知识蒸馏技术中,真正让模型“开窍”的核心机制其实是软标签。它究竟如何有效提升模型的泛化能力?本文将从原理到实战,逐步解析这一关键过程。
核心内容:1. 知识蒸馏中软标签的运作机制与重要性2. 硬标签的局限性与软标签的优化方案3. 软标签在实际模型训练中的应用场景与效果
引言
上一篇文章已经系统梳理了知识蒸馏的基本原理——如何将大型模型的能力“压缩”迁移到小型模型。然而,真正实现这种能力高效传递的,正是软标签这一核心工具。今天我们将专门拆解软标签为何成为知识蒸馏的关键,以及它背后所解决的根本问题。
先看一个基础问题:为什么传统的硬标签不够用?软标签又是如何弥补这些不足的?
软标签:知识蒸馏的核心机制
软标签,本质上是指教师模型在输出层生成的完整概率分布,而不仅仅是针对“正确答案”的硬性判别。它体现了模型从“是不是”到“有多像”的认知转变——以猫的图片为例,硬标签只会给出“这是猫”的结果([1,0,0,0]),而软标签则能揭示教师模型内部的“暗知识”:该图像有60%概率是猫,20%像小型猞猁,15%像幼虎,5%属于其他类别。这些隐含的相似度关系,才是学生模型真正需要吸收的养分。
在传统机器学习中,硬标签自然是主流——一张猫照片,标签直接标注为[1,0,0,0],简单直接。但问题恰恰出在这里:
信息量严重不足:硬标签只关注最终结果,完全忽略模型对各个类别的置信度信息。
丢失细微判断:模型在决策过程中对不同类别的概率分布包含着丰富的相似性信息,硬标签直接舍弃了这些“中间推导过程”。
知识迁移效率低下:在蒸馏过程中,如果仅依赖硬标签,教师模型就像只交给学生一张考卷的“标准答案”,却没有传授推理步骤和思考方式。
举例来说,面对一张猫的照片,教师模型内部的判断链条可能是这样的:60%概率是猫,20%概率是小型猞猁,15%概率是幼虎,5%概率是其他动物——最终它选择了猫这个类别。但学生如果只看到“猫”这一结论,就无法捕捉到教师模型关于“猫与猞猁形态相似性”的关键洞察。
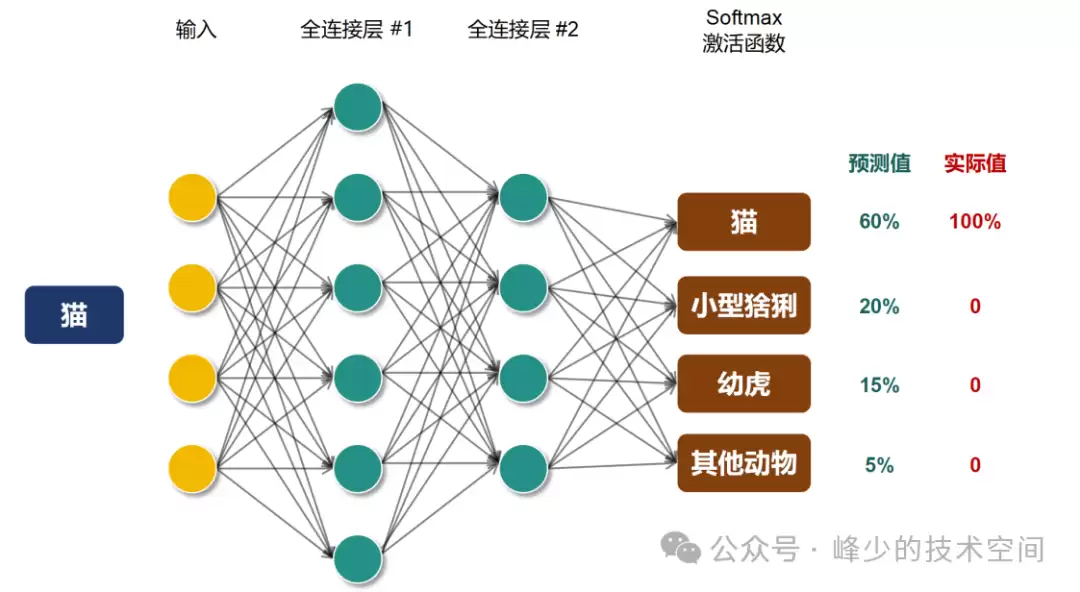
图像识别过程
软标签的实际应用
在知识蒸馏过程中,软标签保留了教师模型输出层的完整概率分布,使知识迁移更加全面:
硬标签仅告诉我们:"这是猫" [1,0,0,0]
软标签则传递完整信息:"60%可能是猫,20%可能是小型猞猁,15%可能是幼虎,5%可能是其他动物" [0.6, 0.2, 0.15, 0.05]
