在企业知识管理、法律文书分析及学术研究等专业领域,多格式文档的解析障碍、检索准确率的瓶颈以及AI问答固有的“幻觉”风险,是普遍面临的三大核心挑战。RAGFlow作为一款基于深度文档理解的开源RAG引擎,通过与LLM高效结合,提供带精准引用的智能问答能力。该工具支持20+文档格式解析,融合智能分块策略与混合检索方案,辅以可视化干预界面和灵活的Docker部署方案,堪称搭建企业级知识库的一把利器。
为什么你需要这个神器?
从实际痛点出发。日常工作中,合同、论文、报表等文档格式五花八门,传统检索方式常遗漏关键信息,而AI问答又容易产生缺乏依据的“幻觉”。RAGFlow的核心逻辑很简单:让大模型真正理解文档内容,而非盲目猜测。
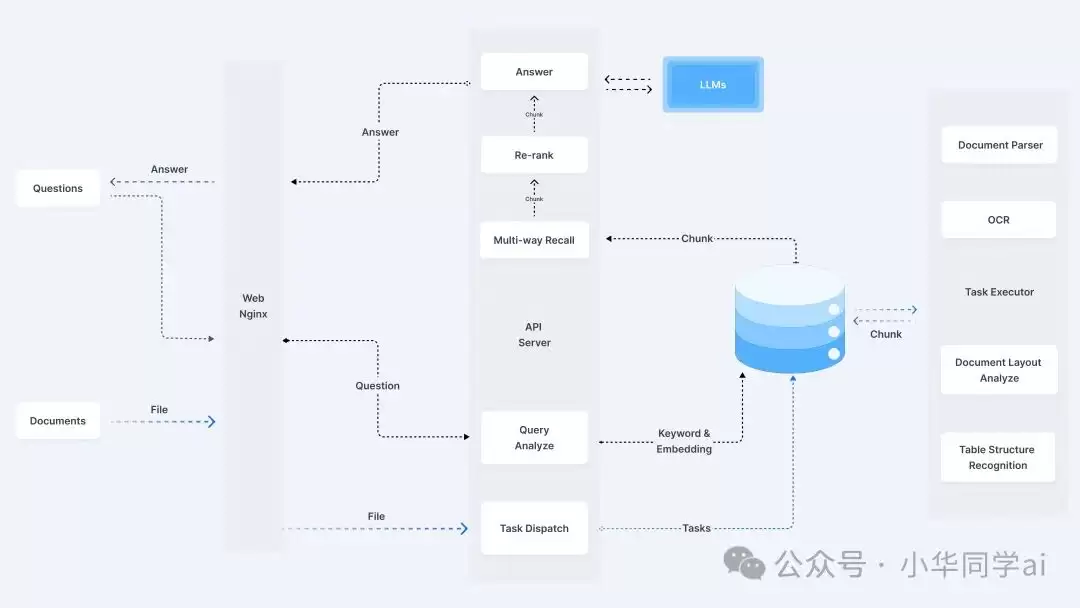
五大核心功能亮见
深度文档理解
它能解析的格式覆盖PDF、DOCX、PPT、XLSX、JPG等20多种常见类型。真正厉害之处在于解析细度——表格数据可结构化提取,数学公式保留LaTeX格式,图片支持OCR文字识别,多栏排版还能智能重组。简单来说,文档怎么排版,它就能怎么理解。
智能分块策略
分块并非简单切词,而是基于布局分析。以下配置示例可以直观感受:
# 分块配置示例(yaml格式)
chunk:
splitter: "smart"
max_length: 512
overlap: 64
image_caption: true
混合检索方案
单一检索方式总有缺陷,RAGFlow采用“组合拳”——语义检索(Embedding模型)负责捕捉含义,关键词检索(BM25算法)负责精准匹配,最终多路召回结果融合排序,大幅提升了检索准确率。
灵活部署方案
部署门槛不高,一条命令即可启动:
# 一键启动命令
docker compose -f docker/docker-compose.yml up -d
支持CPU和GPU环境,最低配置要求为4核CPU加16GB内存,大多数服务器都能满足。
技术架构解密
支撑这一切的核心组件如下:
| 组件 | 技术选型 | 核心作用 |
|---|---|---|
| 文档解析引擎 | Apache Tika+自定义解析器 | 多格式文档内容提取 |
| 向量数据库 | Elasticsearch 8.x | 支持混合检索方案 |
| 对象存储 | MinIO | 原始文件存储管理 |
| 任务调度 | Celery | 分布式文档解析任务处理 |
| 前端框架 | React+Ant Design | 可视化操作界面 |
五大独特优势
与同类项目对比,差异更为明显:
| 对比维度 | RAGFlow | LangChain | LlamaIndex |
|---|---|---|---|
| 文档解析能力 | ✅ 20+格式深度解析 | ⚠️ 基础文本解析 | ⚠️ 基础文本解析 |
| 分块策略 | ✅ 智能布局分析 | ⚠️ 固定窗口分块 | ✅ 基础语义分块 |
| 检索方案 | ✅ 混合检索 | ✅ 向量检索 | ⚠️ 单一检索方式 |
| 可视化干预 | ✅ 完整干预流程 | ❌ 无 | ❌ 无 |
| 企业级特性 | ✅ 用户权限/审计日志 | ⚠️ 需二次开发 | ⚠️ 需二次开发 |
同类项目推荐
除了RAGFlow,市场上还有其他优秀选择值得关注:
- LangChain:适合需要高度定制化的开发者,提供灵活的工具链。
- LlamaIndex:专注数据连接器的轻量级解决方案。
- Haystack:工业级NLP管道框架,适合复杂业务场景。
- Milvus:专业向量数据库,适用于超大规模向量检索。
界面效果

总结
当大模型遇上深度文档解析,RAGFlow以结构化思维重新定义了知识管理——支持20余种格式智能解析、混合检索增强、可视化干预,企业级知识库的搭建因此变得像搭积木一样简单。