数据集构建这件事,听起来好像就是从网上扒拉点数据、然后打个标签、洗一洗就完事了。但实际上,这里面门道很多——从开源数据获取到数据清洗、标注、增强,每一步都可能决定你最终模型的好坏。今天就把整个过程掰开揉碎了讲一遍,涉及干货和实操代码,希望能帮到正在为数据发愁的同学。
一、开源数据网站下载
做项目,找数据是第一关。几个主流的数据平台值得收藏:
- Kaggle: https://www.kaggle.com/
- ModelScope: https://modelscope.cn/datasets
- Hugging Face: https://huggingface.co
- 百度飞桨: https://aistudio.baidu.com/datasetoverview
这些平台涵盖了几乎所有领域的公开数据集,从图像、文本到音频、多模态,基本够用。
二、构建数据集(大致步骤说明)
1. 明确目标
- 定义问题: 确定你要解决什么问题或任务。比如你想构建医疗领域的数据集,那就得先搜相关医疗资料。有时候问题本身不够清晰,这时候就需要实际摸索一下,搞清楚本质上你需要什么。
- 确定数据类型: 文本、图像、音频?不同类型的数据,收集和处理的方式完全不同。
强调一点:太重要了,一定要关注你构建的数据集是否符合你要后训练模型的输入格式。很多同学辛辛苦苦搞完数据,结果喂给模型发现字段对不上,那就尴尬了。
2. 数据收集(这一步就是收集所有你能找到的相关数据)
- 内部数据: 从现有数据库、日志等获取(有条件的话)。
- 外部数据: 通过公开数据集、相关网站配合AI抽取等方式获取。
- 数据生成: 如果有必要,可以模拟或合成数据(非必须)。
3. 数据标注
- 手动标注: 人工打标签,精度高但成本高。
- 自动标注: 使用工具或预训练模型辅助标注,效率高但需要校验。
4. 数据清洗
- 处理缺失值:填充或删除缺失数据。
- 去重:删除重复数据。
- 格式统一:确保数据格式一致。
- 异常值处理:识别并处理异常值。
大批量数据处理时,推荐分三步走:
- 第一步: 依托传统大数据平台(如 Hive、HBase、Flink、MySQL 等),对数据进行初步清洗,剔除明显错误或异常的数据。
- 第二步: 借助人工智能技术,对数据中的错别字、语法错误、逻辑问题等进行智能修复,并结合标准数据集进行校准,提升数据质量与准确性。
- 第三步: 开展人工终审,通过随机抽查的方式,对经过前两级处理的数据进行最终审核,确保数据的完整性和可靠性。
5. 数据增强【非必须,视情况而定】
图像数据增强
(1) 旋转
细节:旋转角度通常在一定范围内随机选择,如±30°或±45°,以模拟不同视角的图像。
操作步骤:使用图像处理库(如OpenCV或Albumentations)对图像进行旋转操作。如果图像有标注框(如目标检测任务),标注框也需要同步旋转。
import albumentations as A
transform = A.RandomRotate90(p=0.5) # 随机旋转90度
augmented_image = transform(image=image)['image']
(2) 裁剪
细节:随机裁剪图像的一部分,裁剪区域可以是固定大小或随机大小。裁剪时需要注意保留关键信息。
操作步骤:使用随机裁剪函数,如Albumentations的RandomCrop。
transform = A.RandomCrop(width=400, height=400, p=0.3)
augmented_image = transform(image=image)['image']
(3) 其他增强
亮度调整:通过调整图像的亮度来模拟不同光照条件。
噪声添加:向图像添加随机噪声,增强模型的鲁棒性。
transform = A.Compose([
A.RandomBrightnessContrast(p=0.3),
A.GaussianBlur(blur_limit=3, p=0.2)
])
augmented_image = transform(image=image)['image']
文本数据增强
(1) 同义词替换
细节:在句子中随机选择一些词语,用它们的同义词替换。注意替换后的句子语义应保持一致。
操作步骤:使用词典或词嵌入模型(如Word2Vec)找到同义词并替换。
(2) 回译
细节:将文本翻译成一种语言,再翻译回原语言,可能会引入一些语义变化。说白了就是“英翻中,中翻英……无限套娃”。
操作步骤:使用机器翻译API(如Google Translate)进行翻译。
音频数据增强
(1) 变速
细节:调整音频的播放速度,但保持音调不变。
操作步骤:使用音频处理库(如librosa)对音频进行变速处理。
(2) 加噪声
细节:向音频中添加背景噪声,增强模型对噪声的鲁棒性。
操作步骤:从噪声库中选择噪声并叠加到音频上。
为什么添加噪声?
