在嵌入式FPGA领域,Zynq-7000系列一直是个绕不开的话题。它把ARM处理器和FPGA可编程逻辑整合在单芯片上,兼顾了软件灵活性与硬件加速能力。不过,真正要把深度学习推理塞进去,内存这块的约束往往是最先需要面对的坎。下面就来拆解一下关键点。
Zynq7000系列概览
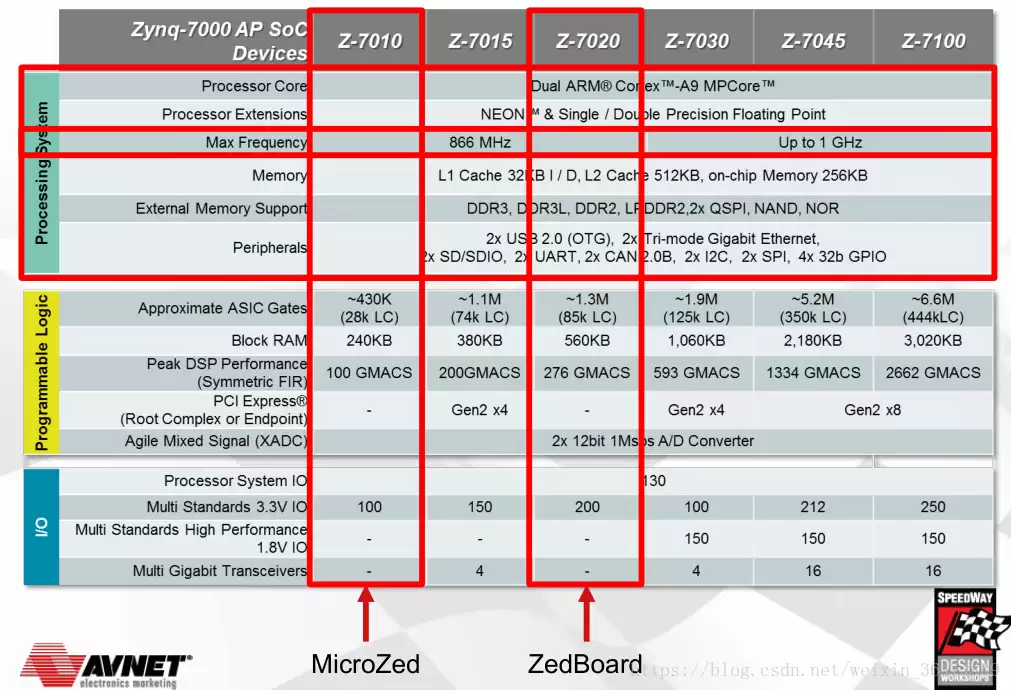
整个系列从双核Cortex-A9到不同规模的FPGA逻辑,覆盖了从入门到中高端的应用场景。但不论哪款型号,片上BRAM(块随机存取存储器)都是最金贵的资源——它直接决定了你能在片内塞下多大的模型权重。
内存占用
FPGA程序中内存的实现方式
参阅xilinx文档UG998,FPGA并没有像软件那样使用现成的cache。FPGA的HLS编译器会在可编程逻辑中创建一个专为算法数据样式优化的快速内存结构。因此,FPGA内部可以有相互独立、大小不一的存储空间,例如寄存器、移位寄存器、FIFO以及BRAM。
- 寄存器:最快的内存结构,直接集成在运算单元之中,获取数据不需要额外时延。
- 移位寄存器:可以看作一个数据序列,每个数据可在不同运算中重复利用,所有数据移动到相邻存储设备只需一个时钟周期。
- FIFO:只有一个输入和输出的数据序列,通常用于循环或循环函数,细节由HLS编译器自动处理。
- BRAM:集成在FPGA fabric模块中的RAM,每颗Xilinx FPGA都内置多个BRAM块。它的特性值得特别注意:不支持像处理器cache那样的缓存一致性(cache coherency/collision),也不支持处理器中常见的一些逻辑类型;只在设备有电时保持数据;不同BRAM块可以同时传输数据,实现并行访问。
