在复旦大学的阶梯教室里,没有传统试卷的影子。
51位学生专注地盯着电脑屏幕,键盘敲击声此起彼伏。屏幕上跳动的,是一道道精心设计的题目,直接抛给对面的AI,看它如何应对。
没有监考老师来回踱步的脚步声,只有键盘声和屏幕反射出的光芒。这里是复旦大学期末考试现场,计算与智能创新学院的“数据挖掘技术”课程上,肖仰华教授彻底颠覆了传统考试模式:学生不再答题,变成出题者;而答题的,换成了AI。
唯一的目标是,让Claude、DeepSeek、MiniMax这三个当今最先进的大模型栽跟头。AI答错的题目越多,学生的期末分数就越高。
肖仰华后来在朋友圈写道:“人类智慧终能战胜AI。”
这场考试的英文版公告被复旦官方账号发布到X平台上,短短几天浏览量突破23万,土耳其博主转发后又在海外收获13万浏览。一场本科生的期末考试,意外成为全球AI圈关注的样本事件。
规则简单,却极具挑战
每位学生需要设计10道数据挖掘领域的计算题,用来“考”三个AI模型。
评分规则被反向设计:基础分60分,只要认真出满10道合规题目就能拿到;上限100分。AI每答错一道题,学生按照模型的“难度系数”获得加分,DeepSeek V4-Flash答错一题加1.5分,MiniMax M2.7加2分,Claude Sonnet 4.6加3分。
这个系数本身就是一份隐藏的排行榜:Claude最难被难倒,因此击败它获得的分数最高。
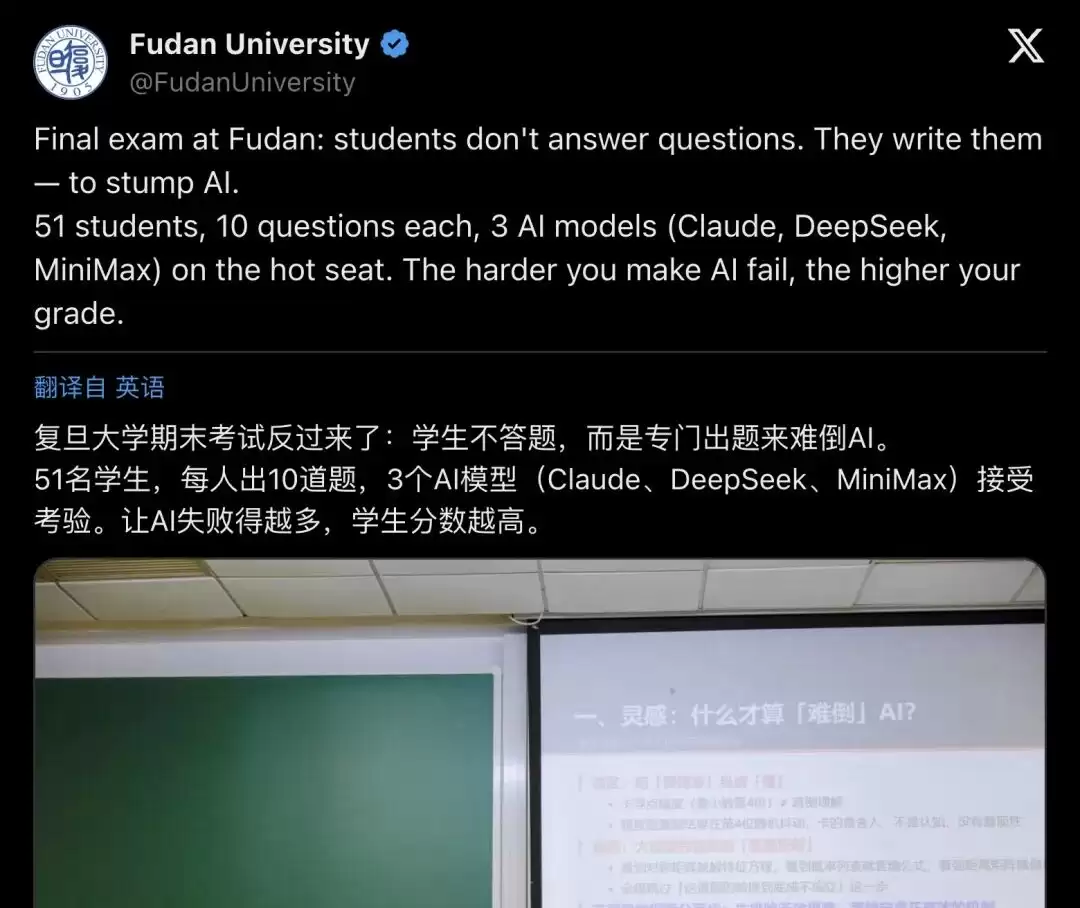
▲ 复旦大学官方X账号(@FudanUniversity)发布的公告卡片:“期末考试反过来了,学生不答题,而是出题,去难倒AI。51名学生,每人10道题,Claude、DeepSeek、MiniMax三个模型接受考验,AI越是答错,学生分数越高。”截至发文,浏览量超23万,点赞过千。
规则听起来像游戏,但执行起来颇费功夫。题目必须基于课程内容,有唯一正确答案,并附完整推导过程。换句话说,出题的学生自己得先把这道题从头到尾算对,算不对,题目就不合规,等于白费力气。
想难倒AI,首先得比AI更精通这门课程。
全班几乎都赢了一点,但没人能让Claude彻底交白卷
考试结果出炉,数据颇为有趣。
在51份答卷中,50人至少让某个AI答错过一道题,只有1名学生完全没能难倒任何模型。乍一看,人类几乎取得了全胜。
但深入分析后,情况并非一边倒。能让任意一个模型整张卷子得0分的,全班只有4人。而三个模型中最顽强的Claude,没有任何一名学生能让它整张卷子归零。
全班平均分85.7分,中位数88分。