在数据集中添加噪声的主要目的是增强模型的鲁棒性。具体原因包括:
- 模拟真实场景:真实世界中的图像通常包含噪声(如传感器噪声、压缩噪声等),通过在训练数据中添加噪声,模型能够更好地适应实际应用中的噪声环境。
- 防止过拟合:噪声可以作为一种正则化手段,防止模型过度依赖训练数据中的特定特征,从而提高泛化能力。
- 数据增强:噪声添加是数据增强的一种方式,能够增加数据的多样性,帮助模型学习更广泛的特征。
判断是否需要增加噪声
不需要添加噪声数据集的情况
- 数据质量高且任务明确:如果原始数据集已经足够丰富、多样且高质量,能够很好地覆盖模型需要学习的模式和特征,那么通常不需要额外添加噪声数据。
- 模型过拟合风险低:当数据集规模较大、数据分布均匀且模型架构相对简单时,模型过拟合的风险较低,此时也不需要通过添加噪声数据来增强模型的泛化能力。
需要添加噪声数据集的情况
- 过拟合问题严重:当模型在训练集上表现优异,但在验证集或测试集上表现显著下降时,说明模型可能过拟合了训练数据中的噪声和特定模式。此时可以通过添加噪声数据来增强模型的鲁棒性。
- 特定任务需求:在一些特定的任务中,如图像生成或语音识别,添加噪声数据可以帮助模型学习到更复杂的模式和特征,从而提升模型在实际应用中的表现。
数据集构建中的注意事项
- 平衡噪声与原始数据: 在数据集中,噪声图像应与原始图像保持一定的比例,避免噪声数据过多导致模型过度依赖噪声特征。
- 多样性: 在添加噪声时,确保噪声类型和强度的多样性,以覆盖更多的实际场景。
- 验证集和测试集: 在验证集和测试集中也应包含适量的噪声数据,以评估模型在噪声环境下的表现。
- 数据增强的组合: 噪声添加可以与其他数据增强技术(如旋转、缩放、翻转等)结合使用,进一步提升模型的鲁棒性。
6. 数据划分
- 训练集:用于模型训练。
- 验证集:用于调参和模型选择。
- 测试集:用于最终评估。
三、具体示例(以DeepSeek-R1蒸馏模型为微调模型,构建的医学数据集为例)
1. 明确目标——医生文本类数据集构建
- 要让微调后的模型更擅长提供诊疗建议,为了增强可信度,它的语气最好更像一位医生。
- 确定数据类型是文本类,所以集中搜集医疗相关文本,如果能找到模拟医生对话的文本就更好了,在此基础上扩展加强。
- DeepSeek-R1蒸馏模型所需的数据格式是:Question-Complex-CoT-Response。所以在构建过程中,必须确保包含Complex-CoT部分。
2. 数据收集
1. 判断医学领域应该有很多前人已经构建过的数据集,先去开源网站ModelScope找找看。

2. 通过优质的开源数据集确认规范,后续构建过程中尽量往优质数据集的方向靠拢。
3. 各大公开网站的医学资料收集——这里收集的是中华医学期刊网等网站上公开的论文与指南(保存链接或下载)。
3. 数据标注
1.(1)利用数据标注辅助平台帮助构建数据集。将抽取的文件放入平台,构建基础QA问答对。
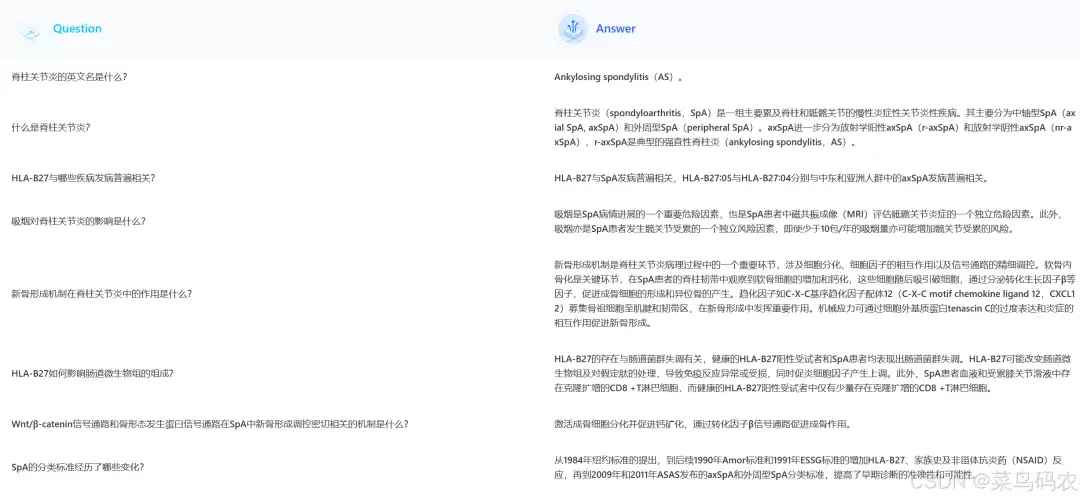
(2)将构建的问答对放入大模型AI,帮忙补全Complex_CoT部分。[问答对也可以是自己简单构思的问答,通过提示词让大模型达到想要的效果。]
[
{
"Question":"医生,我患有强直性脊柱炎(SpA),还伴有其他疾病,如果用生物制剂治疗,我需要注意些什么?",
"Complex-CoT":"对于伴有合并症的SpA患者,生物制剂的选择需要综合考虑患者的整体健康状况、合并症的种类和严重程度,以及生物制剂的潜在副作用。不同种类的生物制剂作用机制不同,可能对合并症产生不同的影响。因此,需要在专业医生的指导下,谨慎选择适合患者的生物制剂,并密切监测治疗过程中的反应。",
"Response":"针对伴有合并症的SpA患者,选用不同种类的生物制剂应慎重。我们需要综合评估你的整体健康状况,包括合并症的种类和严重程度,同时考虑生物制剂的潜在副作用。不同生物制剂的作用机制不同,可能会对合并症产生不同的影响。因此,在选择生物制剂时,我们会根据你的具体情况,权衡利弊,选择最适合你的治疗方案,并在治疗过程中密切监测你的反应。"
