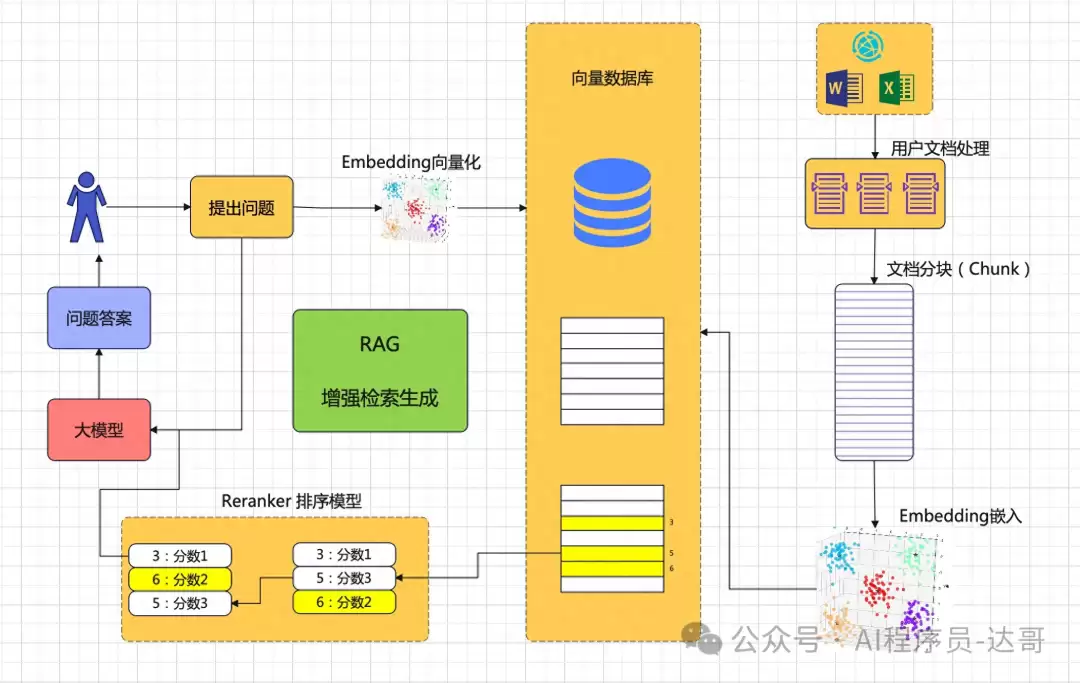
想要理解 Rerank 模型的工作原理,需要先了解 RAG(检索增强生成)的完整流程。RAG 系统通常分为两个阶段:第一阶段是“粗筛”,利用关键词匹配或向量相似度检索,从海量文档中快速筛选出数百甚至上千条候选结果;第二阶段是“精排”,依赖 Rerank 模型对候选结果进行二次打分与排序。简单来说,Rerank 就像一位“质检员”,负责把真正有用的内容排到最前面。
什么是 Rerank 模型?
Rerank 模型是一种专门用于搜索结果二次打分的机器学习模型。它并不从零开始检索文档,而是对已经初步检索到的候选文档进行更精细化的相关性评估,从而显著提升最终结果的准确性和语义匹配度。在实际应用中,Rerank 模型常与 Embedding 模型搭配使用,形成“粗筛+精排”的双重保障机制。
那么,Rerank 模型能解决什么问题?它主要弥补传统检索方式在语义理解深度上的不足。单纯依靠倒排索引或向量相似度,虽然能搜到相关内容,但未必是最相关的那一条。Rerank 通过多维度评估——包括语义一致性、上下文关联性、权威性等——对文档重新打分,确保高相关性内容优先展示。
其工作原理并不复杂:在训练阶段,模型基于大量“正确匹配”与“错误匹配”的查询-文档对,学习如何最大化正确对的分数、最小化错误对的分数;在推理阶段,输入查询和文档,直接输出匹配分数,然后按分数高低排序。
- 典型应用场景:在 RAG 系统中优化检索文档排序,提升大模型回答的准确性;在搜索引擎或推荐系统中精细化调整结果顺序,增强用户体验。
排序的关键维度
语义相关性
用户查询:"糖尿病患者的饮食禁忌有哪些?"
