在构建企业级 RAG(检索增强生成)系统时,选择合适的数据存储方案是决定检索准确性与效率的关键。本教程将带你深入理解向量数据库、图数据库与知识图谱三者的优劣,并揭示混合架构的最佳实践,帮助你为智能问答系统奠定坚实基础。
向量数据库:高效但缺乏上下文
向量数据库将文档分割成小块(约100-200个字符),通过嵌入模型转化为向量存储。当用户提问时,系统会将问题转换为向量,然后使用KNN(K最近邻)或ANN(近似最近邻)算法找到最相似的内容。这种基于语义相似性的检索方式速度极快,适合大规模非结构化数据场景。
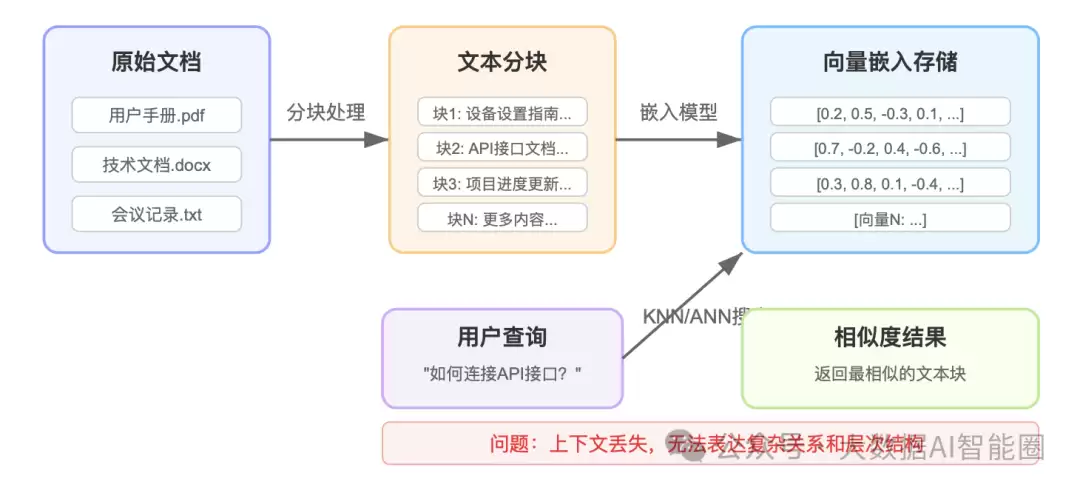
核心优势:
- 可以存储多种类型的数据(文本、图像等)
- 能够处理非结构化数据
- 支持语义相似性搜索,不局限于关键词匹配
关键问题:上下文丢失。
看一个简单案例:一份关于Apple公司的文档包含"Apple于1976年4月1日成立,由Steve Wozniak和Steve Jobs共同创办...Apple于1983年推出了Lisa,1984年推出了Macintosh..."
当用户询问"Apple什么时候推出第一台Macintosh?"时,向量数据库可能会因为分块和相似性搜索机制,错误地将"1983"和"Macintosh"联系起来,给出错误答案。这是因为分块截断了实体间的时序关系,导致数字被错位匹配。