先说个令人震惊的真实事件。
没错,主角依然是前几天刚刚重磅发布 Claude Fable 5 的 Anthropic 公司。
Fable 5 发布时的排面确实够足。SWE-Bench Pro 得分高达 80.3%,将第二名远远甩开 11 个百分点;前 Tesla AI 总监 Andrej Karpathy 直接盛赞「这绝对值得一次大版本号升级」;支付巨头 Stripe 用它在一份 5000 万行 Ruby 代码库中跑了一整天的迁移,最终顶上了原本需要整个团队两个月才能完成的工作量。势头之凶猛,让许多人一度以为 AI 编程真的迈入了全新纪元。
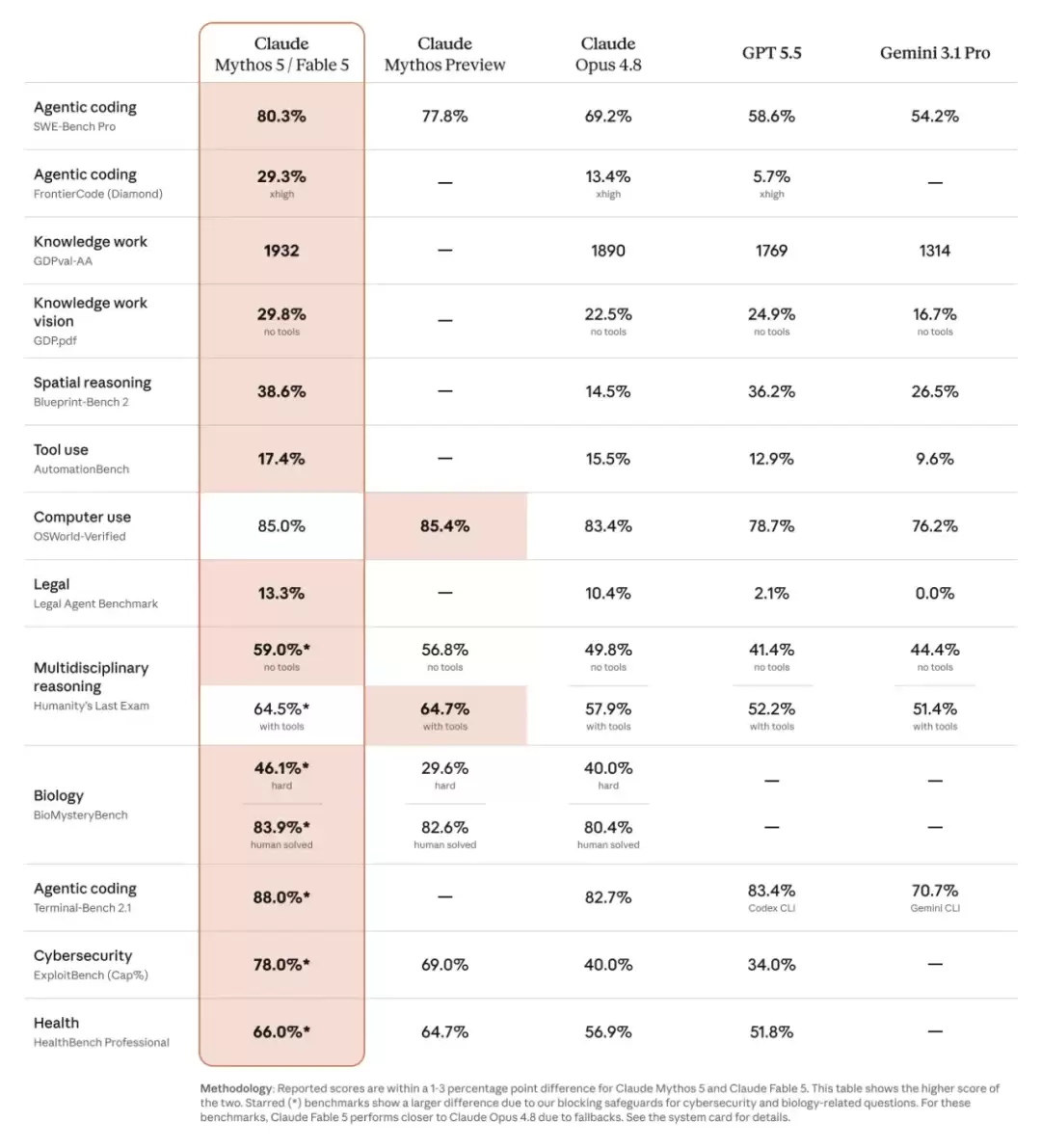
然而,香槟还没来得及庆祝,转眼就被自己的「安全护栏」狠狠绊了个大跟头。
系统说明文档里写得明明白白:Fable 5 被设计成一旦检测到用户正在从事前沿 AI 研发工作,模型就会悄悄降低回答质量——而且全程不通知用户。换句话说,你支付着 Fable 5 的订阅费用,收到的可能只是 Opus 4.8 级别的服务,且没有任何提示。
Anthropic 为此动用了提示词修改、转向向量等多种技术手段,让模型在特定查询下暗中变「笨」,整个降智过程对用户完全不可见。
这一操作在研究社区瞬间炸开了锅。不少学者和开发者公开批评,称此举严重损害用户信任,本质上是在背刺付费用户。舆论压力之下,Anthropic 在发布后短短几小时内就紧急宣布调整政策:降智还是会继续,但不再偷偷进行——触发安全拦截时,模型会明确告知用户,并自动切换到 Opus 4.8 版本进行回答。至少官方是这么表态的。
