本周,Anthropic 团队一口气发布了两篇相互关联的大模型内部机制研究报告,可以说是继去年他们首次揭开大模型黑盒之后,又一次里程碑式的进展。这次,他们搭建了一套“AI 显微镜”——一个替代模型(replacement model),然后用它仔仔细细地追踪大模型在推理时的“思维”过程。
核心内容其实就三块:
- 他们造出了这个“AI 显微镜”,用来追踪大模型的思维链条。
- 通过这个显微镜,他们绘制出了归因图(attribution graph),展示了模型在每一步推理中特征之间的互动。
- 最后,他们把显微镜对准了 Claud 3.5 Haiku,剖析了它在诗歌创作和多语言处理等场景下的内部工作机制。
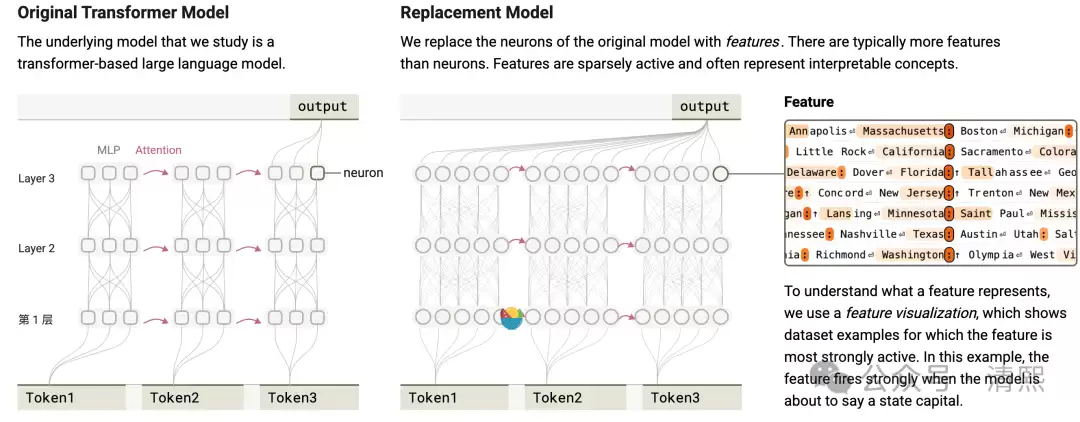
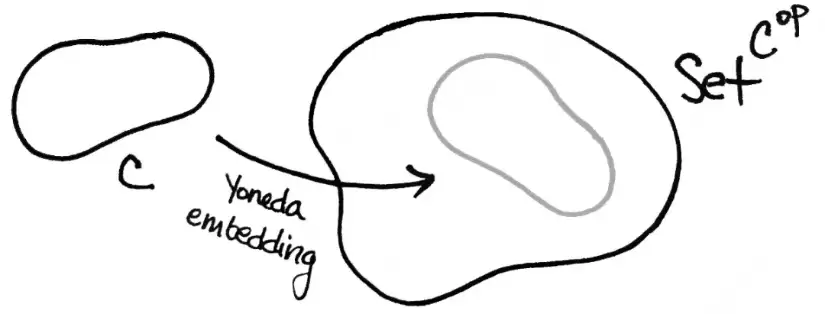
这个替代模型就像一台高倍显微镜,能够亦步亦趋地捕获针对每一个提示语的归因图。
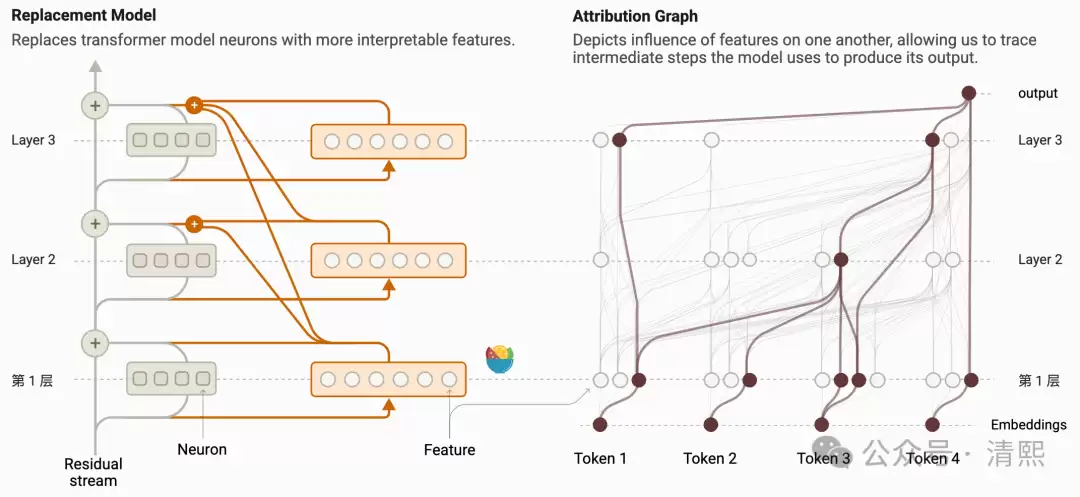