},
{
"Question":"医生,目前对于强直性脊柱炎(SpA)的研究进展如何?",
"Complex-CoT":"尽管目前在强直性脊柱炎(SpA)的研究中已经取得了一些成果,例如对疾病机制的初步了解、新的诊断方法和治疗方法的探索等,但仍然存在许多未解之谜。例如,SpA的发病机制尚未完全明确,部分患者对现有治疗的反应不佳,且疾病的长期预后仍需进一步研究。因此,SpA的研究仍在不断深入中。",
"Response":"尽管目前已有诸多研究成果,但SpA仍存在许多未解之谜。虽然我们在疾病机制、诊断方法和治疗手段上取得了一些进展,但仍然有许多问题需要进一步研究。例如,SpA的发病机制尚未完全明确,部分患者对现有治疗的反应不佳,且疾病的长期预后仍需深入探索。所以,SpA的研究仍在不断进行中,以期为患者提供更好的帮助。"
},
{
"Question":"医生,未来的研究应该如何开展,才能更好地提高强直性脊柱炎(SpA)患者的生活质量呢?",
"Complex-CoT":"未来的研究应该从多个方面入手,以提高SpA患者的生活质量。首先,探索新的生物标志物可以帮助我们更早、更准确地诊断疾病,实现个体化治疗。其次,开发新的药物和治疗方法可以为患者提供更多的选择,提高治疗效果。此外,新技术的应用可以优化治疗策略,减少治疗的副作用。通过这些综合措施,我们有望进一步改善SpA患者的生活质量。",
"Response":"未来的研究应继续探索新的生物标志物、新药物和新技术的应用,以进一步提高诊断的准确性、优化治疗策略,并最终改善SpA患者的生活质量。我们会从多个方面入手,包括寻找更准确的生物标志物来实现早期诊断和个体化治疗,开发更有效的药物和治疗方法,以及利用新技术优化治疗方案,减少副作用。通过这些努力,我们希望能够为SpA患者带来更好的生活质量。"
}
]
2. 同时也可以利用收集的链接,放进大模型AI让它构建数据集。
[
{
"Question":"医生,我是女性,最近感觉心脏不太舒服,有点胸闷,这是心脏病发作的迹象吗?",
"Complex-CoT":"女性心脏病发作的症状可能与男性不同,往往更不典型。除了胸闷,还可能伴有其他症状如呼吸急促、恶心、出汗等。在临床实践中,对于女性患者出现心脏相关症状,需要综合考虑多种因素,包括病史、体征以及辅助检查结果,以准确判断是否为心脏病发作,并及时采取相应的治疗措施。",
"Response":"女性心脏病发作的症状可能不太典型,除了胸闷,还可能有呼吸急促、恶心、出汗等。我们需要综合你的病史、体征以及辅助检查结果来判断是否为心脏病发作。如果有这些症状,建议尽快就医,我们会根据具体情况采取相应的治疗措施。"
},
{
"Question":"医生,我有哮喘,最近咳嗽得很厉害,是不是病情加重了?",
"Complex-CoT":"咳嗽是哮喘的常见症状之一,但咳嗽的严重程度并不一定直接反映哮喘的整体控制情况。在临床实践中,哮喘的评估需要综合考虑多个方面,包括症状频率、急性发作次数、肺功能检查结果等。对于咳嗽症状明显的患者,需要进一步评估是否存在其他诱因或合并症,并根据具体情况调整治疗方案。",
"Response":"哮喘患者咳嗽加重不一定意味着病情加重。我们需要综合评估你的症状频率、急性发作次数以及肺功能检查结果等。如果咳嗽很厉害,建议进一步检查,看看是否存在其他诱因或合并症,我们会根据具体情况调整治疗方案。"
},
{
"Question":"医生,我已经被诊断为哮喘,但感觉病情控制得不太好,我需要做哪些检查来全面评估我的病情呢?",
"Complex-CoT":"全面评估哮喘病情对于制定有效的治疗方案至关重要。通常需要进行肺功能检查,包括支气管激发试验和支气管舒张试验,以评估气道反应性和可逆性。此外,还需要评估患者的症状控制情况、急性发作频率、生活质量以及是否存在合并症等。通过这些综合评估,可以更准确地判断哮喘的控制水平,并调整治疗方案。",
