谷歌云与 NVIDIA 携手合作后,Dataflow 迎来了一项关键更新:将 GPU 引入大数据处理领域。这究竟意味着什么?简而言之,数据流用户如今可以在机器学习推理工作流中,直接调用 NVIDIA GPU 的强大计算能力。接下来,我们以 BERT 模型为例,看看这种组合能带来多大的性能提升。
Google Cloud 的 Dataflow 本身是一项托管服务,专用于处理多种数据处理模式,包括流式分析和批处理分析。此次新增的 GPU 支持,相当于为数据流管道装上了一颗“加速引擎”,特别适合在管道上运行的机器学习推理任务。
接下来,我们将逐步展示如何通过部署一个微调后的 BERT 模型(针对“问答”任务),实测 NVIDIA GPU 加速带来的性能提升和总拥有成本(TCO)优化。我们将依次演示:在 Dataflow 上用 CPU 执行 TensorFlow 推理、将同样的代码迁移到 GPU 上运行、最后再借助 NVIDIA TensorRT 对模型进行转换和部署,看看能快到何种程度。
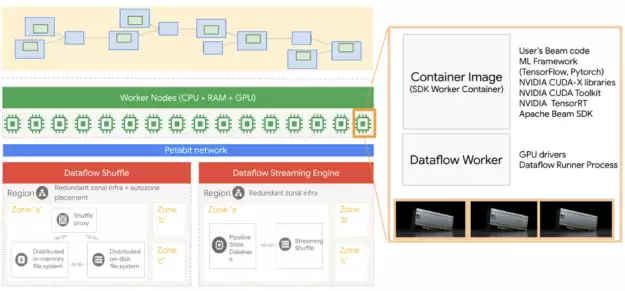
图1:Dataflow 架构与 GPU 运行时环境。
整个过程分为几个步骤,我们先从搭建本地环境开始。
搭建实验环境
建议为 Python 创建一个虚拟环境,这里使用 virtualenv 来实现:
virtualenv -p
使用 Dataflow 时,需要确保开发环境中的 Python 版本与 Dataflow 运行时版本保持一致。更具体地说,在运行数据流管道时,最好使用相同的 Python 版本和 Apache Beam SDK 版本,否则容易遇到兼容性问题。
激活虚拟环境:
source /bin/activate
有一点需要特别注意:激活前请确认自己不在另一个虚拟环境里,否则会引发各种不可预知的错误。
环境激活后,就可以安装所需软件包了。即使作业最终在 Dataflow 上运行,本地也需要安装一些包,这样在本地跑代码时 Python 才不会报错。
pip install apache-beam[gcp]
pip install TensorFlow==2.3.1
你可以尝试 TensorFlow 的不同版本,但关键是让本地版本与数据流环境保持一致。apache-beam 及其 Google Cloud 组件也是必需的。
获取微调的 BERT 模型
NVIDIA NGC 上资源丰富,从 GPU 优化的容器到微调好的模型应有尽有。这次我们使用了几个 NGC 上的现成资源。
第一个资源是 BERT 大型模型,针对 SquadV2 问答任务做了微调,包含 3.4 亿个参数。使用以下命令即可下载:
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_sa vedmodel_large_qa_squad2_amp_384/versions/19.03.0/zip -O bert_tf_sa vedmodel_large_qa_squad2_amp_384_19.03.0.zip
这个 BERT 模型在训练时使用了自动混合精度(AMP),序列长度为 384。
此外还需要一个词汇表文件,可以从 BERT 检查点获取,通过以下命令从 NGC 下载:
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad2_amp_128/versions/19.03.1/zip -O bert_tf_ckpt_large_qa_squad2_amp_128_19.03.1.zip
下载完成后,解压缩并放到工作文件夹中。后面我们会用到自定义 Docker 容器,这些模型会被打包进镜像里。
自定义 Dockerfile
我们使用一个基于 NGC TensorFlow 容器派生的自定义 Dockerfile。NGC 的 TensorFlow 容器是加速 TF 模型的最佳起点。
在此基础上再加几个步骤,把模型和文件复制进去。下面是 Dockerfile 的片段:
FROM nvcr.io/nvidia/tensorflow:20.11-tf2-py3
RUN pip install --no-cache-dir apache-beam[gcp]==2.26.0 ipython pytest pandas && \
mkdir -p /workspace/tf_beam
COPY --from=apache/beam_python3.6_sdk:2.26.0 /opt/apache/beam /opt/apache/beam
ADD . /workspace/tf_beam
WORKDIR /workspace/tf_beam
ENTRYPOINT [ "/opt/apache/beam/boot" ]