Zynq的BRAM内存大小
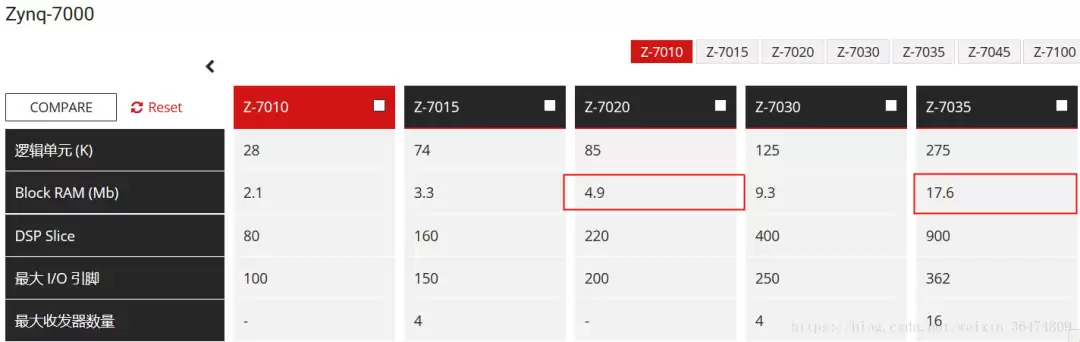
具体来看,Zynq 7z020的BRAM容量为4.9Mb(约0.6MB),而7z035则提升到17.6Mb(约2.2MB)。这个数字决定了你能在片上直接存储的模型规模上限。
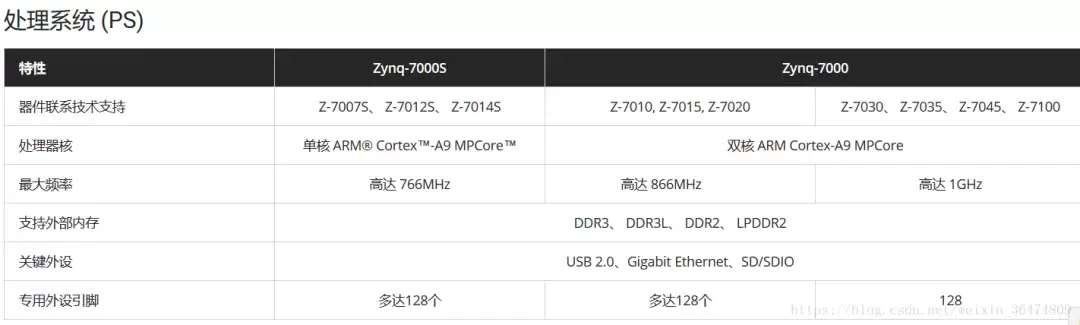
一个卷积操作占用的内存
举个例子,假设硬件需要实现一个卷积函数:输入维度27×600,卷积核16×27,输出16×600,数据类型为float。对应的C代码片段如下:
//convolution operation
for (i = 0; i < 16; i++) {
for (j = 0; j < 600; j++) {
result = 0;
for (k = 0; k < 27; k++) {
temp = weights[i*27+k] * buf_in[k*600+j];
result += temp;
}
buf_out[i*600+j] = result;
}
}使用HLS综合生成IP核后,硬件资源占用情况如下:
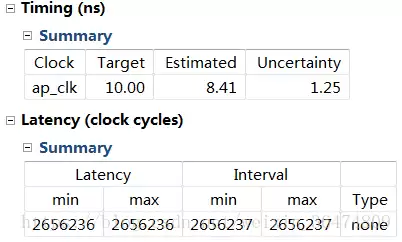
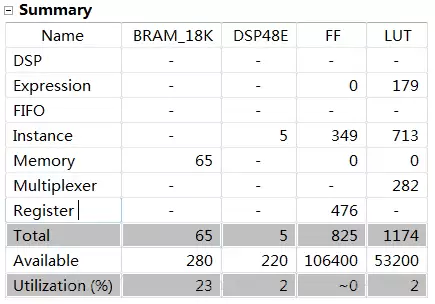
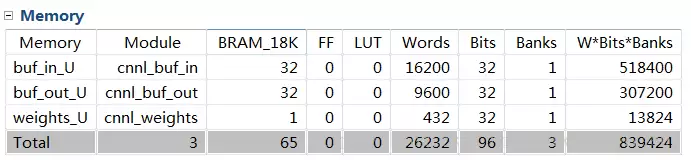
