一个完整的医疗影像推理流程,通常包括数据预处理、AI 推理与数据后处理几个核心环节。在 GPU 加速的 AI 推理方面,TensorRT、TensorFlow 或 PyTorch 等框架已经提供了成熟的解决方案,但数据的前后处理往往默认在 CPU 上执行。对于 CT 或 MR 这类三维图像,当数据量较大时,CPU 上的前后处理极易成为整个推理链路的性能瓶颈——不仅推理延迟增加,GPU 资源也会被闲置浪费。此外,医疗影像推理的部署同样需要细致规划:实际场景中,常常需要同时运行多个 AI 应用,如何高效调度模型、并发处理请求、充分榨取 GPU 算力,这些都是真实存在的挑战。
什么是 MONAI
MONAI 是一个专为医疗图像深度学习而设计的开源框架。它的目标十分明确:
- 搭建一个由学术界、工业界与临床研究人员共同协作的社区;
- 为医疗图像构建端到端的最先进工作流程;
- 为研究人员提供一套标准化且经过优化的方法,用于创建和评估深度学习模型。
MONAI 内置了丰富的 transforms,用于医疗图像数据的前后处理。在 0.7 版本中,MONAI 在 transforms 里引入了基于 PyTorch Tensor 的计算能力——许多 transforms 既支持 NumPy array,也支持 PyTorch Tensor 作为输入类型和计算后端。当数据以 PyTorch Tensor 形式输入时,便可利用 GPU 加速前后处理的计算,从而绕过 CPU 瓶颈的限制。
什么是 NVIDIA Triton 推理服务器
Triton 推理服务器是一款开源 AI 模型部署软件,专为大规模深度学习推理而设计。它能够将 TensorFlow、TensorRT、PyTorch、ONNX Runtime 等框架训练好的模型部署到任何 GPU 或 CPU 环境中——无论是云端、数据中心还是边缘设备。Triton 的核心优势在于提供高吞吐量的推理,从而最大化 GPU 利用率。
在较新版本中,Triton 新增了 Python backend 特性,旨在让开发者更方便地部署用 Python 编写的模型,无需手动编写 C++ 代码。某些场景下,推理流程中会包含循环、条件判断、依赖运行时数据的控制流,或者需要将自定义逻辑与已有模型混合执行。借助 Python backend,这些控制流的实现变得简单直接,甚至可以在 Python 模型中调用 Triton 部署的其他模型,灵活性显著提升。
使用 MONAI 和 Triton 高效搭建和部署 GPU 加速的医疗影像推理流程
