自动驾驶世界模型的目标早就不只是预测下一帧画面了。说白了,你现在得让它能理解场景——场景里有什么目标、目标在哪儿、不同视角下空间结构怎么变——这些才是真正需要解决的问题。光会生成外观上合理的未来图像,却答不出场景里有什么东西、东西具体在什么位置?那只能说它还没有真正建立起对三维驾驶环境的显式建模能力。
GaussianDWM 瞄准的,就是这个关键缺口:在统一的 3D 场景表示里,同时把场景理解和生成任务都搞定。

GaussianDWM 的想法很直接:把场景理解和空间生成、时间生成、RGB-D 生成全部塞进同一个框架。核心手段是用 3D Gaussian 场景表示作为世界模型的中间层,让同一个 3D 表示既能承载几何和外观,也兼容语言语义。
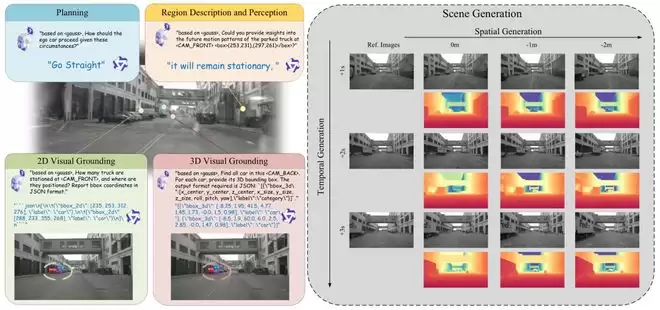
面向场景理解的自动驾驶世界模型
过去几年,关于 Driving World Model 的讨论基本上都围着生成能力打转。一个典型套路是:给你当前或历史的观测,模型要能预测未来的驾驶场景,或者在车辆变换位姿时合成新视角。这种能力对仿真、数据生成和闭环评测确实很有用,但它并没有覆盖自动驾驶系统真正需要面对的全部问题。
在真实的驾驶场景里,模型还得回答更结构化的问题。比如,场景里有没有某个被语言描述的目标?目标在图像或 3D 空间里到底在哪儿?当前的驾驶环境能不能支持后续的规划?这类问题要求模型不止是提取视觉特征生成画面,还得把外观、几何和语义组织成一种语言模型能直接读取和利用的场景表示。
这也正是 GaussianDWM 的出发点。现有的统一框架中,有些依赖 BEV 或 depth 特征做 feature-level 对齐,但这种对齐更多发生在中间特征层,模型未必真正拥有一个统一的 3D 场景表征。GaussianDWM 选择用 3D Gaussians 作为场景的底座,目的就是让同一组表示既能输入 LLM 做理解,也能作为条件送给生成模块。
把 3D Gaussian 变成 LLM 能读懂的世界表示
GaussianDWM 的整体框架可以分成三块:World Tokenizer、Scene Understanding 和 Multi-modal Generation。这三个模块不是简单的串联关系,而是围绕同一个 3D Gaussian 表示展开的:先把多视角图像组织成带语言语义的高斯场,再把这些高斯压缩、采样并投影到 LLM 的 embedding space,最后用 LLM 提取出的 world knowledge 来指导 RGB-D 生成。
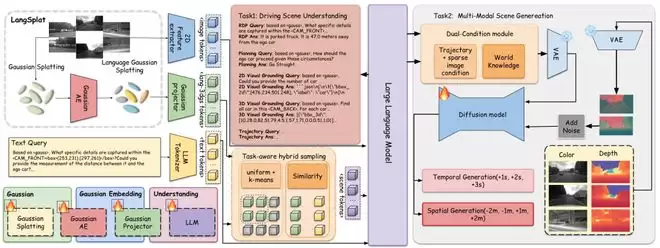
第一步是 Language-enhanced 3D Gaussian Tokenizer。传统的 3D Gaussian primitive 通常关注位置、不透明度、尺度、旋转这些几何和外观属性。GaussianDWM 在此基础上加入了语言特征,让每个 Gaussian primitive 不再只是一个可渲染的小单元,而成为一个携带语义信息的 3D token。
这些语言特征来自 CLIP,并且继承了 SAM 提供的层次语义。为了控制存储和计算开销,方法中还用了 scene-wise language autoencoder,把原本 512 维的 CLIP feature 压缩到了 3 维。这么做的目的,不是把语言信息变成一个孤立的附加项,而是让语义真正落在 3D 场景中的空间位置上。
不过,构建出高斯场只是第一步。LLM 并不能直接处理一个密集的 3D Gaussian 场,所以 GaussianDWM 又引入了 Gaussian Projector 和 task-aware sampling。Projector 负责把位置、opacity、scale、rotation 以及 language feature 映射到 LLM 的 embedding space;sampling 则根据具体任务,从密集的高斯中挑出更合适的 tokens。
