SWE-BENCH PRO软件工程基准测试引发新思考
最新发布的SWE-BENCH PRO测试结果显示,主流AI模型的表现在表面上不尽如人意:
GPT-5、Claude Opus 4.1和Gemini 2.5分别以23.3%、22.7%和13.5%的解题率位列前三。
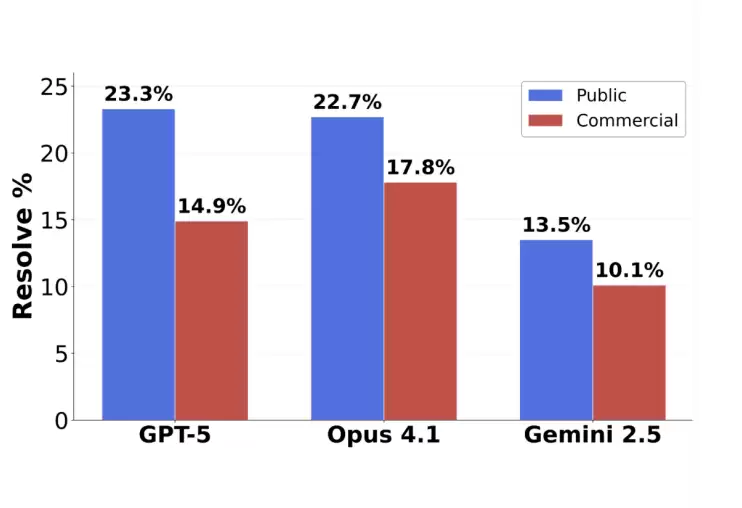
但更深层的数据分析揭示了有趣的现象。前OpenAI研究员Neil Chowdhury指出,仅就已回答题目而言,GPT-5的正确率高达63%,大幅领先Claude Opus 4.1的31%。
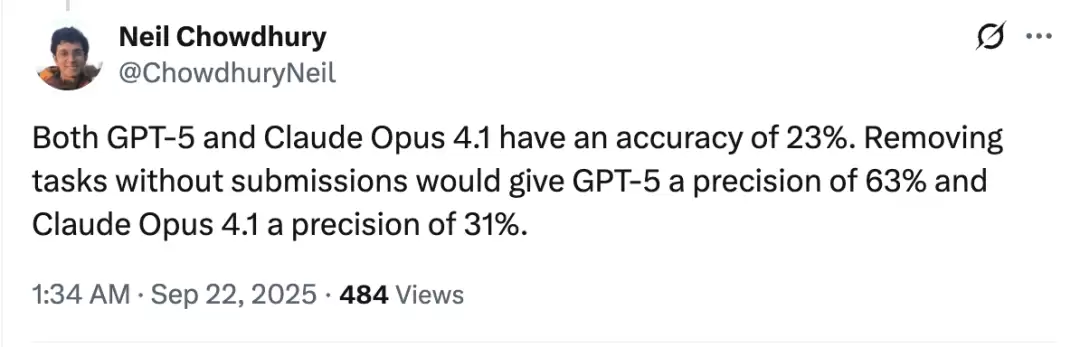
这一反差表明GPT-5在其擅长的领域依然保持强劲表现,与SWE-Bench-Verified基准中74.9%的成绩相差不大。
SWE-BENCH PRO测试特点
相较于SWE-Bench-Verified相对宽松的测试环境(平均70%的正确率),SWE-BENCH PRO的评估体系更为严格:
- 采用全新测试题目,避免训练数据污染
- 剔除简单的一两行代码修改任务
- 聚焦需要跨文件、数百行代码修改的复杂场景
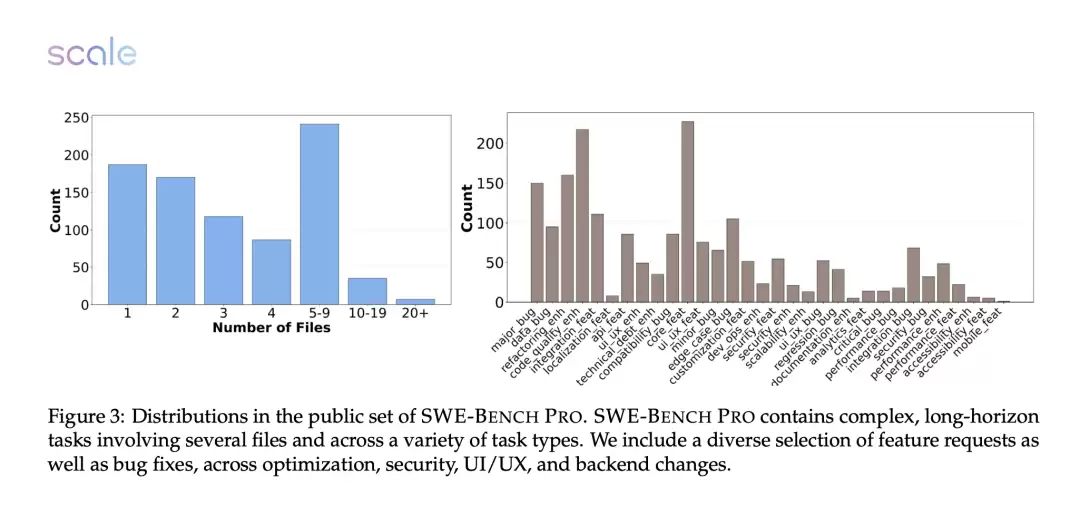
多样化的代码库构成
测试集包含1865个来自不同领域的代码库:
- 公共集:731个问题,来自11个开源代码库
- 商业集:276个问题,来自初创公司代码
- 保留集:858个问题,用于验证模型过拟合
严谨的评估流程
为保证测试有效性,研究人员采用了以下方法:
- 提供详尽的问题描述和上下文
- 明确列出各项需求及对应函数
- 在专业容器环境中执行测试
- 通过fail2pass和pass2pass双重验证
测试结果深度分析
整体表现来看,主流AI模型的解决率显著低于以往测试。
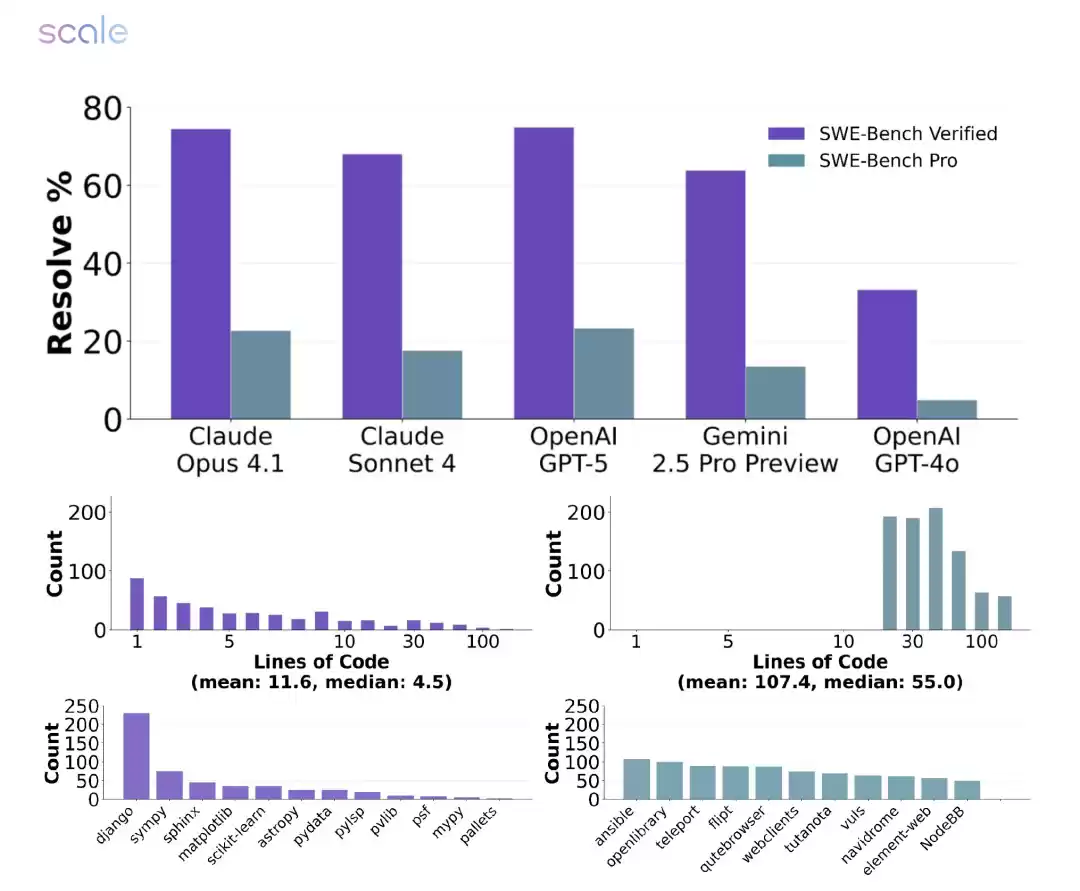
关键影响因素