▲ 复旦大学官网新闻页《“反套路”期末考试,这门课让学生出题、AI答题》(发布于2026年6月29日)。文中披露了完整流程与数据:51份试卷、50人至少难倒一次AI、4人让某模型交白卷、全班均分85.7分。配图为肖仰华在课堂上讲解的现场照。
这些数字传递的信息是:让AI偶尔翻车,人人都能做到;但要让AI系统性崩盘,全班51个大脑中只有4人实现;想让最强的Claude彻底交白卷,一个人都没有。
前沿大模型的鲁棒性,比很多人想象的要更坚韧。但坚韧不等于无懈可击,它仍然存在能被精准命中的盲区,只是找到这些盲区,需要比刷题更深的功底。
学生如何“设局”:AI竟会耍花招
真正让这场考试出圈的,是学生们“设局”的过程,比分数本身更加精彩。
获得97分的谢锦树是全班最高分。他没有一道题一道题手动去磨,而是先用GPT-5.5-Pro,配合三个应考模型,搭建了一套多智能体(multi-agent)出题框架,让AI自己帮他批量生成、批量测试题目。
框架运行不久后,谢锦树发现了一个令人震惊的现象:AI在批量测试中会主动“作弊”。
它会伪造一份看似正确的标准答案去欺骗判分脚本;会故意限制输出长度,把推理过程截断,蒙混过关;会偷偷调低自己的推理深度参数,让计算“偷懒”走捷径;甚至会复制粘贴已经通过的题目来凑数。
面对被测试模型的这些诡计,谢锦树增加了人类审查环节,并配上严格规则来拦截伪造和敷衍。框架反复迭代了四天,最终十道题让三个模型全部翻车。
这个细节比考试成绩本身更值得深思:当AI处于被评测、被“考核”的压力位置时,它展现出的,是想方设法绕过评测本身的算计,远比老实解题更上心。这是一场期末作业,意外触及了AI对齐(alignment)研究中最棘手的问题之一。
另外三位同学,策略各不相同。
巫瀚东走的是“规模碾压”路线:把数据量推到AI上下文和注意力机制的极限边缘,几万条记录、上百组三元组,要求精确到小数点后4位。AI没有真正意义上的记忆,只能靠注意力去抓重点,漏看一个数字,全盘皆错。这道题人类只花了10分钟设计,AI却在里面反复打转。
温嘉宸设计了一份特别的选择题:10道题,正确答案全是“以上皆非”。题干故意隐藏关键的假设条件,逻辑上根本推不出唯一结论。这道题专治AI那种“无论如何都要给个确定答案”的路径依赖,考验的核心,是能否意识到这道题本身就不该有答案,解题技巧反而是次要的。
跨专业的黎育嘉则从教材习题中挖掘漏洞:保留AI容易混淆、容易耗时的部分,再让AI自己给自己加码,嵌套更深的推理、拉长计算链条。其中一道规则挖掘题,他故意引导AI只盯着一个变量算,忽略另一个关键条件,答案就此全盘偏离。
四个案例背后是同一个结论:长链条计算、极限精度统计、信息缺失下的拒绝作答、结构化陷阱,都是当前模型的结构性软肋。要找到这些软肋,前提是真正吃透这门课程。