候选文档1:系统列举12种糖尿病饮食禁忌(相关度高)
候选文档2:讲解胰岛素注射方法(相关度低)
时效性权重
文档A:2023年《中国糖尿病防治指南》(权重+20%)
文档B:2010年某医院内部资料(权重-30%)
多样性控制
避免返回3篇都讲"糖分控制"的文章
保留1篇"运动管理"的补充内容
排序面临的挑战
长尾问题
用户查询:“如何训练导盲犬AI机器人?”
检索结果:
前10篇:通用机器人训练方法(未命中)
仅1篇:《基于多模态感知的导盲犬机器人训练指南》(命中但排名靠后)
解决策略:
- 数据增强:合成“导盲犬+机器人”的伪数据用于模型微调
- 混合检索:结合关键词(“导盲犬”+“AI”)与语义检索
- 主动学习:标注低置信度结果,迭代优化模型
语义鸿沟
用户查询:“手机发热严重怎么降温?”
检索结果:《移动设备SoC功耗管理与散热优化方案》(语义相关)
《智能手机电池保养技巧》(字面相关但非核心)
解决策略:
- 查询扩展:用 LLM 生成同义表述(如“发热”→“散热”、“降温”→“温度控制”)
- 上下文增强:提取文档中“发热”相关段落提升权重
- 用户反馈:记录用户最终点击的文档,反向优化模型
多语言混合
中文提问:“量子纠缠的实际应用有哪些?”
检索结果:
中文文档:《量子通信技术白皮书》(匹配度一般)
英文论文:《Quantum Entanglement in Commercial Systems》(Nature 2023,高相关)
解决策略:
- 实时翻译对齐:将英文论文摘要翻译后参与排序
- 跨语言模型:使用 mBERT 等模型直接计算中英文相似度
- 多语言标签:为文档添加语言/领域元数据辅助过滤
计算效率
数据规模:100万篇医疗文献库
查询需求:实时返回"阿尔茨海默症新药研发进展"Top5结果(<500ms)
解决策略:
- 两阶段排序:第一阶段用 BM25 快速筛选 1000 篇(耗时 50ms);第二阶段用 Reranker 精排 Top100(耗时 400ms)
- 模型蒸馏:将 BERT-large 蒸馏为 Tiny 版,速度提升 5 倍
- 硬件加速:使用 TensorRT 部署模型,GPU 推理吞吐量提升 10 倍
主流模型选型
| 模型 | 特点 | 性能优势 |
|---|---|---|
| BGE ReRanker | 支持多语言,适用于多语言场景 | 高精度需求、多语言场景 |
| Jina Reranker | 支持 8k 上下文长度 | 长文本排序、低延迟场景 |
| BCE-Reranker | 网易有道开源,中英跨语言优化 | 中英混合场景、高召回率需求 |
完整排序流程示例
用户问题:“美联储加息对 A 股的影响”
- 初步检索(Retriever):
返回50篇文档:
- 10篇关于美国货币政策
- 15篇A股市场分析
- 20篇历史加息案例
- 5篇无关内容
- Reranker 工作流:
for 文档 in 50篇:
计算语义相关性(BERT模型)→得分0.6-0.95
叠加时效性权重(2023年文档×1.2)
扣除低权威惩罚(自媒体文章×0.7)
最终得分=语义分×时效权重×权威系数
排序后Top3:
1.《2023年美联储政策与新兴市场联动分析》(0.94)
2.《跨境资本流动对A股的影响机制》(0.91)
3.《历史六轮加息周期中的板块表现》(0.89)
Reranker 本质
你可以将 Reranker 想象成知识库里的“智能质检员”。假设在图书馆找书,先用关键词检索到 100 本书,但真正需要的其实是最相关的 3 本。这时,图书管理员(Reranker)就会登场——他综合评估每本书的内容、出版时间、作者权威性等多维信息,帮你进行二次筛选,最终将最匹配的结果精准地推到最前面。这就是 Reranker 在 RAG 系统知识库检索流程中承担的关键优化任务。它通过对初步检索结果进行多维度智能分析,将长尾问题、语义鸿沟等传统检索难以克服的难题逐一拆解。