8月27日最新消息,面壁智能于8月26日正式开源了其8B参数规模的MiniCPM-V 4.5多模态旗舰模型,这也是业界首款具备“高刷新率”视频解析能力的多模态人工智能系统。
据悉,MiniCPM-V 4.5在视频流畅度解析、长视频内容理解、光学字符识别及文档结构分析等维度均达到同规模模型的最优水准,其综合性能甚至超越了参数规模达72B的Qwen2.5-VL模型,被业界誉为“终端侧最强多模态模型”。

研发团队指出,传统多模态模型在处理视频内容时,由于需要兼顾计算效率与能耗控制,通常仅能采用每秒1帧的采样频率进行分析。这种处理方式虽能维持基本的推理效率,却不可避免地丢失了大量视觉细节,限制了模型对动态场景的精细化理解能力。
MiniCPM-V 4.5开创性地实现了高帧率视频解析技术,通过将原有的二维重构器升级为三维视频压缩架构,实现了对视频片段的密集型特征提取。在保持同等视觉令牌消耗的前提下,该模型可处理的视频帧数量提升至传统方案的6倍,视觉压缩效率达到96倍,整体性能较同类产品提升12至24倍。
凭借显著提升的采样频率,该模型实现了从“静态幻灯片式”观看向“动态场景式”理解的跨越式进步。面对快速变化的画面内容,MiniCPM-V 4.5在识别精度与细节捕捉方面均优于Gemini-2.5-Pro、GPT-5、GPT-4o等主流云端大模型。
在专门评估高帧率视频理解能力的MotionBench和FavorBench测试平台上,MiniCPM-V 4.5不仅取得同尺寸模型的最佳成绩,更在多项指标上超越72B参数的Qwen2.5-VL,展现出显著的性能优势。
