的"思考者-表达者"设计,结合AuT预训练技术实现卓越的泛化能力,并通过多码本设计实现超低延迟。
同步推出的Qwen3-TTS语音合成系统突破性地提供17种人声音色选择,每种音色均支持10种语言输出。除国际通用语种外,还特别加入了闽南语、粤语等8种中国地方方言。
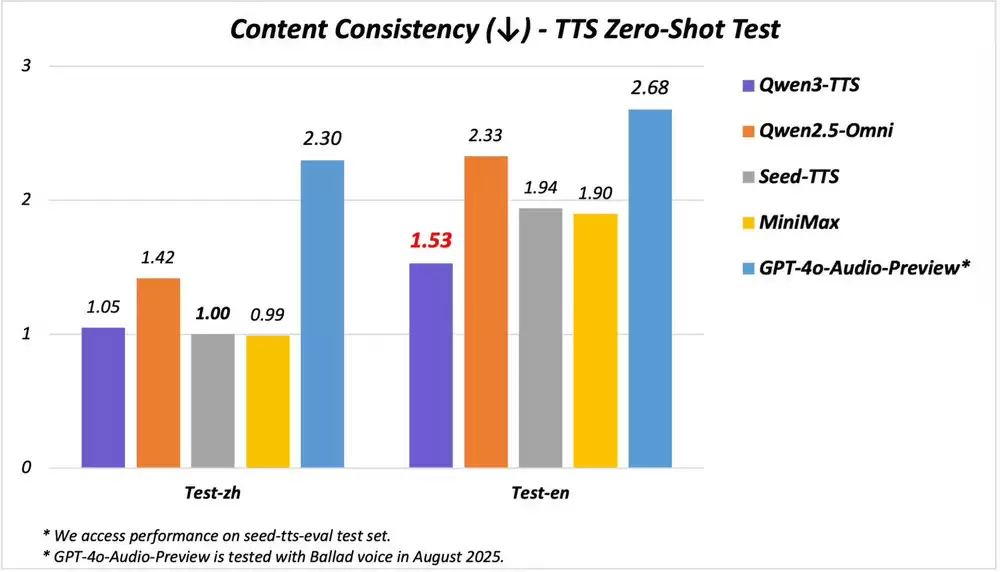
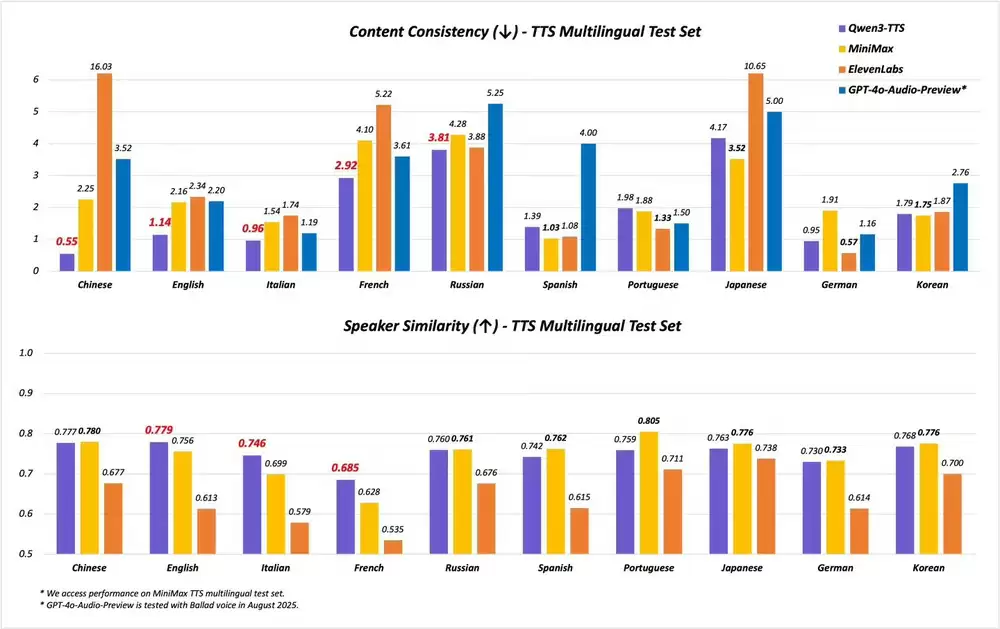
在专业评测中,Qwen3-TTS-Flash的表现全面超越SeedTTS、MiniMax等竞品,在语音稳定性和音色逼真度等关键指标上达到行业最高水准。
Qwen-Image-Edit-2509作为月度迭代产品,其核心升级在于显著提升了图像编辑一致性,这一改进方向与字节最新的即梦4.0模型不谋而合。
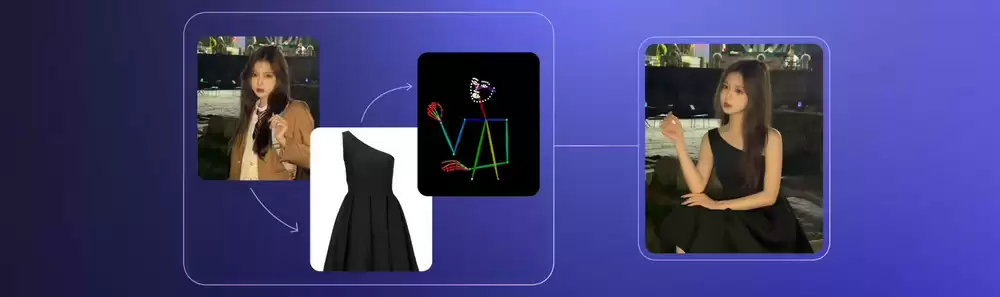
与8月版本相比,新版主要具备三大特性:
1. 突破性支持多图合成编辑,可完美处理1-3张图像的组合场景,包括人物合影、商品展示等典型应用。
2. 单图编辑一致性获得全面提升,特别在人物肖像、商品展示和文字修改等高频使用场景表现突出。
3. 原生整合ControlNet插件,支持深度图、边缘图等多种高级图像控制方式。
此外,阿里云同期还开源了Qwen3-Next-80B-A3B-Instruct-FP8和Qwen3-Next-80B-A3B-Thinking-FP8两个专业模型。