在全局理解任务中,模型使用 uniform sampling 和 top-k sampling 来保留场景的整体信息;在 2D/3D visual grounding 任务中,采样会参考 text query 与 Gaussian feature 的 similarity,从稠密高斯中挑出更相关的部分。在主实验中,模型从场景里采样了 4096 个 Gaussian tokens 输入 LLM。这个数量本身也说明了一个现实的取舍:3D 表示足够丰富,但必须变得紧凑,语言模型才有可能稳定地使用它。
理解结果反过来参与生成
GaussianDWM 的另一个关键设计,是没有把理解和生成完全切开。生成模块采用 dual-condition generation,同时接收 low-level condition 和 high-level world knowledge。前者主要来自 sparse RGB/depth condition,负责约束纹理和几何;后者来自 LLM 提取出的 world knowledge,提供更高层的语义和空间先验。
这种设计与驾驶场景中的多层次约束是匹配的。low-level condition 主要由 sparse RGB/depth 提供,用于约束局部纹理和几何结构,但对目标关系、空间布局和语义一致性的表达能力有限。high-level world knowledge 来自 LLM 的场景理解结果,能够为生成过程补充语义和空间先验。GaussianDWM 将二者结合,用 low-level condition 保持视觉细节和几何约束,用 high-level world knowledge 强化场景关系与语义一致性,从而服务空间生成、时间生成和 RGB-D 生成。
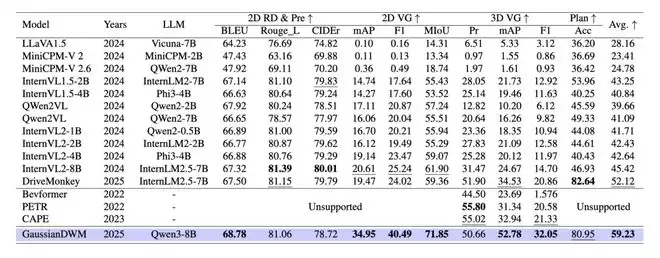
在 NuInteract 上,3D Gaussian 带来更强的场景理解
为了验证场景理解能力,GaussianDWM 在 NuInteract 上进行了评估。相比只依赖传统视觉或语言特征的做法,3D Gaussian 给模型提供了更加明确的空间结构,也让视觉定位任务获得了明显收益。
从主表结果看,GaussianDWM 的平均指标达到 59.23,高于 DriveMonkey 的 52.12。在 2D visual grounding 上,mAP 从 19.47 提升到 34.95;在 3D visual grounding 上,mAP 从 34.53 提升到 52.78。这组结果直接说明,高斯表示不只是对渲染和生成有用,它也能帮助 LLM 更好地理解 3D 驾驶环境。
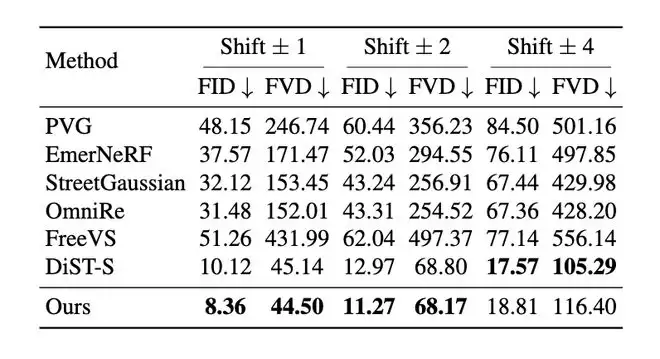
在 nuScenes 上,统一表示也服务 RGB-D 空间生成
多模态生成部分主要在 nuScenes 上验证。GaussianDWM 关注的不只是 RGB 图像,还包括 RGB-D generation,这使得结果需要同时面对外观质量和空间几何的一致性。
在空间生成任务中,当视角位移为 ±1m 时,GaussianDWM 的 FID/FVD 为 8.36/44.50;当视角位移为 ±2m 时,FID/FVD 为 11.27/68.17。与 PVG、StreetGaussian、DiST-S 等方法相比,GaussianDWM 在小到中等位移下取得了更低的 FID/FVD。对于自动驾驶场景来说,这类结果的意义在于:模型不是单纯生成一张新图,而是在尽量维持场景 3D 关系的前提下完成视角变化。
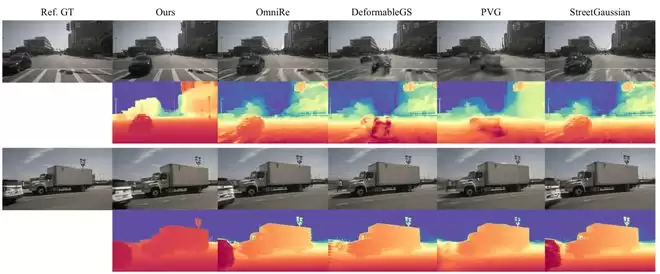