归因图描述的是,模型在某个特定输入提示下,生成目标词元输出时所经历的推理步骤。图中的边代表相邻节点之间的线性影响关系,节点包括激活的特征、输入提示中的词元嵌入、重构误差,以及输出逻辑值等。每个特征的活动强度,由它的输入边的权重之和来决定。
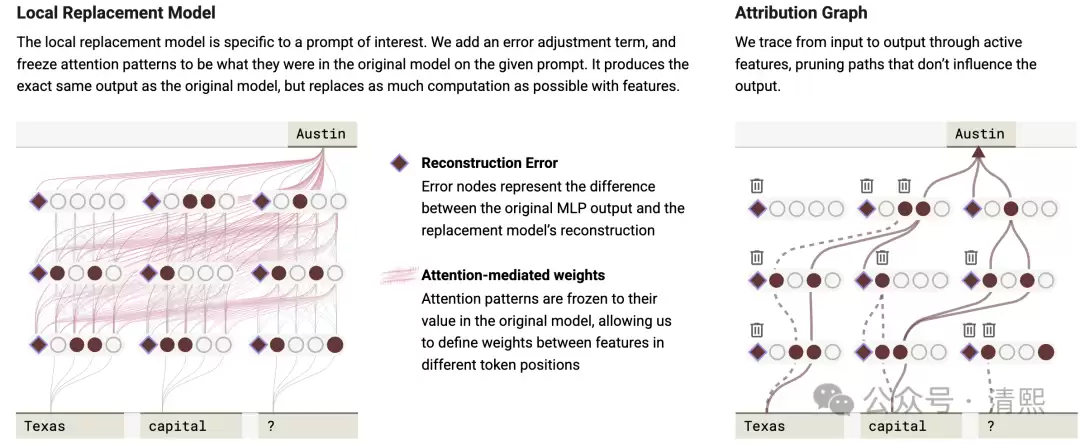
换句话说,归因图可以直观展示,在某个具体输入下,特征之间如何相互作用才产生了最终的输出。但更值得关注的,是特征在所有上下文环境中交互的全局图景——这个全局交互由模型权重决定。相邻层神经元之间的直接影响,就是它们之间的连接权重;如果神经元跨越了多个层,影响会通过中间层一步步传递。
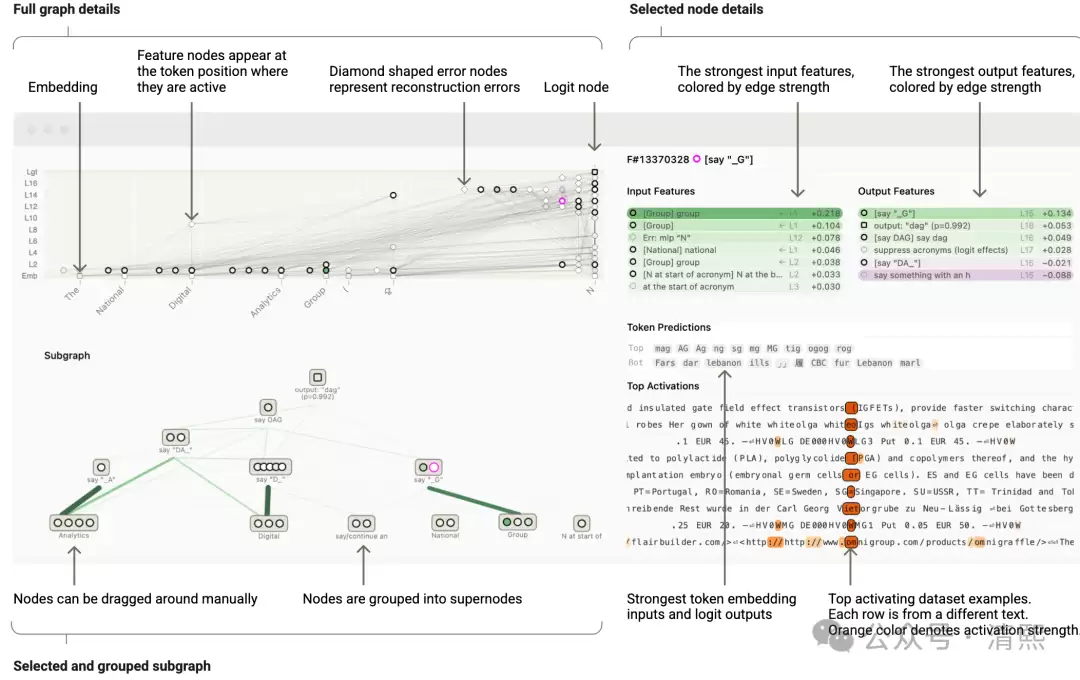
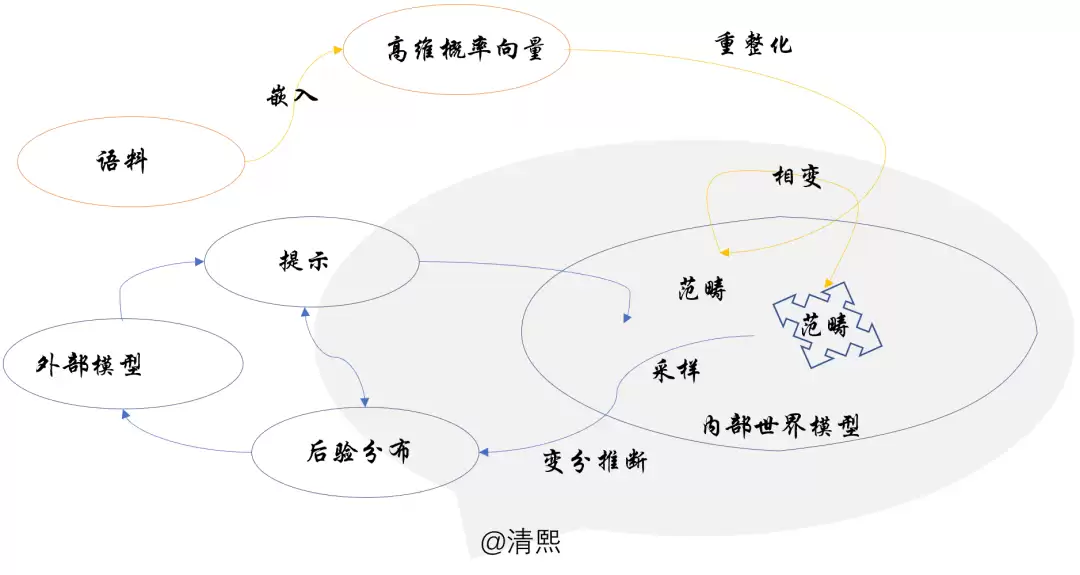
这本质上是此前在讨论“降低大模型幻觉的必由之路”时就提到过的——Transformer 视角下的范畴中采样,即在复杂高维的对象米田嵌入图中的采样路径。
接着,研究团队在第二篇报告中,把这台“AI 显微镜”对准了自家的 Claud 3.5 Haiku,做了一次“生物学”式的内部机制探查,结果非常有趣。有两个场景尤其值得拿出来细聊。