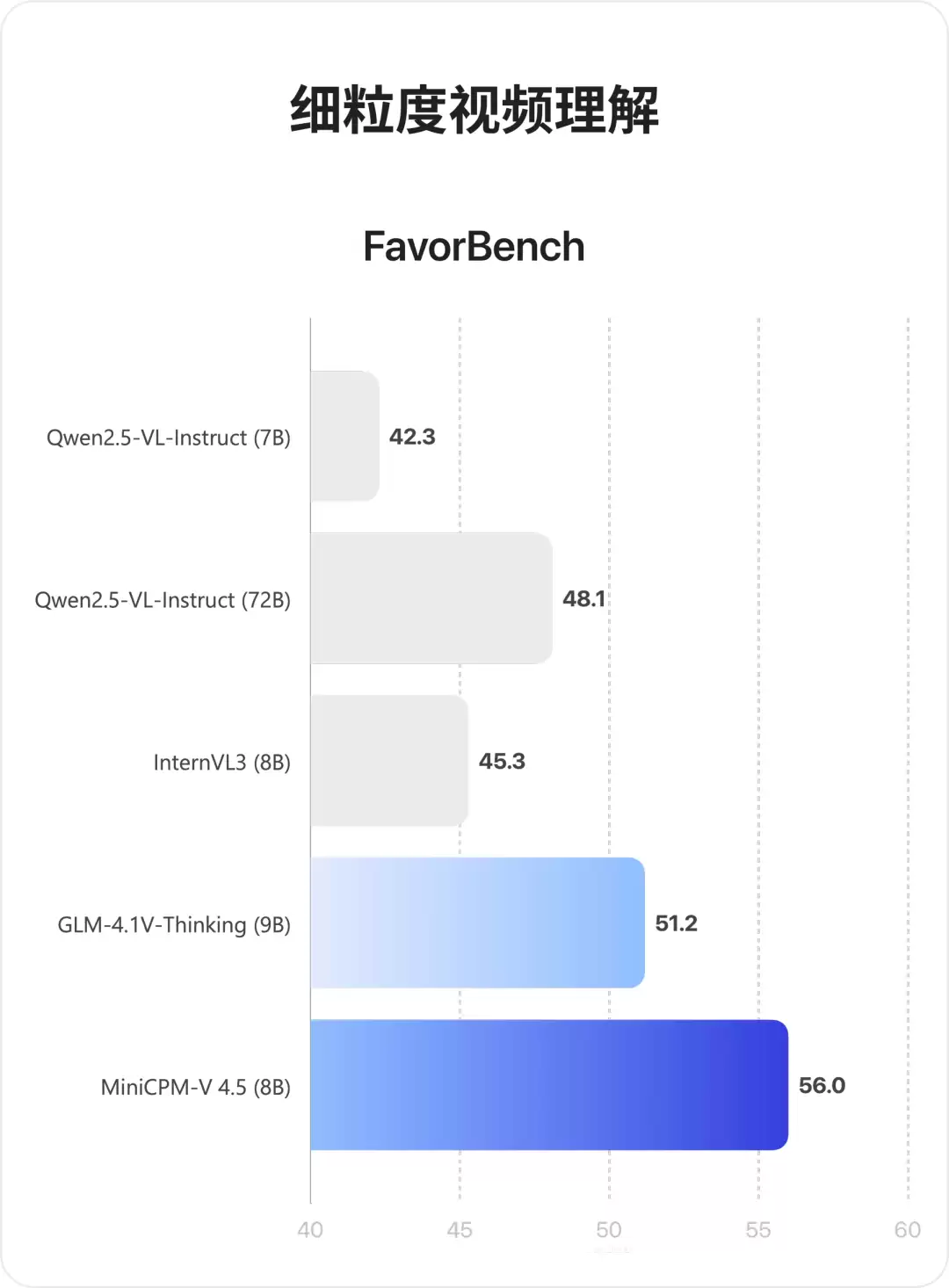
这款仅需8B参数的紧凑型模型,在图像理解、视频分析、复杂文档解析等多模态任务中持续突破性能瓶颈。

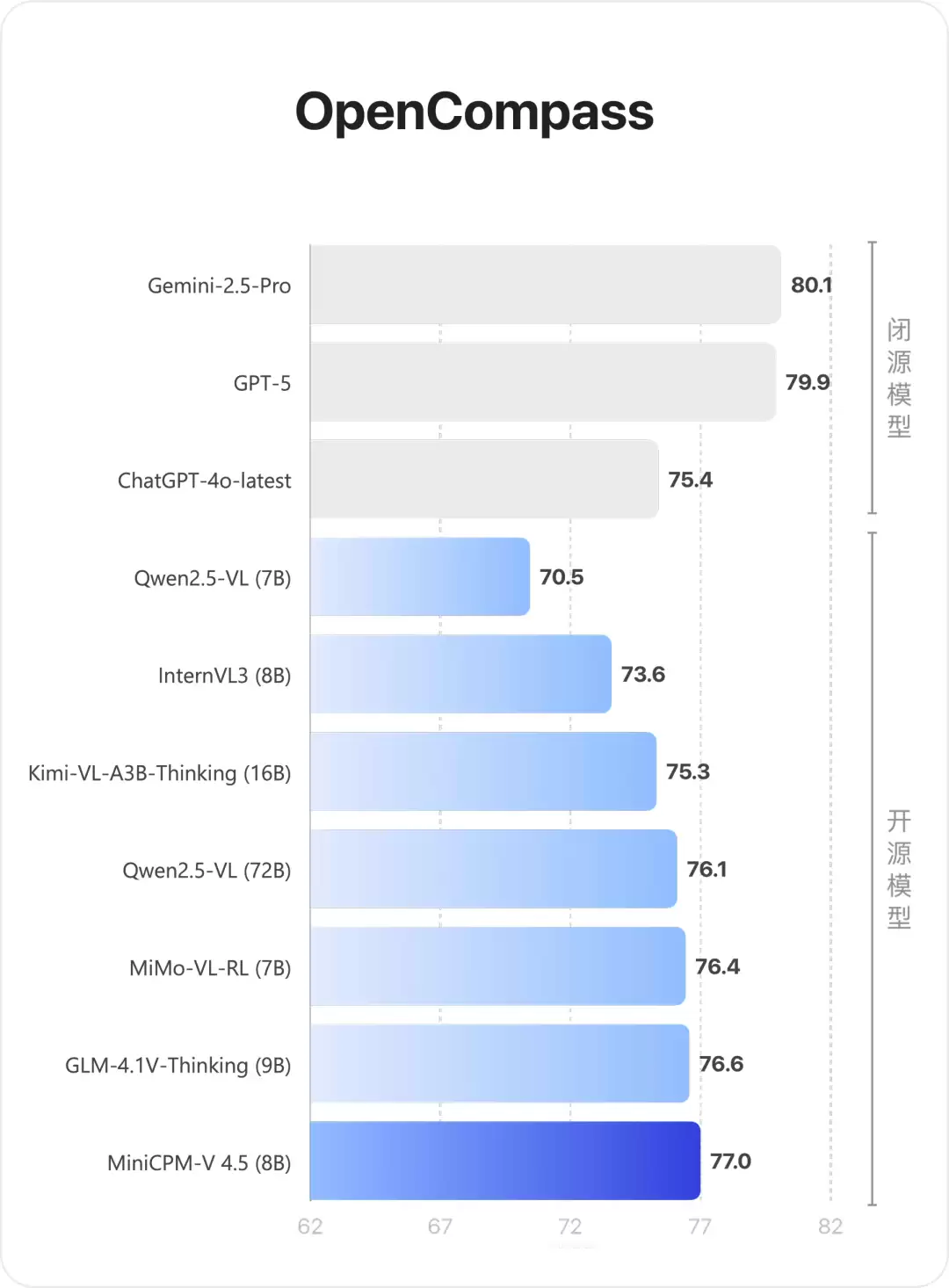
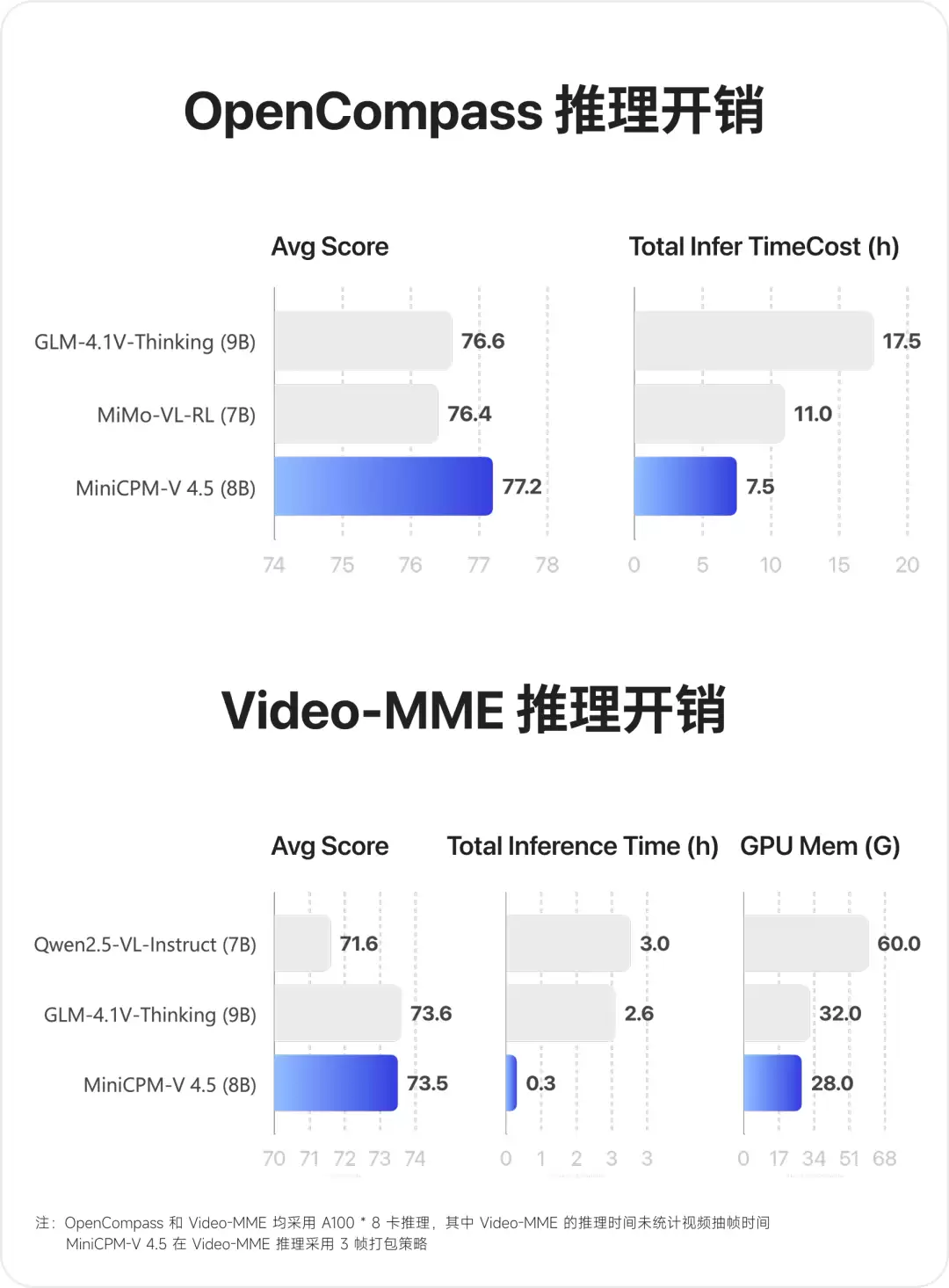
在图像理解维度,MiniCPM-V 4.5于OpenCompass综合评测中表现突出,不仅领先于GPT-4o、GPT-4.1、Gemini-2.0-Pro等多款闭源模型,更实现对72B参数Qwen2.5-VL的跨级超越。
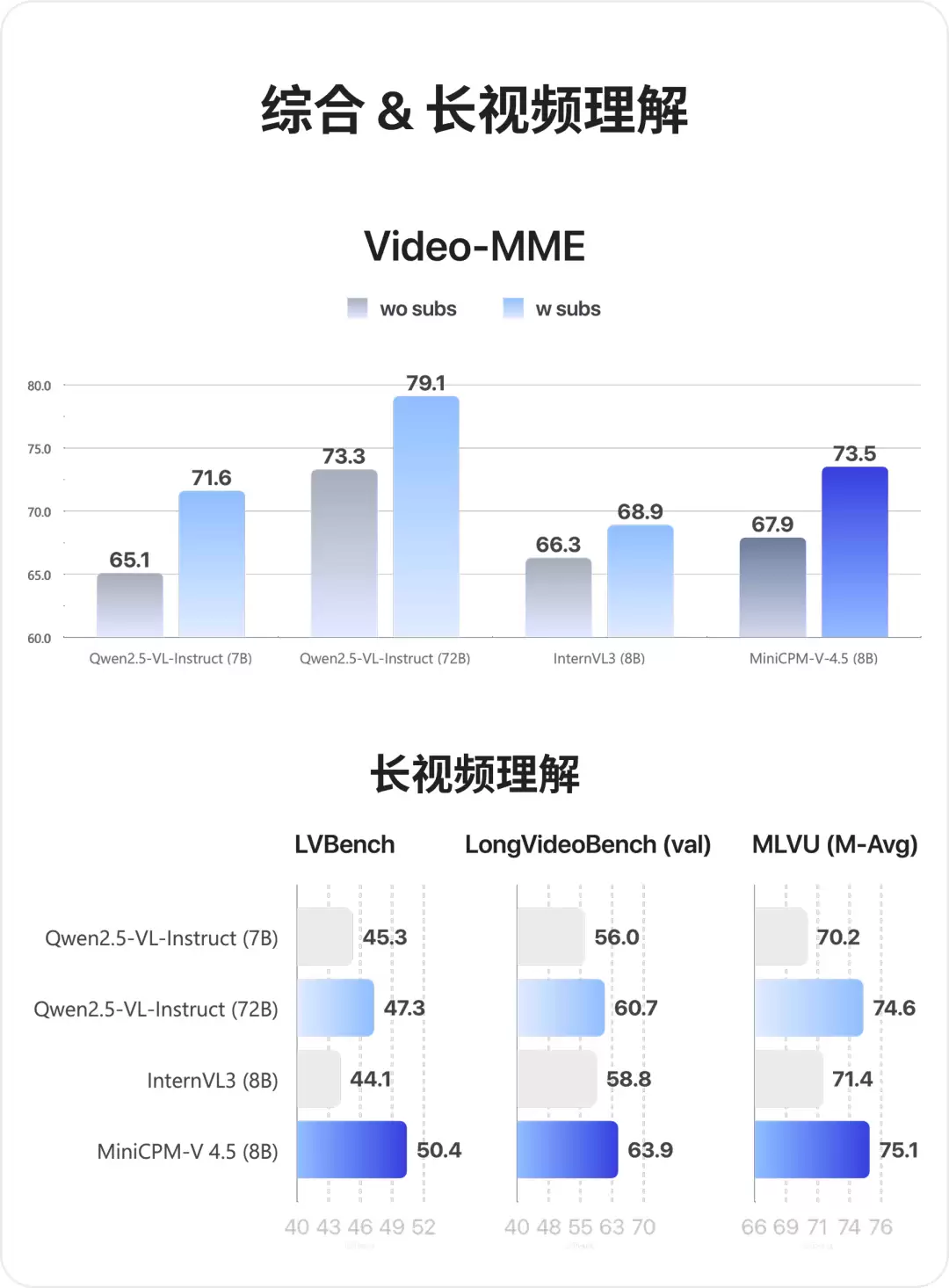