换句话说,如果只用硬标签训练,学生模型学到的只是表面答案,无法触及教师模型在识别过程中积累的丰富经验——“这张猫的图片为什么与猞猁相似”、“它有哪些特征让人联想到幼虎”。这种信息缺失,直接导致知识迁移变得肤浅且低效。
软标签的价值
软标签通过保留完整的概率分布,有效解决了知识迁移中的信息损失问题,具有以下关键价值:
传递暗知识:概率分布中蕴含的类别间相似度关系以及模型的不确定性,这些“暗知识”正是教师模型的核心资产。
提供更丰富的学习信号:学生模型从“是什么”升级到“有多像什么”,这种多维度的学习方式明显更为高效。
增强泛化能力:当模型真正理解“猫有点像猞猁,但不像狗”时,它在处理边界样本和未见场景时就会更加从容。
了解软标签的价值后,下一个现实问题就是:这些丰富的知识如何传递给学生模型?仅凭软标签还不够,还需要一套完整的训练框架来承载。接下来,我们具体看看学生模型在实际训练中是如何操作的。
学生模型的训练方法
学生模型的训练过程融合了多种学习目标,如下图所示:
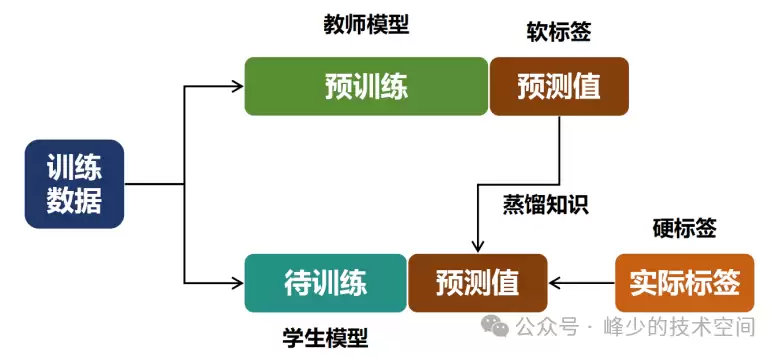
学生模型训练方法
双重输入源
在学生模型的输入端,同时接收两路信息:
训练数据:与普通模型一样,输入原始的训练样本(如图中的图像数据)。
蒸馏知识:来自教师模型输出层给出的“软标签”预测值。
双重学习目标
对应的,学生模型的训练目标也分为两部分:
硬标签学习:对真实标签进行准确分类,这部分采用标准的交叉熵损失函数来约束,确保模型的基本识别能力。
软标签学习:同时模仿教师模型输出的概率分布,使用KL散度等度量方法来衡量学生与教师分布之间的差异。这一步,学生实际上在学习“教师是如何思考的”。
总结
简而言之,软标签取代了传统的硬标签,将教师模型对所有类别的概率判断完整记录下来,而不仅仅是最终答案。这些概率中蕴藏的“暗知识”——类别间的相似性、模型的不确定性——才是学生模型真正需要的养分。
在知识蒸馏过程中,学生模型吸收了两种来源的信息:原始数据和教师模型的软标签。它需要完成一个双重任务:既要对真实标签准确作答,又要模仿教师的判断过程。正是这种双重约束,才带来了模型泛化能力的显著提升。更重要的是,这一切都发生在计算量大幅下降的前提下,使得复杂的AI模型得以部署在移动设备等资源受限的环境中。