消融实验:Gaussian、采样和 World Knowledge 缺一不可
论文中的消融实验进一步解释了每个设计的作用。去掉 Gaussian 后,模型平均指标为 53.32;加入 Gaussian 并使用 similarity sampling 后,平均指标提升到 59.23。这个差距说明,3D Gaussian 在理解任务中提供的不是可有可无的额外信息,而是能够改变模型输入质量的核心表示。
在生成任务上,dual-condition 的作用也比较清楚。只使用 low-level condition 时,±1m 下的 FID 为 10.12;加入 high-level world knowledge 后,FID 降到 8.36。更大的视角变化下,world knowledge 的贡献更加明显:在 ±4m 条件下,FID 从 21.79 降到 18.91。换句话说,当低层视觉条件不足以覆盖更大空间变化时,高层语义和空间先验开始发挥更重要的作用。

视频展示:把生成能力放到动态场景中看

Overall visual walkthrough

Spatial generation

Temporal generation

Future prediction grid

Long-sequence prediction
结语:统一驾驶世界模型,需要可生成,也需要可查询
GaussianDWM 的核心观点可以概括为一句话:自动驾驶世界模型不应该只追求生成未来画面,也需要形成一个能被理解、被查询、被用于定位和规划的 3D 世界表示。3D Gaussian 在这里扮演了连接器的角色——它把几何、外观和语言语义放到同一个场景表示中,再通过 task-aware sampling 和 Gaussian Projector 送入 LLM。
在这个框架下,LLM 不只是回答问题,它还会提取 world knowledge feature,并把理解结果继续交给生成模块使用。NuInteract 和 nuScenes 上的结果表明,这种统一表示同时改善了场景理解和多模态生成。对于自动驾驶世界模型来说,这可能比单纯追求更清晰的视频更重要:模型最终要服务的是一个会移动、会交互、需要解释当前世界并预测未来世界的系统。