一、DSpark 是什么?揭秘DeepSeek与北大联合开源推理加速框架
DSpark 项目,是由 DeepSeek(深度求索) 与 北京大学 联合推出的开源大模型推理加速框架,发布于2026年6月27日。它基于推测解码(Speculative Decoding)技术,完整代码托管在 DeepSpec 开源仓库,采用 MIT 协议,允许自由使用、修改和商用,无任何限制。
传统大模型生成文本时采用逐Token自回归方式,高并发下生成速度骤降,GPU利用率低下,服务响应如同“挤牙膏”。DSpark 的解法独具匠心——半自回归草稿生成 + 置信度动态调度,取代了此前常见的 MTP-1、Eagle3、DFlash 等推测解码方案。其核心优势在于:不改模型输出质量,不添硬件成本,即能显著提升单用户生成速度与服务器整体吞吐量。目前已在 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的线上服务中稳定运行,同时兼容 Qwen、Gemma 等主流开源大模型。
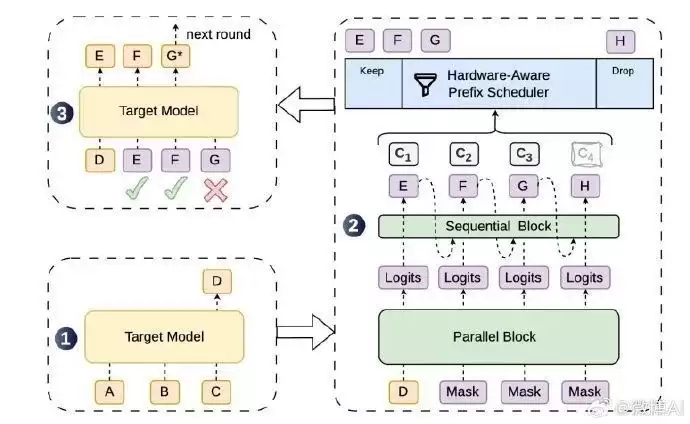
四、DSpark典型应用场景与落地价值
企业AI对话在线服务
面向C端用户的聊天机器人或智能客服,高峰期多人并发请求时最怕卡顿与逐字输出。部署 DSpark 后,相同 GPU 硬件可承载更多在线用户,有效降低云服务算力成本,提升用户体验。代码生成与编程助手
代码补全、IDE 智能插件等场景下,长代码批量生成速度提升显著,开发者无需长时间等待渲染结果。同时,DSpark 深度适配 Qwen-Coder、DeepSeek-Coder 等代码模型,兼容性有保障。长文本批量生成业务
公文写作、小说生成、知识库问答、文档摘要等需要输出长序列的场合,DSpark 单次可批量输出大量有效 Token,整体处理效率翻倍提升。本地私有化部署推理
政企单位在单机或小集群上运行私有化大模型时,无需急于购置新显卡。直接集成 DSpark 框架即可充分挖掘现有硬件潜力,大幅降低私有化落地的硬件预算压力。AI原生API平台
大模型 API 服务商接入 DSpark 后,接口并发承载上限明显提高,单 Token 推理成本下降,平台盈利空间扩大,客户体验同步优化——实现双赢。
五、DSpark使用方法详解
5.1 方式一:直接调用DeepSeek官方优化模型API
最简便的方式,无需自行部署底层框架。直接调用 DeepSeek-V4-Flash-DSpark 或 DeepSeek-V4-Pro-DSpark 的官方 API,平台已内置加速逻辑,开箱即用,适合快速验证与原型开发。
5.2 方式二:HuggingFace权重本地加载部署
首先克隆官方 DeepSpec 开源仓库:
git clone https://github.com/deepseek-ai/DeepSpec安装项目依赖环境,运行环境配置脚本;
从 HuggingFace 下载对应的 DSpark 优化权重(支持 DeepSeek-V4 / Qwen3 / Gemma 系列);
启动推理脚本,启用 DSpark 推测解码模式,兼容 vLLM、Transformers 等主流推理后端。
5.3 方式三:自有模型迁移适配
使用仓库中的训练脚本,基于自有基础大模型训练专属的半自回归草稿模型;
配置置信度调度参数与硬件负载阈值;
集成到自有推理服务引擎中,将原生自回归解码逻辑替换为 DSpark 解码流程;
运行评估脚本,确认输出质量与加速效果达标后,即可上线。
5.4 生产集群部署
多卡 GPU 集群可开启分布式硬件调度。调度器跨卡采集负载数据,统一分配草稿验证任务。8卡及以上的企业级推理集群尤其适合采用这种部署方式,充分发挥并行能力。
六、常见问题解答(FAQ)
Q:DSpark 和 Apache Spark/PySpark 是同一款工具吗?
A:完全不同。Apache Spark 是大数据分布式计算引擎,用于离线数据处理;DSpark 是大模型推理加速框架,专为 LLM 文本生成设计。二者分属不同领域,无任何交集。
Q:DSpark 是否会改变大模型输出内容,导致更多幻觉?
A:不会。官方论文与线上实测均证实,DSpark 仅优化解码计算流程,不改变模型权重或文本生成逻辑。输出分布与原生模型完全一致,幻觉与逻辑错误概率未增加。
Q:低配单机显卡能否运行DSpark?
A:基础测试可运行,但若要实现生产级高并发,建议单卡显存至少 24G。百亿参数以上大模型推荐多卡部署,低显存设备会限制单次草稿生成长度,加速效果有所折扣。
Q:除DeepSeek自家模型外,还有哪些开源模型支持DSpark?
A:目前官方完整适配 Qwen3 全系列(4B/8B/14B)和 Gemma4 系列。其他开源 LLM 可通过内置训练脚本自主适配,无强制模型限制。
Q:DSpark开源协议是否支持商用?
A:项目整体采用 MIT 协议,企业可商用、修改框架代码、二次封装,无版权收费限制,仅需保留原始开源声明即可。
Q:部署DSpark后,单用户速度一定会提升60%以上吗?
A:提速幅度取决于任务类型、并发量与硬件配置。日常对话、短文本场景基本可达此上限;复杂数学推理、极低置信度输入场景下提升幅度略小,但整体性能仍优于传统推测解码方案。
Q:使用DSpark需要重新训练主大模型吗?
A:不需要。主模型权重无需改动,只需配套训练一个轻量化的草稿模型即可。训练算力消耗远低于主模型预训练,成本非常可控。
七、相关链接与资源
GitHub官方开源主仓库:https://github.com/deepseek-ai/DeepSpec
DSpark官方技术论文PDF:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
HuggingFace优化权重下载地址:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark
DeepSeek官方主站:https://www.deepseek.com/
八、总结与核心优势
DSpark 是 DeepSeek 联合北大推出的通用型大模型推理加速开源框架。其核心创新在于半自回归草稿生成与置信度硬件调度,直接解决了传统推测解码中算力浪费、并发卡顿、提速有限等长期痛点。框架深度适配自家 DeepSeek-V4 系列,同时兼容 Qwen、Gemma 等主流开源模型,无需增加硬件成本,亦不损失输出质量,即可显著提升单用户生成速度与系统吞吐。配套的训练、部署、评估工具链完整,MIT 开源协议足够宽松。从 AI 对话、代码生成、长文本生产到私有化推理,多种场景均可落地——对企业和开发者而言,DSpark 是一个低成本、高稳定性的线上推理加速优选方案。