下面我们通过一个具体实例,展示如何利用 MONAI 的 GPU 加速数据处理以及 Triton 的 Python backend,构建一条完全运行在 GPU 上的医疗影像推理流程。通过这个案例,可以直观感受到在 GPU 上进行数据处理带来的性能提升,以及如何借助 Triton 实现高效推理部署。
整个推理流程如下图所示,包含数据预处理、AI 模型推理与数据后处理三部分。
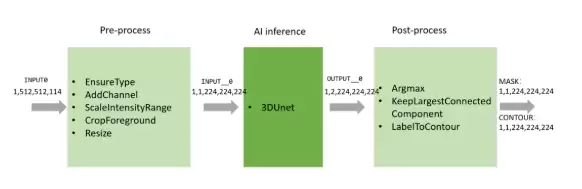
通过 EnsureType 这个 transform,输入数据被转换成 PyTorch Tensor 并直接放置到 GPU 上,后续所有预处理操作均在 GPU 上完成。AI 模型选用 3D U-Net,推理后端采用 Triton 的 Torch backend,输出的结果同样保留在 GPU 上,作为后处理模块的输入,继续在 GPU 中完成计算。
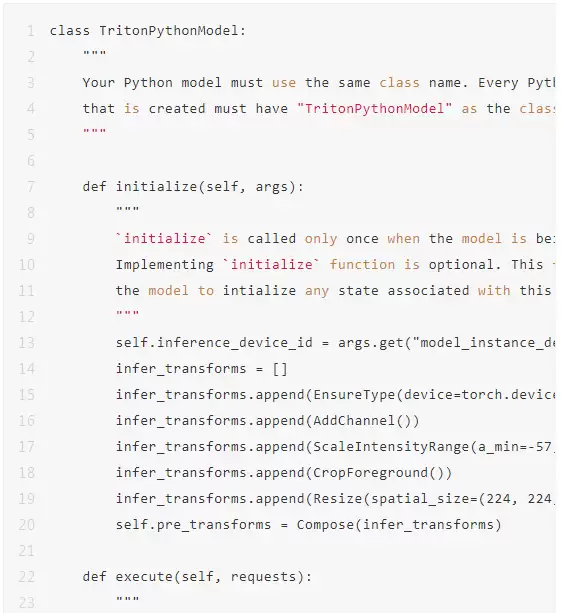
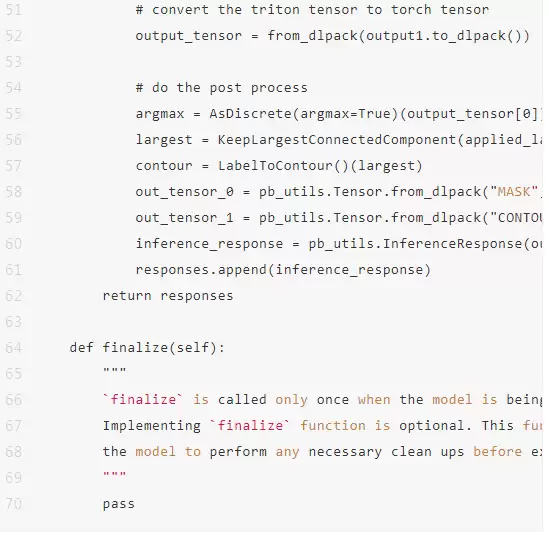
利用 Triton 的 Python backend,可以轻松地将整个流程串联起来:按照 Python backend 所要求的模型结构,编写前后处理的 Python 代码,并在其中调用 3D U-Net 的推理。以下是示例代码片段。

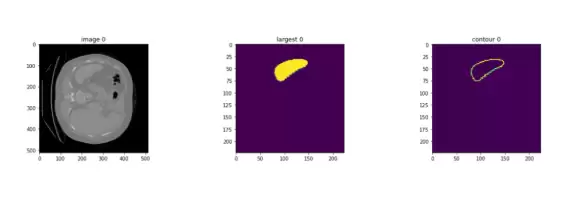
以 MSD Spleen 3D 数据集作为输入,经过完整流程后,可以得到脾脏区域的分割结果及其轮廓,效果如下图所示。
性能测试
我们在 RTX 8000 上对整套流程进行了性能测试,重点对比了 Triton 与 MONAI 不同特性对性能产生的影响。
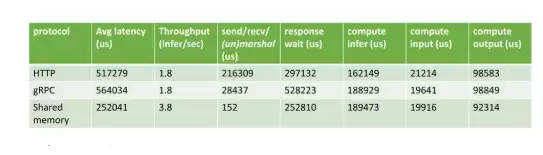
HTTP vs. gRPC vs. shared memory
Triton 支持 HTTP、gRPC 以及共享内存等多种数据通信方式。由于三维医学图像通常体积较大,通信开销不可忽视。许多医疗 AI 应用场景中,客户端与服务器部署在同一台机器上,此时共享内存便成为减少收发开销的有效手段。测试结果很直观:当数据量较大时,使用共享内存能够显著降低延迟。
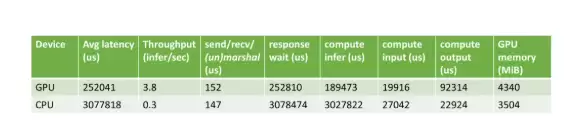
Pre/Post-processing on GPU vs. CPU
接下来对比了在 GPU 和 CPU 上进行前后处理时的整体推理速度。结果相当显著:将数据处理迁移到 GPU 上,可以实现约 12 倍的加速效果。