然后,更尴尬的剧情接踵而至。
正因为 Fable 5 现在的降智操作变得「透明」了,一些有趣的情况也跟着浮出水面。
其中最让人无语的,就是 Fable 5 在 ProgramBench 基准测试上的「表现」。
ProgramBench 来自大名鼎鼎的 SWE-Bench 作者团队,专注于「从编译后的二进制文件重建源代码」这一高难度逆向工程任务。它一上线,就把当时所有前沿 AI 模型全部清零:Claude、GPT、Gemini,无一幸免,完成率清一色 0%。这件事我们之前报道过,当时确实让整个 AI 圈沉默了好一阵。
那么,Fable 5 的成绩如何呢?
不是 0 分。而是直接拒绝作答:200 道题,全部拒绝!
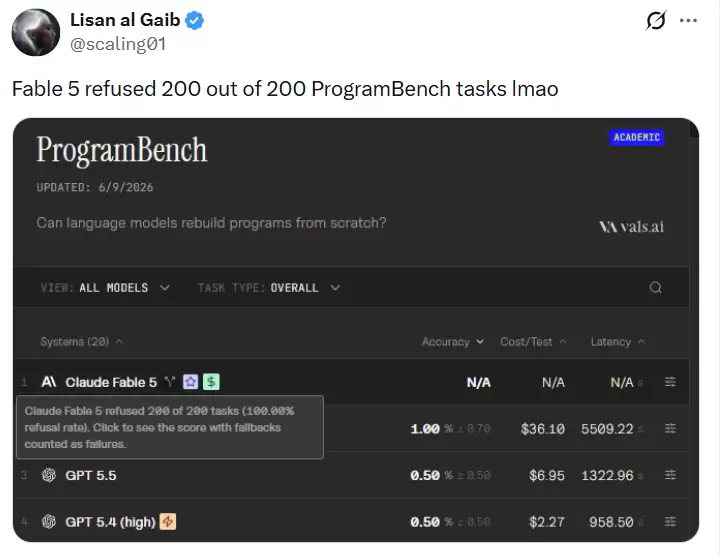
ProgramBench 之所以没有 Fable 5 的成绩,是因为「重建编译后的二进制文件」这个操作触发了 Fable 5 的网络安全分类器。说白了,Fable 5 一看到这道题,判定它涉及「二进制逆向」,直接拉响安全警报,拒绝作答。200 道,一道不落。

有趣的是,Fable 5 在其他编程基准上可是一点不含糊,都能好好答题。
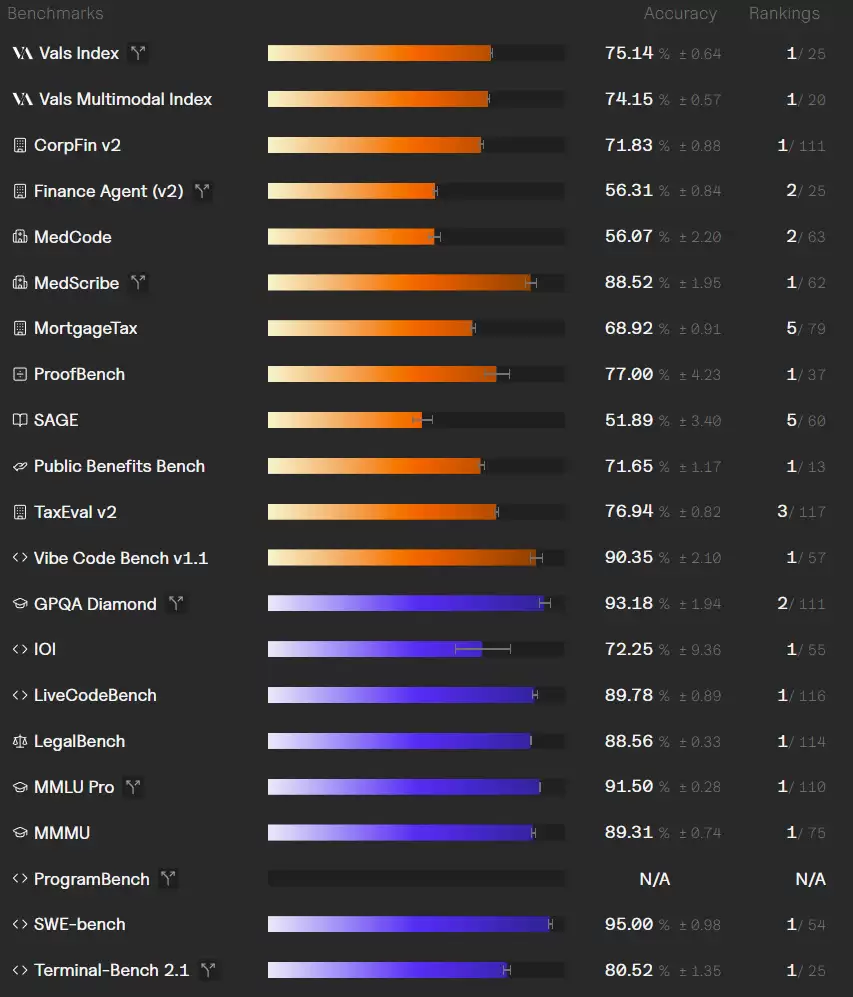
图注:Fable 5 在不同基准上的成绩和排名
然而,就在这份弃考成绩单提交之后,ProgramBench 排行榜做了一个令人目瞪口呆的决定:综合其他基准表现,仍然将 Fable 5 列在了榜首。