接下来的步骤是构建 Docker 镜像并推送到 Google 容器注册中心(GCR):
project_id=""
docker build . -t "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
docker push "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
也可以直接使用我们提供的脚本,执行 bash build_and_push.sh 即可。
运行作业
认证好 Google 账号后,直接调用 run_gpu.sh 和 run_gpu.sh 脚本就能运行我们提供的 Python 文件。
数据流中的 CPU TensorFlow 推理(TF-CPU)
仓库中的 bert_squad2_qa_cpu.py 文件用于根据文本文档回答问题。批量大小设为 16,意味着每次推理调用回答 16 个问题,总共 16000 个问题(1000 批)。当然,BERT 也可以针对其他任务进行微调。
在 Dataflow 上运行作业时,默认会基于实时 CPU 使用率自动缩放。如果想禁用这个功能,需要把 autoscaling_algorithm 设置为 NONE,这样就能指定整个工作周期中使用多少 worker。或者,通过设置 max_num_workers 参数,让 Dataflow 自动缩放但限制最大 worker 数。
建议给作业设置一个名称,而不是使用自动生成的,这样通过 job_name 参数可以更好地跟踪。作业名称会作为运行作业的计算实例的前缀。
用 GPU 加速(TF-GPU)
要在 GPU 支持下执行同样的 TensorFlow 推理作业,需要设置以下参数:
--experiment "worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver"
这个参数能让一个 CUDA T4 张量核连接到 Dataflow worker VM,在 Compute VM 实例上也能看到。Dataflow 会自动安装所需的 NVIDIA 11 驱动。
bert_squad2_qa_gpu.py 文件和 bert_squad2_qa_cpu.py 几乎一模一样。这意味着几乎不需要改动,就能用 NVIDIA GPU 跑起来。当然,我们也加了一些额外的 GPU 设置,比如使用下面的代码设置内存增长:
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
NVIDIA 优化库的推理
NVIDIA TensorRT 能优化深度学习模型的推理,提供低延迟和高吞吐量。这里我们先用 TensorRT 优化 BERT 模型,然后在 Dataflow 管道上用 GPU 做快速问答。用户可以参考 TensorRT 演示 BERT GitHub 仓库。
我们还用到了 Polygraphy——它是 TensorRT 的高级 Python API,用于加载 TensorRT 引擎文件并运行推理。在数据流代码中,TensorRT 模型被封装为一个共享工具类,这样数据流工作进程的所有线程都能使用它。
比较 CPU 和 GPU 运行效果
下表展示了示例运行的总运行时间和资源消耗。Dataflow 作业的最终成本是总 vCPU 时间、总内存时间和总硬盘使用量的线性组合。GPU 场景下还多了一个 GPU 组件。
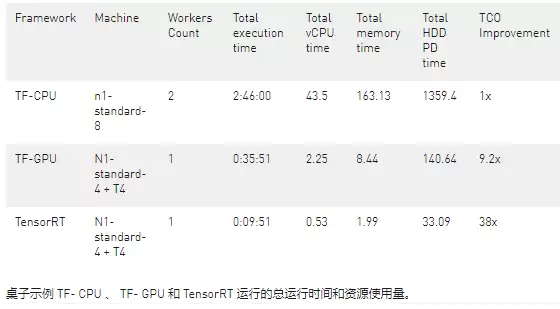
上表基于单次运行,具体数值可能有波动,但根据我们的实验,比率变化不大。
当使用 NVIDIA GPU(TF-GPU)加速模型时,与 CPU(TF-CPU)相比,总节省(包括成本和时间)超过 10 倍。换句话说,用 NVIDIA GPU 推理这个任务,不仅跑得更快,成本也更低。
而用上 NVIDIA TensorRT 这样的优化推理库,用户甚至可以在 Dataflow 的 GPU 上运行更复杂、更大的模型。TensorRT 进一步加速了同一个作业——比使用 TF-GPU 快 3.6 倍,成本节省 4.2 倍。和 TF-CPU 相比,执行时间减少了 17 倍,费用减少了 38 倍。这才是关键所在。
总结
在这篇文章中,我们比较了 TF-CPU、TF-GPU 和 TensorRT 在 Google Cloud Dataflow 上运行问答任务的推理性能。结论非常明确:Dataflow 用户通过利用 GPU worker 和 NVIDIA 优化库,能够获得巨大的收益。
使用 NVIDIA GPU 和软件加速深度学习模型推理其实非常简单。只需要添加或改动两行代码,就能用 TF-GPU 或 TensorRT 运行模型。我们提供了相关的脚本和源文件供参考。