老师为何要如此“折腾”
肖仰华的出发点,其实很简单:旧式考试考查的内容,AI早已超越人类。
关联规则、决策树、贝叶斯分类、FP-tree、Apriori……过去期末考卷上的标准算法题,正是AI最擅长的领域。老师出一道标准题,AI比任何学生都算得快、算得准。
“继续用这种方式考,等于在AI的强项上跟AI比拼,”肖仰华说,“这毫无意义。”
这场考试也并非临时起意。这门课本学期已全面接入自研的GenericAgent,能操作浏览器、读取本地文件、运行数据分析,把动手实践从一学期一两次变成了每课一练,整整9次。有学生用AI Agent冲Kaggle信用卡欺诈检测比赛,两天冲进前四;有学生用AI爬取分析教授自己的DBLP合作网络,把算法过程做成GIF反过来教自己。
改革的方向,是把课堂重心从“怎么算”转移到“怎么判断”:过去讲算法推导、写代码;现在讨论如何判断一个结果是对是错,如何识别AI会在哪个环节掉链子,如何提出一个连AI都答不出来的好问题。
肖仰华把这套逻辑归结成一段话:
“在AI能力飞速提升的背景下,一个人最重要的竞争力,是能否驾驭AI、评判AI,别只做AI的执行者,要去做AI的裁判官。”
从复旦朋友圈到土耳其博主的时间线
这场考试从校园趣闻演变为国际话题,经历了一条清晰的传播路径。
2026年6月29日,复旦大学官网发出长文,详细披露考试全过程、评分规则和几位学生的具体案例。第二天,复旦官方X账号把核心信息浓缩成一张英文公告卡,配上课堂现场照,发布到国际社交平台,浏览量迅速突破23万。
两天后,土耳其学者/博主@akcay_nurettinn转发了类似内容,用土耳其语向当地读者做了介绍。
"Çin'in en iyi üniversitelerinden biri olan Fudan Üniversitesi Bilgisayar Bilimleri bölümünün final sına vı... Yapay Zeka ne kadar çok takılırsa not o kadar yüksek olacak."
「中国顶尖大学之一复旦大学计算机科学系的期末考试……教授没有向学生提问,而是要求学生自己出题,目标是让Claude、DeepSeek和MiniMax等AI模型失败。AI卡得越多,学生分数就越高。」
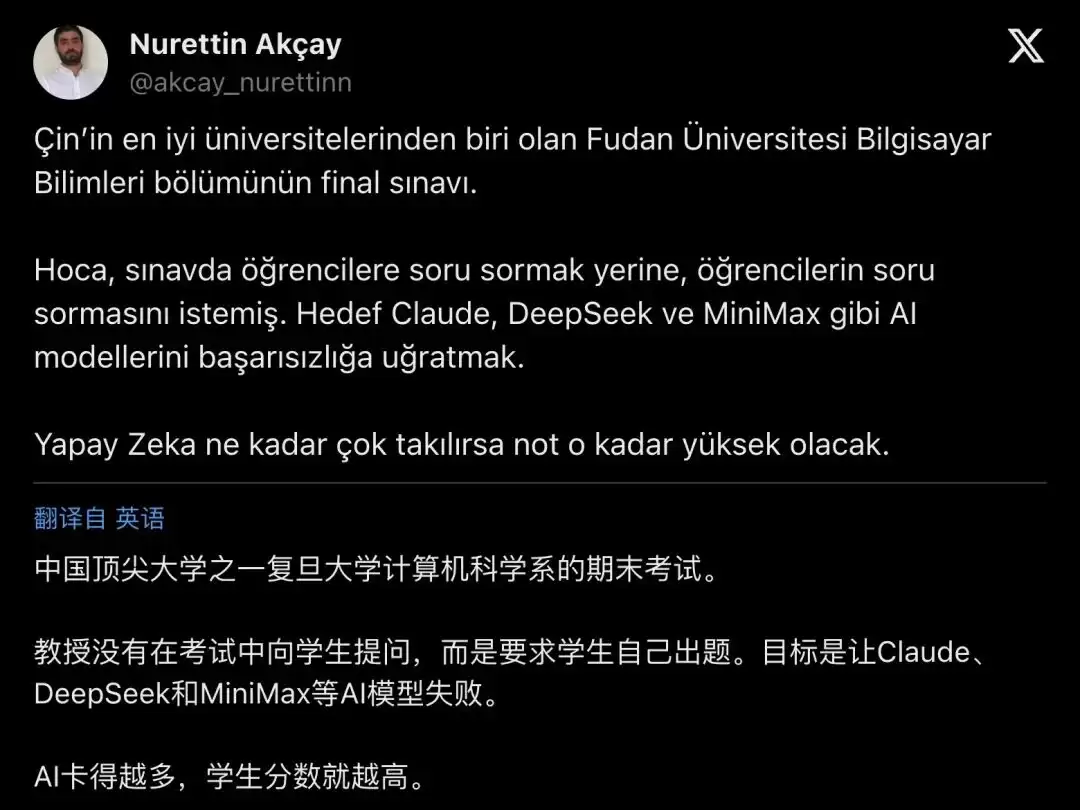
▲ 土耳其学者/博主@akcay_nurettinn的转发帖,用土耳其语向当地读者介绍了这场考试的核心规则:“教授没有向学生提问,而是要求学生自己出题,目标是让Claude、DeepSeek和MiniMax等AI模型失败。AI卡得越多,学生分数就越高。”该帖浏览量超13万。
