DeepSeek-V3 悄悄更新到了 0324 版本,官网却一点动静都没有。这事儿多少有点反常——模型权重已经上传到了 Hugging Face 和魔塔社区,但官网新闻栏里最新的动态还是 DeepSeek R1,连个 README 都没写,更别说任何官方介绍了。
先梳理几个关键点:
模型权重已经开放下载,但没有任何更新说明。从配置文件来看,新版本和旧版的架构参数完全一致——依然是 256 个专家的 MoE 架构,训练方式没有改动。这意味着模型的基础设计没变,更新的重点很可能在数据、训练细节或者微调策略上。
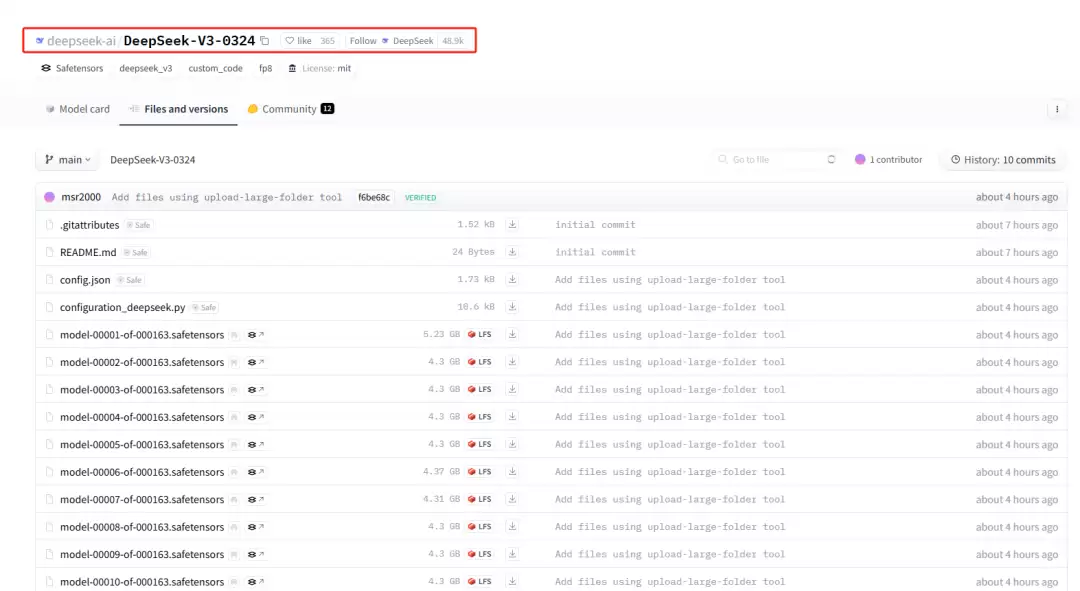
为什么说“悄咪咪”
官网没有任何公告,只在几小时前上传了权重文件。最新新闻还停留在 R1 发布时。而且,模型页面没有 README,没有更新日志,什么都没说。
从配置文件来看,两个版本的参数一模一样——hidden_size 7168、intermediate_size 18432、num_hidden_layers 61、num_attention_heads 128,所有 MoE 相关参数(n_routed_experts=256、num_experts_per_tok=8 等)都没变。所以训练方式和模型结构没有调整,更新的内容应该集中在下游适配或推理优化上。
{
"architectures": [
"DeepseekV3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"auto_map": {
"AutoConfig": "configuration_deepseek.DeepseekV3Config",
"AutoModel": "modeling_deepseek.DeepseekV3Model",
"AutoModelForCausalLM": "modeling_deepseek.DeepseekV3ForCausalLM"
},
"aux_loss_alpha": 0.001,
"bos_token_id": 0,
"eos_token_id": 1,
"ep_size": 1,
"first_k_dense_replace": 3,
"hidden_act": "silu",
"hidden_size": 7168,
"initializer_range": 0.02,
"intermediate_size": 18432,
"kv_lora_rank": 512,
"max_position_embeddings": 163840,
"model_type": "deepseek_v3",
"moe_intermediate_size": 2048,
"moe_layer_freq": 1,
"n_group": 8,
"n_routed_experts": 256,
"n_shared_experts": 1,
"norm_topk_prob": true,
"num_attention_heads": 128,
"num_experts_per_tok": 8,
"num_hidden_layers": 61,
"num_key_value_heads": 128,
"num_nextn_predict_layers": 1,
"pretraining_tp": 1,
"q_lora_rank": 1536,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64,
"quantization_config": {
"activation_scheme": "dynamic",
"fmt": "e4m3",
"quant_method": "fp8",
"weight_block_size": [128, 128]
},
"rms_norm_eps": 1e-06,
"rope_scaling": {
"beta_fast": 32,
"beta_slow": 1,
"factor": 40,
"mscale": 1.0,
"mscale_all_dim": 1.0,
"original_max_position_embeddings": 4096,
"type": "yarn"
},
"rope_theta": 10000,
"routed_scaling_factor": 2.5,
"scoring_func": "sigmoid",
"seq_aux": true,
"tie_word_embeddings": false,
"topk_group": 4,
"topk_method": "noaux_tc",
"torch_dtype": "bfloat16",
"transformers_version": "4.46.3",
"use_cache": true,
"v_head_dim": 128,
"vocab_size": 129280
}
训练方式没有变化,依然是 256 个专家的 MoE 架构。具体的更新内容目前只能等官方进一步通知。
有人发现官网其实已经更新了
如果关掉联网搜索和 DeepSeek R1 的选项,直接用的就是最新版的 V3。我们试了一下,问版本号和知识库时间,回答显示知识库截止到 2024 年 7 月。之前的 V3 版本也是这个时间点,所以知识库本身没有变化。
各大公司可以开始替换了
模型权重已在 Hugging Face 和魔塔社区开放下载,可以直接用于推理或微调。如果手头有部署环境,现在就能拿来试试。
最后
静待官方发布评测结果,看看具体在哪些方面有飞跃。之前的 DeepSeek-V3 已经能和 GPT-4o、Claude-3.5-Sonnet 打平手,这次更新后,能不能直接比肩 Claude-3.7-Sonnet?这是最让人期待的点。