"Response":"为了全面评估你的哮喘病情,我们需要进行一些检查,比如肺功能检查,包括支气管激发试验和支气管舒张试验,来评估气道反应性和可逆性。同时,我们还会评估你的症状控制情况、急性发作频率、生活质量以及是否存在合并症等。这些综合评估有助于我们更准确地判断病情,调整治疗方案。"
}
]
这里有个小技巧:构建数据集时,最好考虑模型来自哪家。比如通义千问系列的模型,用通义千问帮忙构建数据集会更有利于后续微调训练。
4. 数据清洗
主要是格式确认,确保数据格式一致。这次构建过程中,整体数据质量较高,所以清洗重点放在格式验证上。
import json
def validate_json_format(json_file_path):
"""
验证JSON文件是否符合指定格式。
参数:
json_file_path (str): JSON文件的路径。
返回:
bool: 如果符合格式返回True,否则返回False。
"""
try:
# 打开并加载JSON文件
with open(json_file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 验证数据是否为列表
if not isinstance(data, list):
print("JSON数据必须是一个列表。")
return False
# 验证每个条目
for item in data:
# 检查是否包含所有必需字段
required_fields = ["Question", "Complex-CoT", "Response"]
if not all(field in item for field in required_fields):
print(f"缺少字段:{required_fields}")
return False
# 检查字段值是否为字符串
for field in required_fields:
if not isinstance(item[field], str):
print(f"字段'{field}'的值必须是字符串。")
return False
print("JSON格式验证通过!")
return True
except json.JSONDecodeError:
print("JSON文件格式错误。")
return False
except FileNotFoundError:
print(f"文件未找到:{json_file_path}")
return False
except Exception as e:
print(f"发生错误:{e}")
return False
if __name__ == "__main__":
# 替换为你的JSON文件路径
json_file_path = "test.json"
validate_json_format(json_file_path)
这段代码专门用来判断json文件是否为["Question", "Complex-CoT", "Response"]的形式。
补充:测试数据集
在寻找优质数据集时,建议先抽取约1000条数据进行初步测试微调,评估效果是否符合需求。如果微调结果令人满意,再考虑将该数据集作为构建标准数据集的参考依据。
后续构建自己的额外数据集时,遵循循序渐进的原则:先构建少量数据并进行微调测试,观察效果。确认效果达标后,再继续扩充规模。
最后,将所有收集到的数据集整合在一起。进行混合微调之前,先用其中一部分数据试跑一遍。效果良好就继续,发现问题则需要缩小范围,仔细筛选可信数据,尽量避免脏数据对微调造成不良影响。
四、完结感言
感谢Deepseek官网满血版以及Kimi在代码修改、资料收集和文章润色方面提供的帮助。希望这篇内容能对大家在数据集构建上有所启发,少走弯路。