- 编程语言难度:Go和Python表现较好,JavaScript和TypeScript波动较大
- 代码库特性:不同代码库的解决率差异可达40%以上
- 模型规模:前沿大模型表现更稳定,小型模型容易得零分
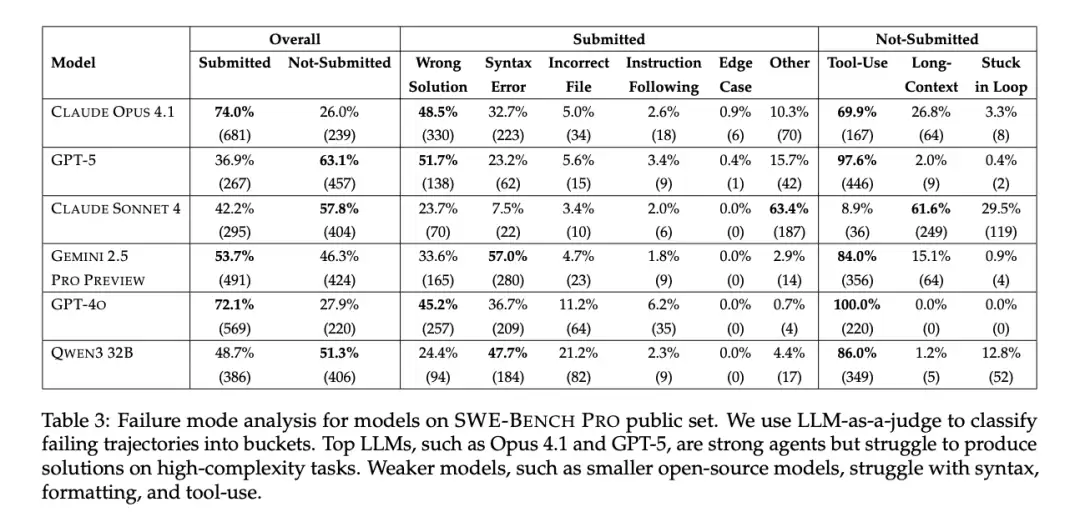
模型差异化表现
- GPT-5:已回答题目正确率高,但63.1%的未作答率拉低总分
- Claude Opus 4.1:语义理解能力需提升,35.9%的错误解答率
- Gemini 2.5:各项能力均衡,但无明显突出优势

相关参考:
- https://x.com/vbingliu
- https://scale.com/leaderboard/swe_bench_pro_public
- https://x.com/ChowdhuryNeil/status/1969817448229826798
- https://scale.com/research/swe_bench_pro