在Vivado中搭建完整系统后,最终占用的资源统计:
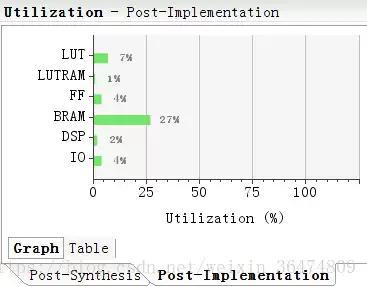
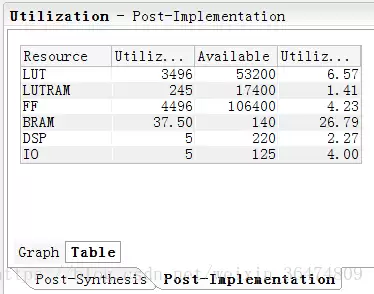
可以看到,一个中等规模的卷积操作就会消耗不少LUT和DSP,而BRAM的占用同样不容忽视。
PipeCNN可实现性
PipeCNN是一个基于OpenCL的FPGA翻跟斗框架,专门用于实现大型卷积神经网络。它最大的价值在于提供了一套相对成熟的硬件映射方案。
PipeCNN论文解析:用OpenCL实现FPGA上的大型卷积网络加速。(相关论文和源码可自行检索,此处不再列出外部链接。)
已实现的PipeCNN资源消耗
对于Altera FPGA,可以使用Intel's OpenCL SDK v16.1工具集;对于Xilinx FPGA,则可使用SDAccel开发环境(v2017.2)。

已经有Xilinx的KCU1500(搭载XCKU115 FPGA)成功运行过PipeCNN,不过这个芯片属于更高端的Kintex UltraScale系列,资源规模远超Zynq-7000。
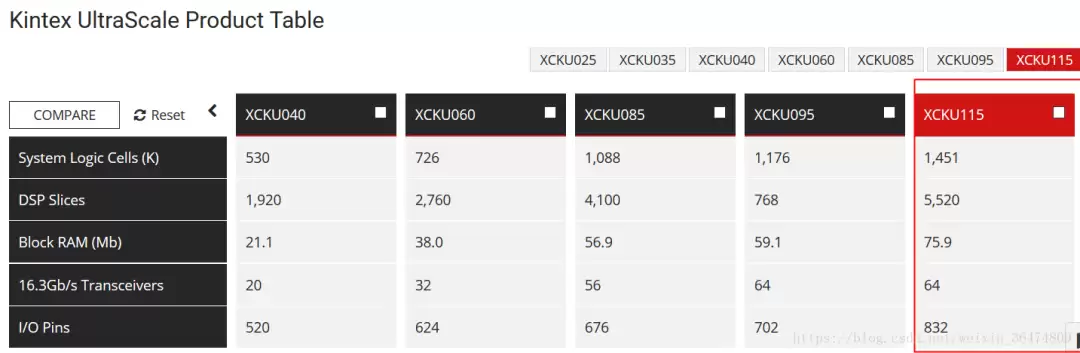
PipeCNN的硬件资源可以通过三个宏来调控(在device/hw_param.cl中定义):
- VEC_SIZE
- LANE_NUM
- CONV_GP_SIZE_X
不同参数组合下的资源消耗对比如下:
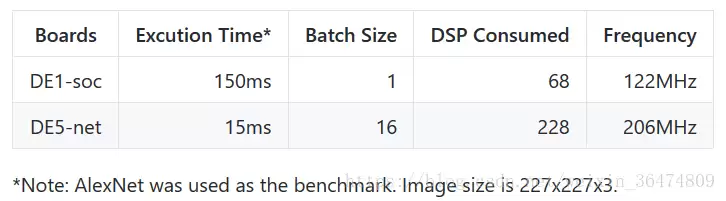