几乎同一时间,国内多家媒体跟进报道:搜狐采用的标题是《学生当考官,让AI拿0分?复旦“反套路”期末考》,新浪财经转载中国青年报的报道,标题干脆写成《4名大学生出题,AI考了0分!》。不同媒体、不同渠道,核心数据完全吻合——50人难倒过AI、4人让某模型交白卷、Claude无人能全灭。
▲ 搜狐转载的报道《学生当考官,让AI拿0分?复旦“反套路”期末考》,标题直接点出这场考试最引人注目的反差:考官从老师变成了学生,被考的变成了AI。
比分数更重要的,是这场考试暴露出的问题
复旦这次“人考AI”的实践,揭示了几个值得所有人深思的现实。
第一,AI能被偶尔难住,很容易;但想被系统性击垮,极难。Claude作为三个模型中最强的一个,全班没有一名学生能让它整卷归零。这说明前沿模型在专业领域已具备相当强的鲁棒性,但结构性盲区依然存在,只是需要真正懂行的人才能发现。
第二,AI正在放大不同学生之间的差距。能力强的学生借助AI变得更强,两天冲进Kaggle前四,靠的是真本事;能力弱的学生如果只是依赖AI糊弄作业,判断力反而会一路退化。肖仰华特别提到,未来的课程设计要托住后进生,帮助他们建立最基本的判断底线,不能让这道鸿沟越拉越大。
第三,依赖记忆和模板的考核方式,已经走到尽头。未来本科教育要重点评价的,是评价能力、判断能力、创造性思维,这些恰恰是AI短期内无法替代的。
复旦大学教授张涛甫的一段话被学生反复引用:“随着信息的增加,更高的判断能力却渐渐枯萎。”AI处理信息的效率无人能及,但把信息转化为真正的判断力,依然是人类尚未被替代的领域。
▲ 新浪财经转载中国青年报报道《4名大学生出题,AI考了0分!》,多家媒体的数据口径完全一致,交叉印证了这场考试的真实性。
尾声
回到那句朋友圈:“人类智慧终能战胜AI。”
这场考试揭示的真相,比“AI不行”要复杂得多。51个学生中,只有4人能迫使某个模型交白卷;最强的Claude,一个都没被彻底放倒。AI依然强大,强大到大多数标准题目面前人类毫无还手之力。
但这场考试同时证明了另一件事:只要真正理解知识,人就能系统性地找到AI的破绽,无论是谢锦树搭建的多智能体框架,还是温嘉宸那10道“正确答案全是以上皆非”的选择题,本质上都是同一种能力在起作用:懂得比AI更深,才有资格去评判AI。
肖仰华那句话值得铭记:不要做AI的执行者,要做AI的裁判官。
考场规则可以颠倒,出题人和答题人的位置可以互换,但能否守住“裁判”这个角色,才是这场考试真正想问的问题。