诗歌中的规划
研究显示,大模型在写诗行时,并不是简单地把下一个词预测出来就完事。它会提前做规划:在开始写每一行之前,模型就识别出可能出现在行末尾的押韵单词,然后预先选择好押韵选项,再决定整行的构建方式。
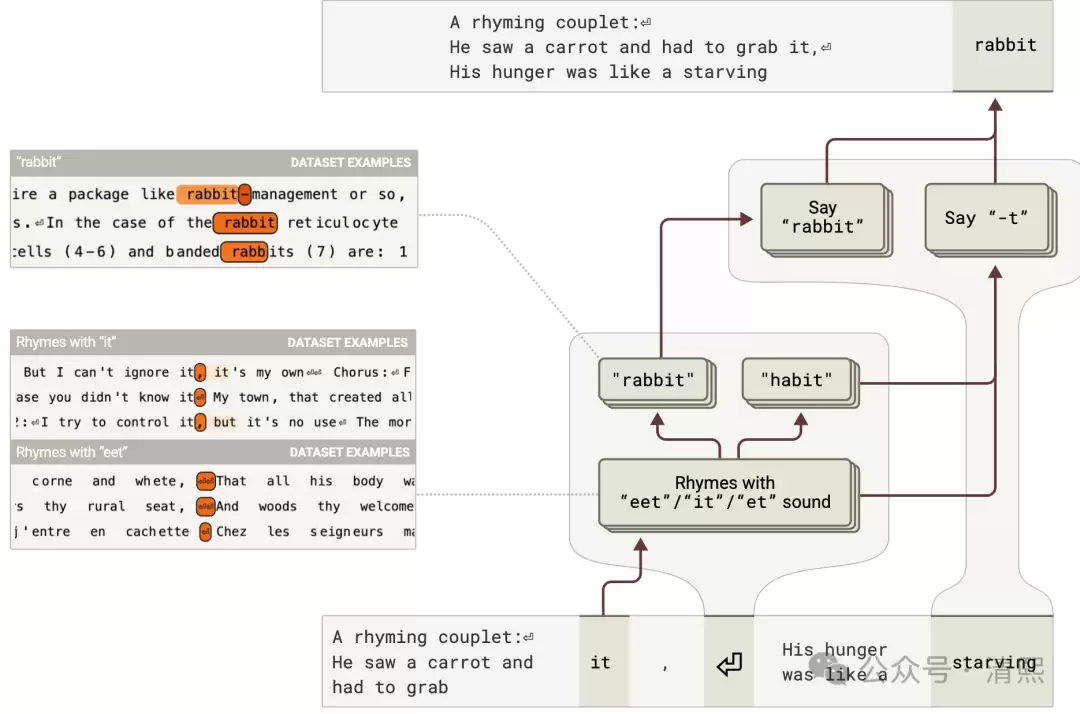
这就彻底碘伏了行业里一个流行的错误认知——总以为大模型只是在做下一个词元预测。它确实是这么学习语料的,但推理生成时,远不止这么简单。诗词韵律规划更接近于以前在描述大模型数理原理时提到的采样过程:在外部感官输入(也就是被提示置于某种上下文)下,大模型内部会限定在相应的高维语言概率空间的子空间内推理;推理就是在这个子空间里采样,可以类比为跨范畴采样。采样不断进行,基于内部通过预训练获得的世界模型(也就是先验),针对感官输入做变分推断,最小化自由能,从而获取最佳采样分布 q*,作为对导致感官输入的外部后验的预测。
多语言电路