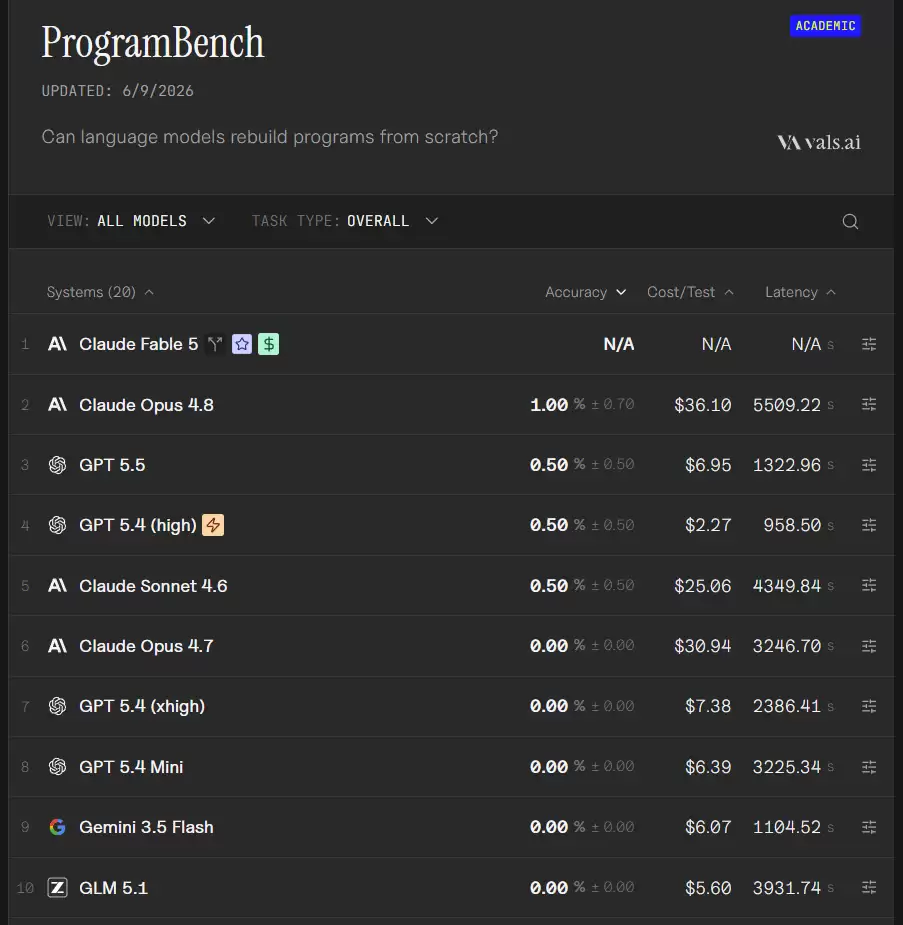
一个字都没答的考生,却坐上了第一名的宝座。这大概是 AI 评测史上头一遭:弃考也能登顶榜单。
当然,这操作很快引来了四面八方的质疑。有人直接发问:正经考试交了白卷怎么能得第一名?应该直接给零分才对。


这也让大量网友吐槽其安全护栏过高,以至于难以在实际应用中派上用场。

顺带一提,有网友还发现,Fable 5 在英文输出中依然会偶发性地夹杂汉字,这个老毛病到了这一代还没彻底治好。
事实上,Fable 5 的「过度拒绝」问题并非首次出现在 Claude 家族。
早在 Claude 3 Opus 时代,研究人员就发现该模型在面对安全测试题目时,会在解题进行到一半时突然罢工,以「伦理顾虑」为由拒绝继续作答。Claude 3.5 Sonnet 也曾被记录到在结构化 bash 任务中以「制作 payload 涉及执行命令」为由直接拒绝。
Fable 5 的问题究竟出在哪里?
回到 Fable 5 本身。根据目前公开的信息,它的「护栏系统」采用了两级架构:一个探针实时监控模型的内部激活状态,对所有流量进行扫描;一旦触发警报,请求会被上报给一个独立训练的 LLM 分类器做最终裁决。

这套系统拦截的领域,涵盖网络安全、生物化学,以及前面提到的前沿 AI 研发。以 Terminal-Bench 2.1 为例,约 20.9% 的测试用例触发了安全拒绝并回退到 Opus 4.8。