视频理解方面,该模型在LVBench、MLVU、Video-MME、LongVideoBench等权威测评体系中均取得同规模最佳成绩。
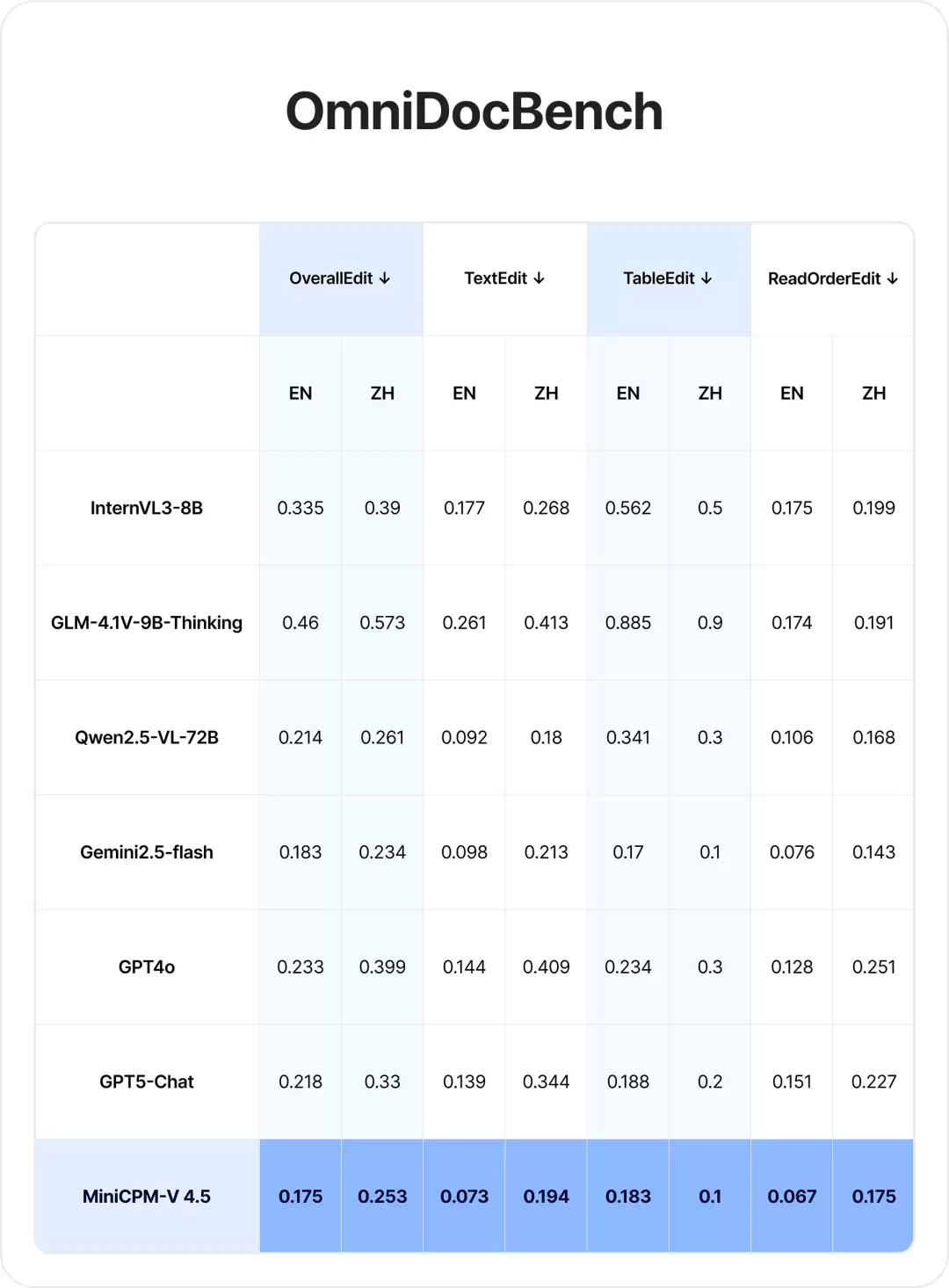
面对复杂文档解析任务,MiniCPM-V 4.5在OmniDocBench测评体系的OverallEdit、TextEdit、TableEdit三项核心指标中,均达到通用多模态模型的顶尖水平。
值得关注的是,该模型同步支持标准模式与深度思考双模式运行,在保证响应速度的同时兼顾复杂任务处理能力。标准模式适用于日常多模态场景,而深度思考模式则专为处理复合型推理难题设计。
在VideoMME视频理解测试与OpenCompass单图评测中,MiniCPM-V 4.5均达到同规格模型最优水平,并在显存占用、平均推理耗时等效率指标上保持领先。
特别是在涵盖短、中、长三类视频的Video-MME综合评测中,采用3帧打包推理策略的MiniCPM-V 4.5,其纯推理时间消耗仅为同级模型的十分之一(未计入视频采样耗时)。
附模型开源地址:
- Github:https://github.com/OpenBMB/MiniCPM-o
- Hugging Face:https://huggingface.co/openbmb/MiniCPM-V-4_5
- ModelScope:https://www.modelscope.cn/models/OpenBMB/MiniCPM-V-4_5