从数据看,即使经过调优,PipeCNN在高端FPGA上依然会消耗大量DSP和BRAM,对于Zynq-7000这类资源有限的平台,直接移植会非常吃紧。
实现大型神经网络的方法
既然片上BRAM容量有限,又想跑大型网络,常见的思路无非以下三条:
方案一:压缩模型到2.2MB以内,完全放入BRAM
优点:速度快,实现相对简单。
缺点:模型压缩难度大,且难以支持真正的大型网络。
方案二:用FPGA直接访问DDR
优点:速度中等,可实现大型网络。
缺点:调用DDR涉及到总线协议和复杂的数据搬运,开发周期长。
方案三:用片上单片机读取DDR(例如插入SD卡),分包传入IP核计算
优点:可实现大型网络。
缺点:速度较慢,受限于单片机与外设的数据吞吐。
这三种方案各有适用场景,实际选型需要根据带宽要求、开发时间和成本综合权衡。
Virtex-7高端FPGA概览
Virtex-7是Xilinx的旗舰级FPGA,定位比Zynq高了一整个档次。它的逻辑资源、DSP数量和BRAM容量都远超Zynq系列,适合做大型原型验证或高性能计算。
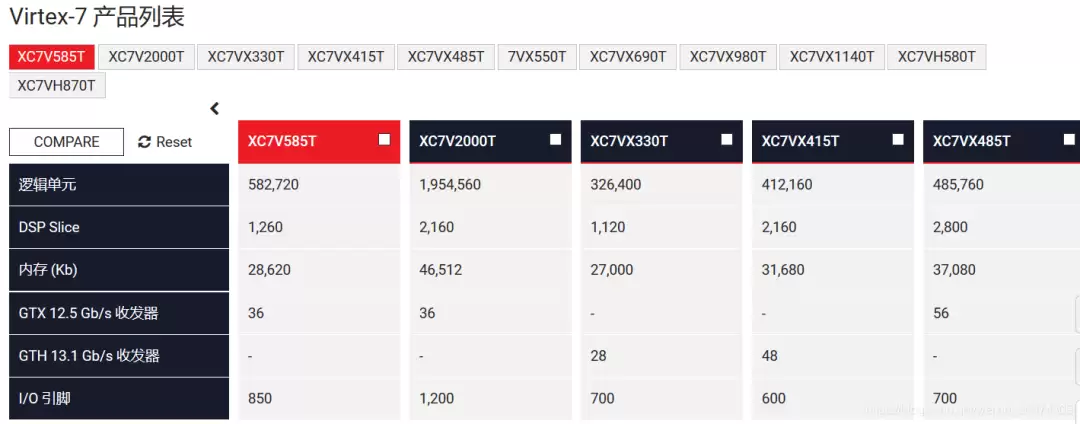
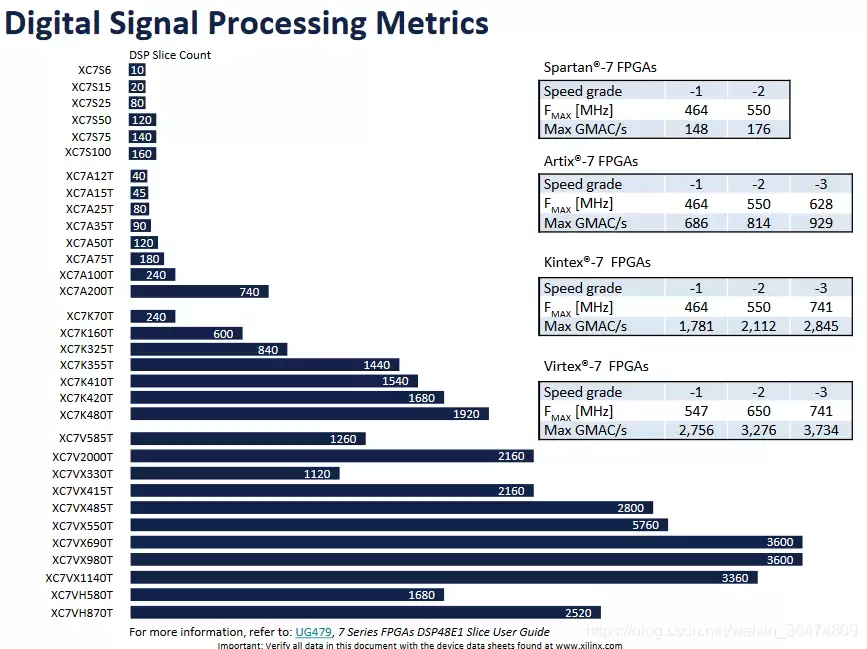
7系列FPGA相关文档可从Xilinx官网获取,这里不再赘述。

总结一下:在Zynq上做卷积加速,最核心的瓶颈就是片上BRAM。如果模型可以压缩到2MB以内,那方案一最省心;否则就得考虑DDR方案,随之而来的就是更长的开发周期和更复杂的数据流设计。理解这些权衡,才能做出务实的技术决策。