另一个有趣的发现是多语言电路。研究发现,大模型混合使用了两种电路:一种是“特定于语言”的,另一种是“抽象的、独立于语言”的。而且,更大的模型中,“抽象的、独立于语言”的成分会越来越突出。
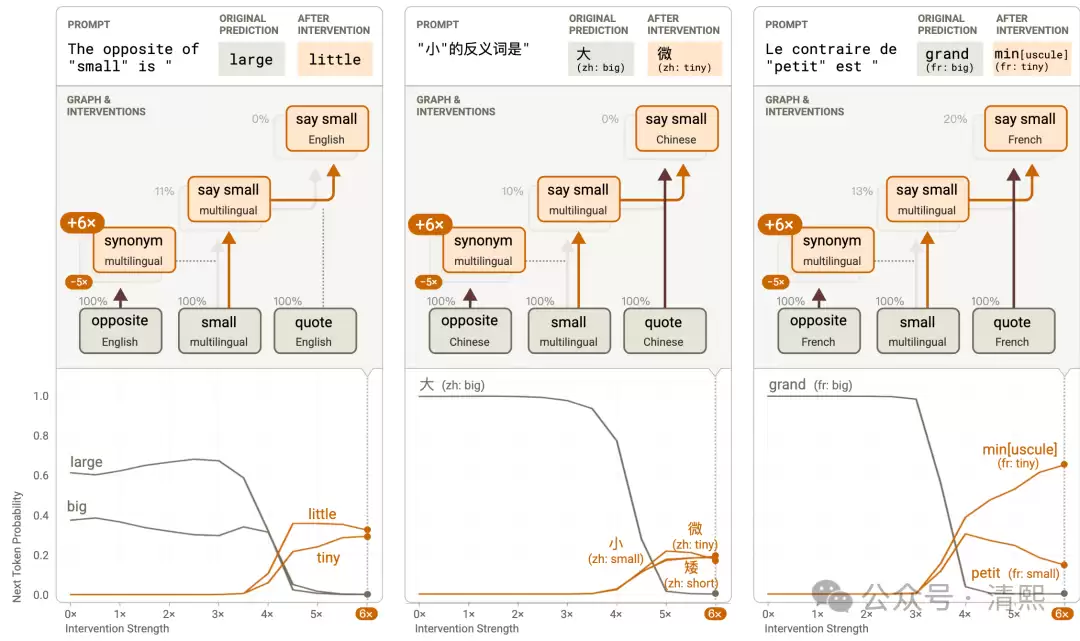
这个发现与之前对 DeepSeek R1 & R2 技术原理的分析不谋而合——大模型的语言处理机制在不同层次/尺度上有着清晰的分工。人类与大模型的语言体系中,实际上具有共通的三层结构:
- 自下而上,首先是基础“信息概率分布”处理体系;
- 之上是自然语言层,比如语音、词句;
- 最上层是符号语言,比如代码、数学公式。
推理说到底,不过是在大模型构建的高维概率语言空间里,对信息概率分布做采样的变分过程。这个过程可以映射到不同的上层自然语言,以及对应的语音,甚至进一步映射到某种符号语言——代码或数学公式。而抽象的符号语言也可以用自然语言反过来描述,从而进一步转换为对信息概率分布的处理过程。
Anthropic 团队对大模型内部机制的探索,正在不断逼向模型本质的机理。这与目前来自 Nature、Science,以及学术界和企业界几十项研究成果一样,都指向了同一个数理认知框架。方向越来越清晰了。