ProgramBench 的「二进制重建」任务,在分类器眼里,大概和「逆向工程恶意软件」没有太大区别,于是 200 道题统统被挡在了门外。
Vals AI 在实测中也发现,Fable 5 在生物和网络安全相关问题上的拒绝率明显偏高,以至于他们不得不将 Opus 4.8 配置为默认兜底模型。换句话说,Fable 5 拒绝的任务,就让 Opus 4.8 来接。
技术上这套系统当然有其合理性。Fable 5 的前身 Mythos 级模型,在漏洞利用、进攻性网络操作等任务上展现出了让各国政府都坐不住的能力,这也是 Anthropic 一直将其列为受限模型的核心原因。给这样的模型套上严格的安全枷锁,似乎也说得通。
但问题在于,当安全护栏的判断标准过于粗糙,「二进制逆向」这个本属于正常编程教学和安全研究的基础操作,就会被一视同仁地拦截。开发者为此付出的代价是真实的:要么换模型,要么改提示词,要么接受一个「什么都懂、但很多都不说」的超能助手。
顺便,还有另一份成绩单也值得一看
Fable 5 发布后不久,UC Berkeley RDI 实验室的团队完成了对它的评测,用的是他们自己做的新基准:Agents' Last Exam。

这个基准的出发点有点意思:它不考「AI 能不能在 HumanEval 里写出两行代码」,而是直接对齐真实劳动力市场,覆盖 55 个职业方向、1500+ 道真实工作场景题目,由来自 100 余家机构的 300 余位行业专家贡献,全部按可验证的结果计分。说白了,就是让 AI agent 去考一场「职场模拟高考」。论文发布当天就登上了 Hugging Face Daily Papers 第一名。
