百度近期在其海外官方账号发布了全新轻量级文字识别模型PP-OCRv5的相关信息。这款仅含0.07B参数的模型展现出惊人实力,仅用千分之一的参数量就能达到媲美700亿参数大模型的OCR识别精度。在实际测试中,PP-OCRv5的表现力压GPT-4o、Qwen2.5-VL-72B等主流视觉大模型。值得一提的是,飞桨团队发布的技术博文已在Hugging Face平台连续一周占据热度榜首,引发全球开发者热议。
最新消息显示,2025年5月飞桨团队推出的PaddleOCR 3.0包含三大核心能力:革命性的PP-OCRv5文字识别方案、升级版PP-StructureV3通用文档解析方案,以及原生适配文心大模型4.5的PP-ChatOCRv4智能文档理解方案。这款开源工具自2020年发布以来累计下载突破900万次,已被5,900多个开源项目引用,更是GitHub上唯一一个获得5万+星标的中国OCR项目。
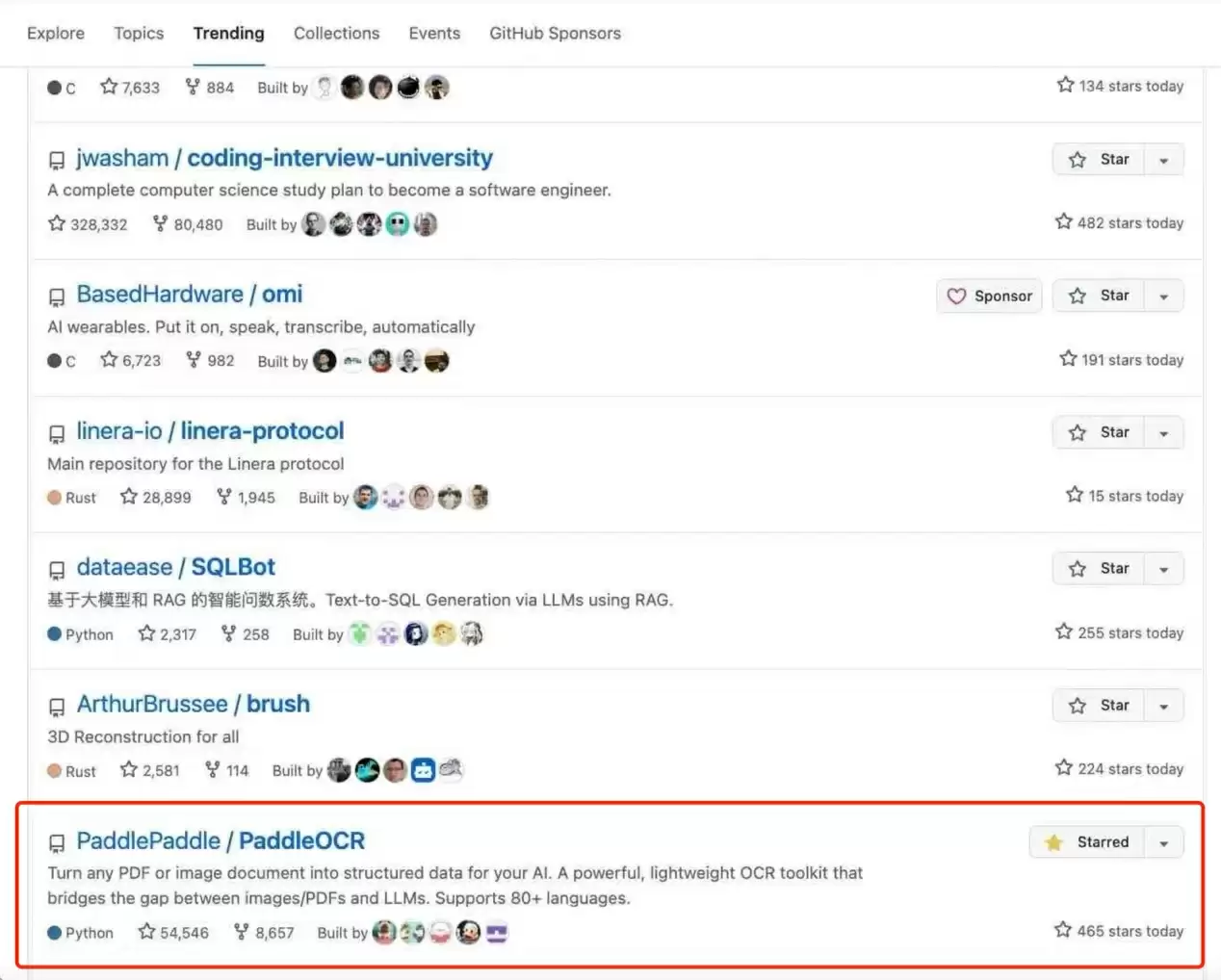
今年9月18日,PaddleOCR项目强势登陆GitHub全球热度榜,位列Python类第五名和总榜第十三位。
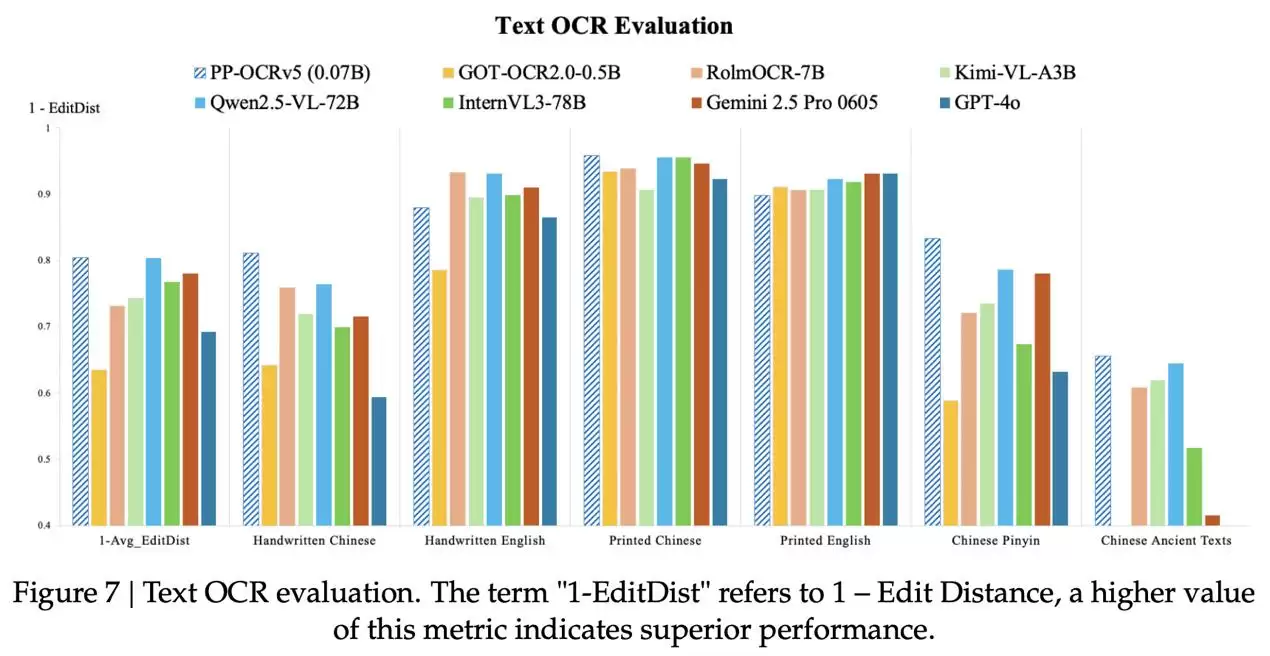
据技术博客分析,传统视觉大模型在OCR场景中存在明显短板,包括文本定位精度不足、边界框输出不稳定等问题,同时还伴随着巨大的计算资源消耗。相比之下,PP-OCRv5创新采用模块化双阶段检测机制,在保持轻量化优势的同时,显著提升了文本边界识别的准确性。
性能测试表明,PP-OCRv5在印刷体中英文识别任务上的表现与Qwen2.5-VL-72B这样的百亿级模型不相上下;面对手写中文、汉语拼音等复杂场景时,依然保持领先优势,展现出卓越的泛化能力。
作为飞桨团队打造的全新一代OCR解决方案,PP-OCRv5开创性地实现了单模型支持五种文字类型的突破,同时保持着超轻量级的优势...