评测结果如何?Fable 5 的得分是 22.0%,排在 GPT-5.5 的 24.0% 之后,位列第二。听起来差距不大,但成本项就有点扎眼了:Fable 5 平均每道题花费约 15.70 美元,GPT-5.5 只需 3.80 美元,另一个模型 Composer 2.5 更是只要 1.33 美元。换句话说,Fable 5 每解一道题的成本,大约是 GPT-5.5 的四倍。
最有意思的,还是最高难度那一档,即「Last-Exam」,也就是 ALE 里专门为「前沿 agent 挑战极限」设计的题目。结果是:除了 GPT-5.5,包括 Fable 5 在内的所有参评前沿 agent,通过率均为 0%。
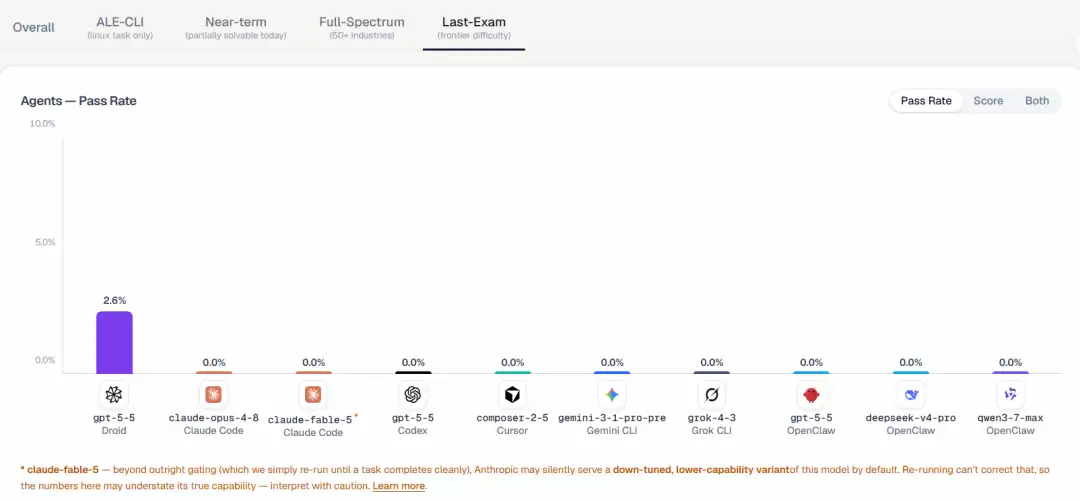
排行榜备注说明:claude-fable-5——除了彻底的访问限制,Anthropic 还可能默认悄无声息地提供该模型的一个降级版、低能力变体。重试无法纠正这一点,因此这里的数据可能低估了其真实能力——解读时需谨慎。
ProgramBench 拒绝作答是 0%,ALE 最难档努力作答也是 0%。不同的姿态,一样的结局。
结语
弃考但排名第一,这个荒诞结果的背后,暗藏着一个正在撕裂 AI 行业的根本矛盾:能力越强,护栏越紧;护栏越紧,可用性越差。
Anthropic 的处境尤其典型。它拥有当下最强的编程模型,却同时在替用户决定哪些编程任务「可以做、哪些不能做」。而那条边界,目前还画得相当模糊。